- The paper demonstrates that reinforcement learning significantly boosts model performance, with OpenAI o1 achieving a CodeForces rating of 1673 (89th percentile).
- The paper explains that tailoring models—such as the specialized o1-ioi—improves competitive outcomes through additional RL training and sophisticated test-time strategies like problem decomposition.
- The paper reveals that advanced models like o3, trained end-to-end with reinforcement learning, outperform specialized heuristics, reaching gold medal thresholds in IOI competitions.
Competitive Programming with Large Reasoning Models
Introduction
The paper "Competitive Programming with Large Reasoning Models" (2502.06807) explores the application of reinforcement learning to improve the performance of LLMs in competitive programming. The research focuses on comparing general-purpose reasoning models, OpenAI o1 and its successor o3, with a specialized variant, o1-ioi, designed for the International Olympiad in Informatics (IOI). The findings demonstrate the effectiveness of scaling reinforcement learning for achieving superior performance without relying on domain-specific inference strategies.
OpenAI o1 Model
OpenAI o1 was developed to handle complex reasoning tasks through reinforcement learning. This model employs a methodical approach by generating a chain of thought internally before delivering solutions, much like how a human breaks down difficult problems. It further enhances its capabilities by testing generated code, iteratively refining solutions to meet correctness criteria.
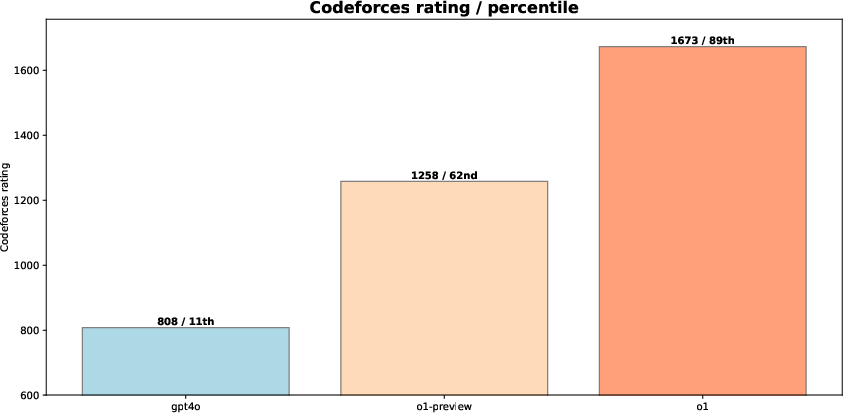
Figure 1: Comparing reasoning LLMs OpenAI o1-preview and o1 to gpt-4o on CodeForces.
The effectiveness of o1 is highlighted in competitive programming platforms like CodeForces, where it achieved a significant performance boost compared to non-reasoning LLMs like gpt-4o. The results in Figure 1 illustrate the substantial improvement due to reinforcement learning, with o1 reaching a rating of 1673 (89th percentile) on CodeForces.
Specialized Model: o1-ioi
