Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering
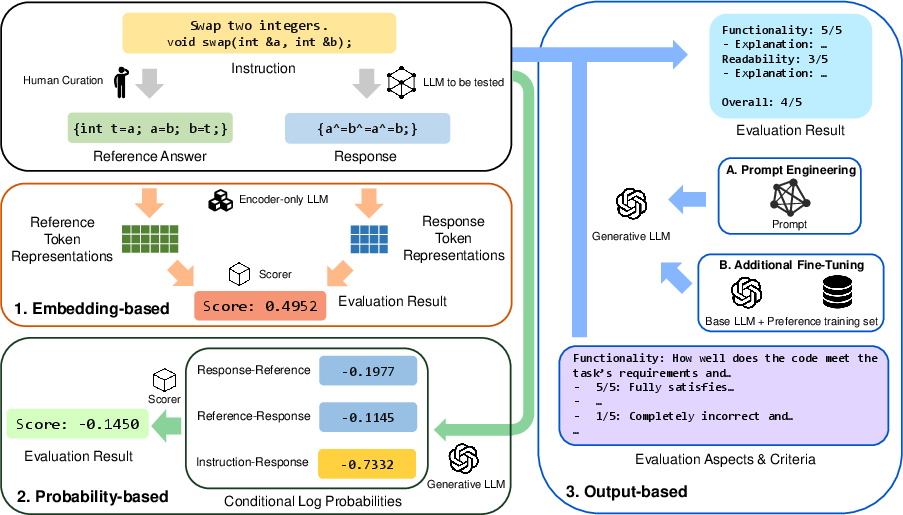
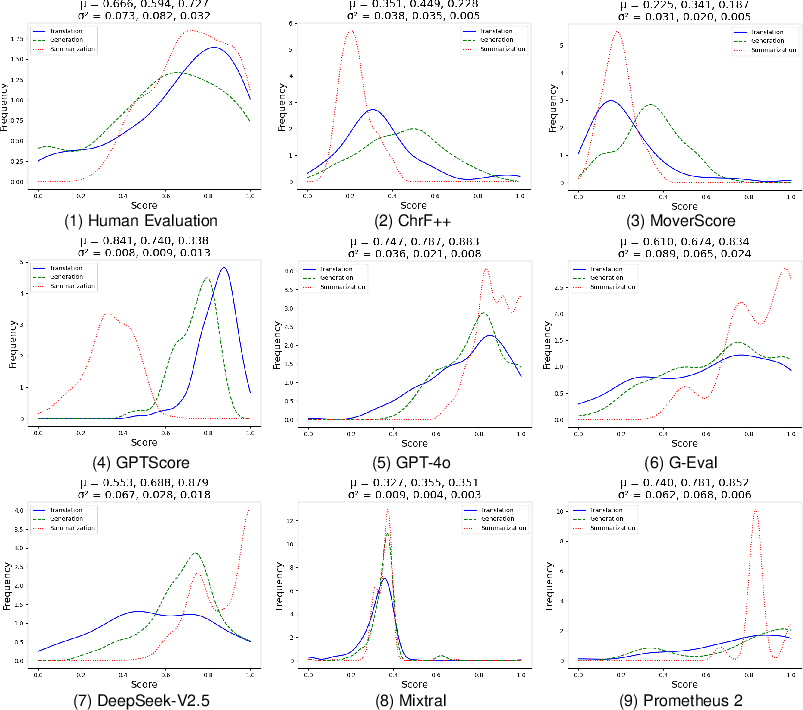
Abstract: Recently, LLMs have been deployed to tackle various software engineering (SE) tasks like code generation, significantly advancing the automation of SE tasks. However, assessing the quality of these LLM-generated code and text remains challenging. The commonly used Pass@k metric necessitates extensive unit tests and configured environments, demands a high labor cost, and is not suitable for evaluating LLM-generated text. Conventional metrics like BLEU, which measure only lexical rather than semantic similarity, have also come under scrutiny. In response, a new trend has emerged to employ LLMs for automated evaluation, known as LLM-as-a-judge. These LLM-as-a-judge methods are claimed to better mimic human assessment than conventional metrics without relying on high-quality reference answers. Nevertheless, their exact human alignment in SE tasks remains unexplored. In this paper, we empirically explore LLM-as-a-judge methods for evaluating SE tasks, focusing on their alignment with human judgments. We select seven LLM-as-a-judge methods that utilize general-purpose LLMs, alongside two LLMs specifically fine-tuned for evaluation. After generating and manually scoring LLM responses on three recent SE datasets of code translation, code generation, and code summarization, we then prompt these methods to evaluate each response. Finally, we compare the scores generated by these methods with human evaluation. The results indicate that output-based methods reach the highest Pearson correlation of 81.32 and 68.51 with human scores in code translation and generation, achieving near-human evaluation, noticeably outperforming ChrF++, one of the best conventional metrics, at 34.23 and 64.92. Such output-based methods prompt LLMs to output judgments directly, and exhibit more balanced score distributions that resemble human score patterns. Finally, we provide...

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.