- The paper introduces a novel hybrid trading agent that integrates LLM-derived recommendation and risk scores with reinforcement learning to enhance decision-making and risk management.
- The methodology utilizes PPO and CVaR-PPO algorithms augmented by LLM insights from financial news data, showing improved cumulative returns with longer training durations.
- Results indicate that extended training and calibrated LLM infusion are critical to surpass benchmarks like the Nasdaq 100, underscoring model-specific sensitivities to risk adjustments.
FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents
This essay provides an authoritative summary and analysis of the research paper "FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents" by Benhenda, which explores the integration of LLMs with reinforcement learning (RL) to enhance stock trading agents. The paper introduces a novel approach to algorithmic trading by incorporating financial news-derived signals into RL frameworks, enhancing both decision-making and risk management capabilities.
Introduction
The integration of alternative data sources, such as financial news, and effective risk management are often overlooked in automated trading agents leveraged through RL. Addressing these gaps, FinRL-DeepSeek presents a hybrid trading agent that utilizes LLMs for processing financial news data to improve trading strategies. The paper highlights the implementation of two critical LLM-derived scores: a trading recommendation score and a risk assessment score, which are integrated into the RL agents' training process.
Methodology
Data and LLM Prompts
The study utilizes the FNSPID dataset, comprising 15.7 million time-aligned financial news articles spanning from 1999 to 2023. A representative subset of 2 million records is selected to balance data depth and computational cost. LLMs such as DeepSeek V3, Qwen 2.5, and Llama 3.3 are employed to extract insights using predefined prompts for stock recommendations and risk assessment.
Trading Algorithms
Reinforcement Learning Agents
- Proximal Policy Optimization (PPO): Defined by a clipped surrogate objective, PPO is employed to ensure stable policy updates in trading actions.
- Conditional Value at Risk-Proximal Policy Optimization (CVaR-PPO): This variant incorporates a risk constraint to penalize high-risk trajectories, extending the stability of PPO by optimizing the trading strategy under potential financial risk.
LLM-Infused Trading Mechanisms
- LLM-Infused PPO and CVaR-PPO: The modifications involve computing stock-specific recommendation scores (Sf) and risk assessment scores (Rf) to adjust the actions and returns considered by the trading algorithms. These scores are dynamically applied to amplify or dampen trading actions based on their positive or negative indications, thus shaping action selection and risk evaluation processes.
Results
Early Stopping and Long-Term Training Outcomes
The efficacy of the LLM-enhanced models was evaluated through extensive training and backtesting. With shorter training periods (400-500k steps), LLM-infused PPO demonstrated improvements in cumulative returns but did not outperform the Nasdaq 100 benchmark.
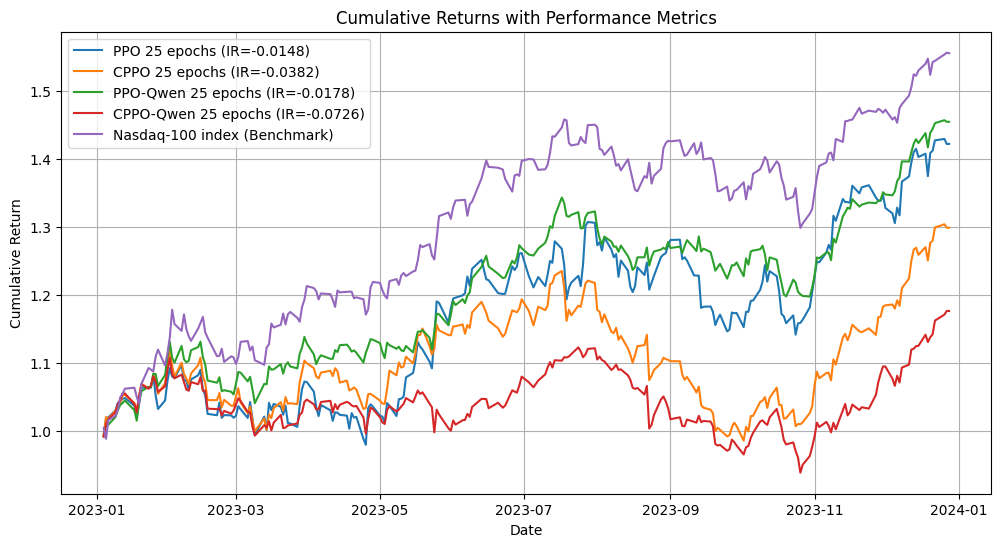
Figure 1: Backtesting after 500k training steps, 3 years training history, 1 year trading.
Interestingly, a longer training history significantly boosted the performance of both PPO and CVaR-PPO, highlighting training length as a critical factor in performance variance.