The paper extends o1's capabilities by introducing o1-ioi, specifically tailored for the 2024 IOI. The model incorporates both additional reinforcement learning focused on coding tasks and sophisticated test-time strategies. These strategies include problem decomposition into subtasks and a clustering-based approach for solution selection, maximizing score efficiency in the IOI's scoring system.
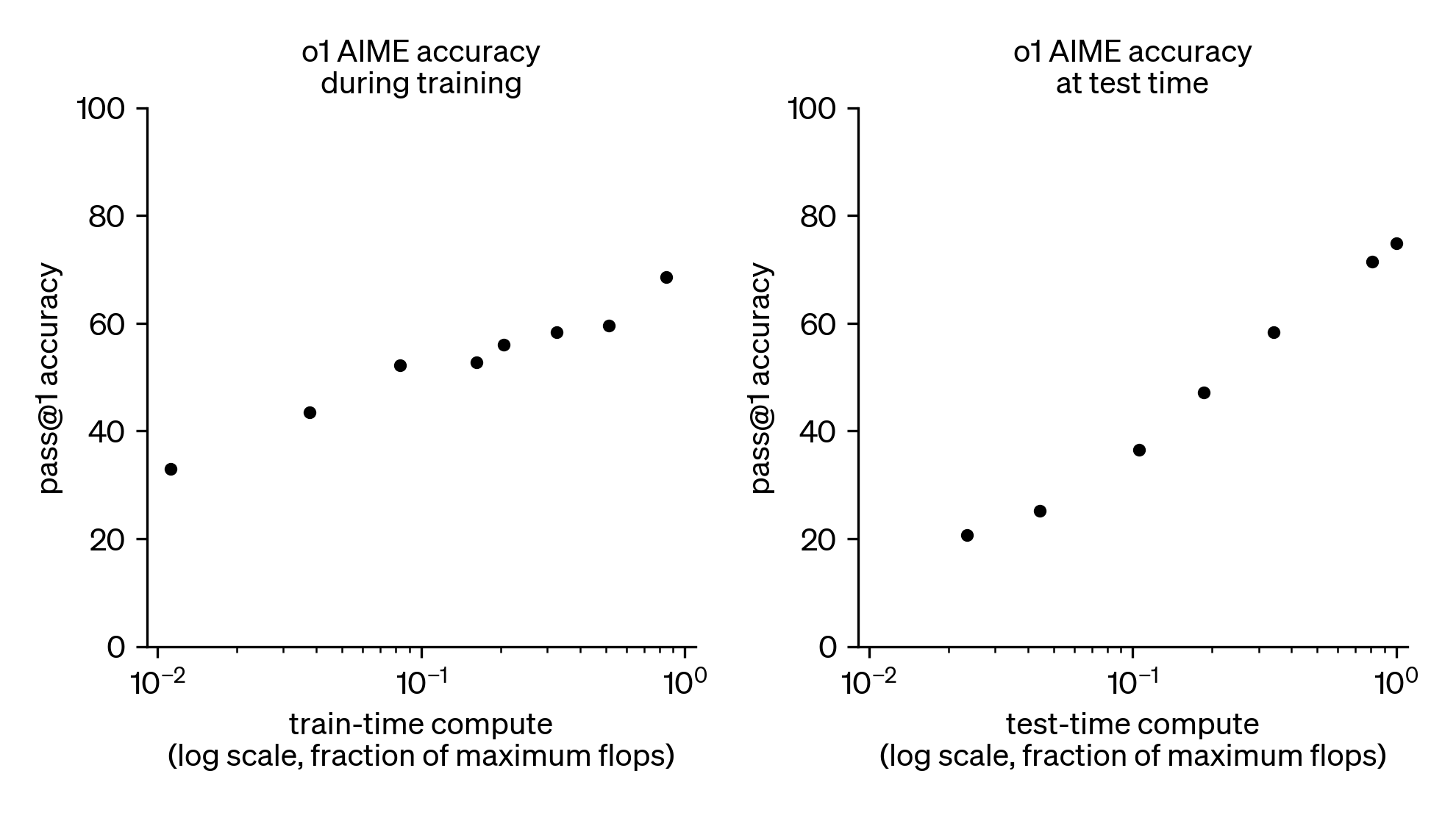
Figure 2: Additional RL training and additional test-time compute improves competitive mathematics performance.
Figure 2 shows the influence of increased RL training and extended test-time computing on competitive performance, underlining how these aspects significantly enhance results beyond what traditional LLM pretraining offers.
Advancements with OpenAI o3
Following the success of o1-ioi, the research advances with the o3 model, which further pushes the boundaries of AI reasoning capabilities. Notably, o3 achieves competitive results on CodeForces without relying on human-engineered test-time strategies.
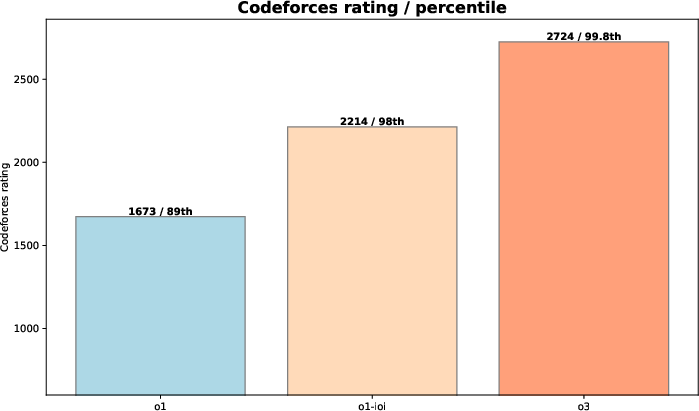
Figure 3: Performance of OpenAI o3 on the CodeForces benchmark.
Figure 3 demonstrates o3's performance leap, achieving a higher rating than both o1 and o1-ioi, reflecting its ability to tackle complex algorithmic problems with greater reliability.
Figure 4: o3 testing its own solution. This reflects a sophisticated reasoning strategy that partially implements the hand-designed test-time strategy used for o1-ioi in IOI 2024.
The advanced reasoning strategies that emerged during o3's training, such as generating brute-force solutions for verification, showcase its independent capability to enhance solution reliability—a hallmark of end-to-end reinforcement learning.
The performance of o1-ioi in the IOI 2024 elucidates the potential of specialized AI training and strategies. The model's participation yielded a substantial score with further improvements under relaxed submission constraints, demonstrating the effectiveness of its problem-solving strategy.