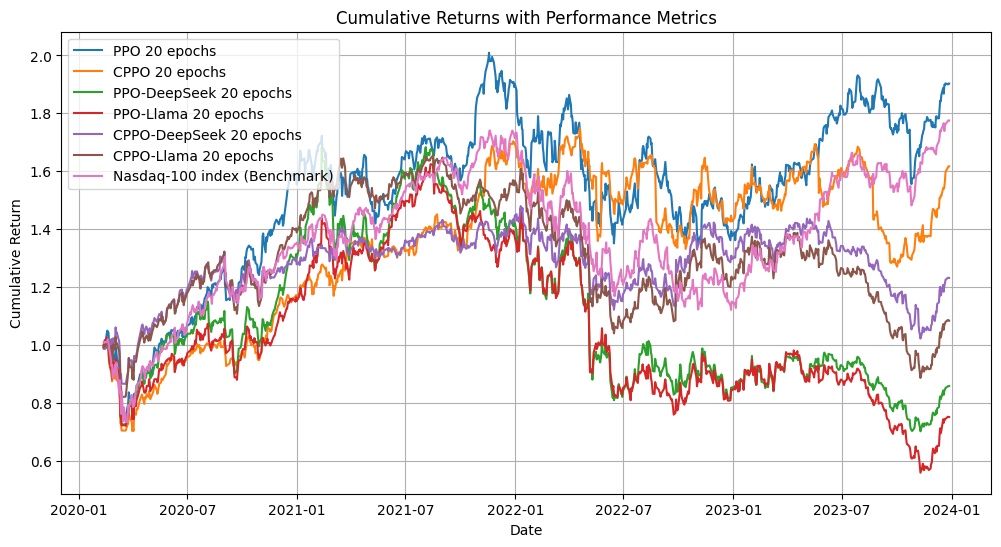
Figure 2: Backtesting after 400k training steps, 6 years training history, 3 years trading.
Advanced Training Implications and LLM Infusion Impact
Training to 2 million steps displayed that PPO and CPPO-DeepSeek models could surpass the Nasdaq 100 benchmark, suggesting that extended training enhances model adaptability and accuracy.
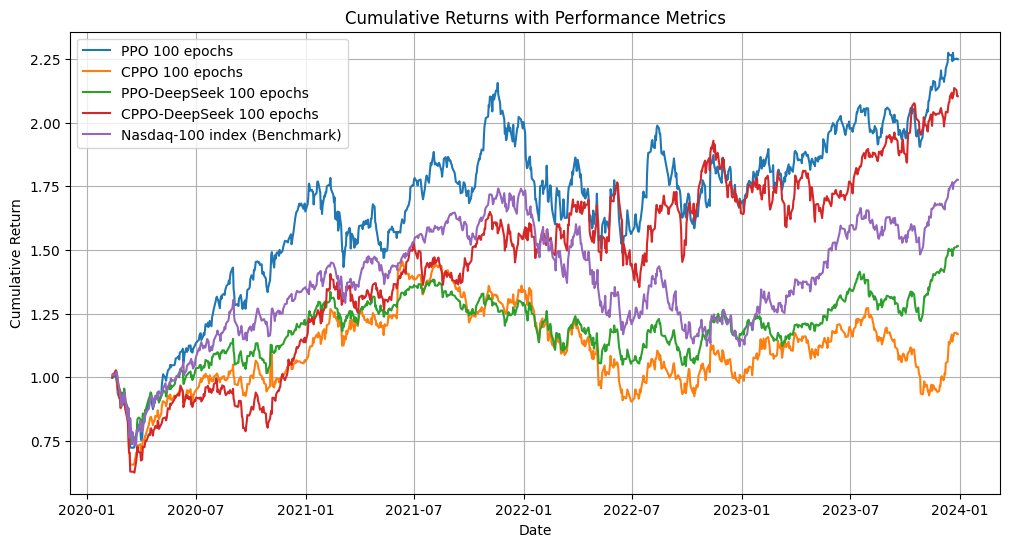
Figure 3: After training for 2 Million steps (100 epochs, 20k steps each) - Second run.
Regarding LLM infusion levels, stronger infusion degraded PPO performance but enhanced CPPO's outcomes, indicating model-specific sensitivities to LLM-driven adjustments.
Discussion
The study identifies LLM perturbation strength and training duration as critical factors impacting trading strategy effectiveness. It underscores the necessity of a finely-tuned approach to integrating LLMs in RL frameworks, emphasizing personalized design choices to align with varying market conditions. As demonstrated, LLM perturbations can meaningfully adjust action dynamics and risk management, opening new avenues for AI-driven trading reinforcement strategies.
Conclusion
FinRL-DeepSeek's approach marks a significant step towards advancing the integration of complex data into RL systems, providing actionable insights to optimize risk-sensitive trading agents. Going forward, optimizing memory usage, refining responsiveness to market events, and improving signal quality from financial news will be central to scaling and enhancing the trading agent's performance in real-world applications. Such developments hold promise in refining AI-driven market predictions and decision-making processes, potentially transforming financial markets' operational dynamics.