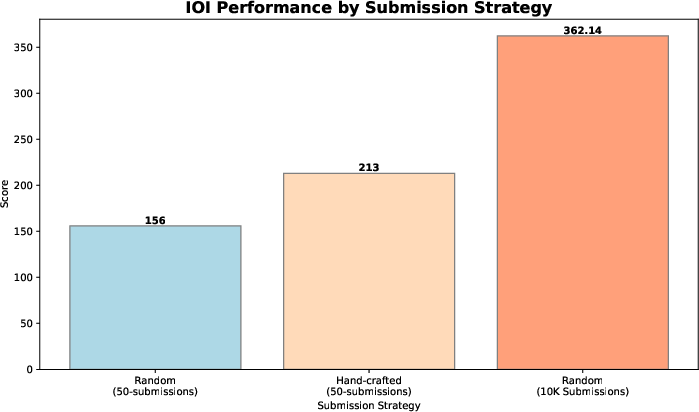
Figure 5: Performance of o1-ioi competing at IOI 2024.
The paper reveals o1-ioi's ability to achieve a gold medal threshold under competitive conditions, reinforcing the model's potential for reasoning in structured domains.
In contrast, o3's performance in retrospective evaluations underscores the power of large-scale RL training to surpass these results without specialized heuristics.
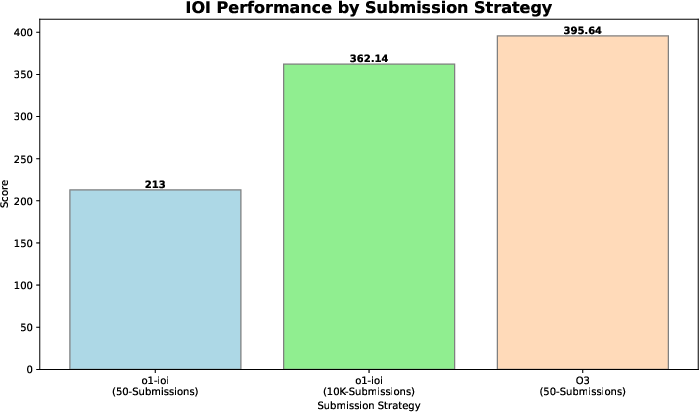
Figure 6: IOI 2024 scores under different submission strategies. Even without human-engineered heuristics or relaxed submission limits, o3 outperforms o1-ioi and surpasses the gold threshold with just 50 submissions.
Real-World Coding Evaluations
Beyond competitive programming, the paper evaluates LLM performance on real-world coding tasks, demonstrating the transferability of reasoning enhanced by RL in practical scenarios like software engineering. Evaluations on datasets such as HackerRank Astra and SWE-bench verified emphasize how such reasoning advancements extend to solving real-world software challenges.
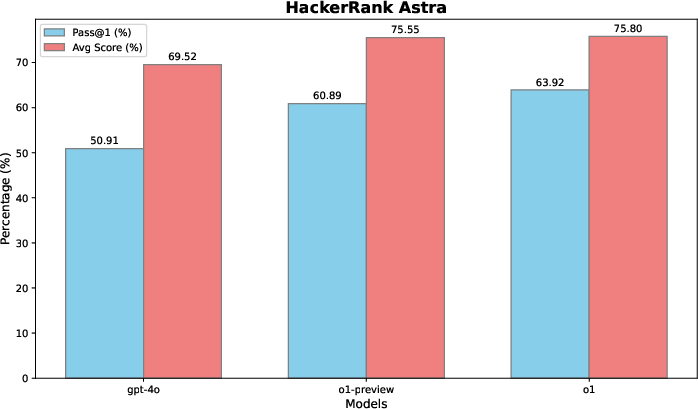
Figure 7: HackerRank Astra evaluation.
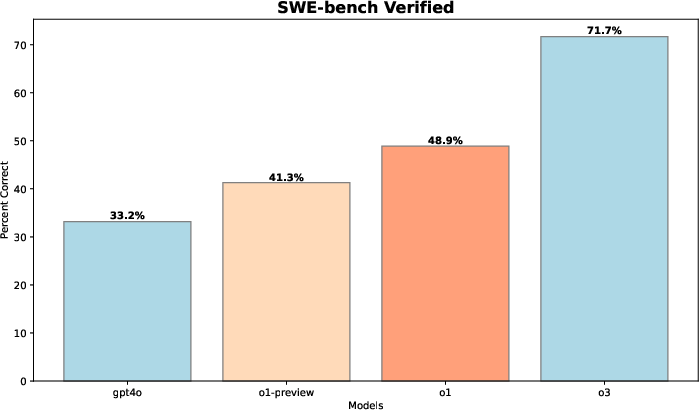
Figure 8: SWE-bench evaluation.
Conclusion
The research outlined in this paper asserts that reinforcement learning is a robust approach to improving reasoning models in AI. The enhancements observed in models like o1 and o3 across competitive programming and real-world coding tasks underscore the versatility and effectiveness of scaling RL training. The findings suggest the potential of large reasoning models to set new benchmarks across various AI applications, including scientific exploration, software development, and mathematical problem-solving.