- The paper proposes a modality dominance score (MDS) to quantify and isolate monosemantic features in vision-language models.
- It introduces adaptations of Sparse Autoencoders and Non-negative Contrastive Learning to enhance feature sparsity and align modality-specific representations.
- The study demonstrates applications in bias analysis, adversarial attack defense, and controlled text-to-image generation using modality-specific interventions.
Multi-Faceted Multimodal Monosemanticity
Introduction to Multimodal Monosemanticity
The paper investigates the extraction and evaluation of monosemantic features within Vision-LLMs (VLMs) like CLIP. By introducing a Modality Dominance Score (MDS), the authors quantify the contribution of each modality (vision and language) to the final-layer features, which are then categorized into three groups: vision-dominant (ImgD), language-dominant (TextD), and cross-modal (CrossD). This categorization aids in understanding the model's behavior and its alignment with cognitive patterns seen in humans.
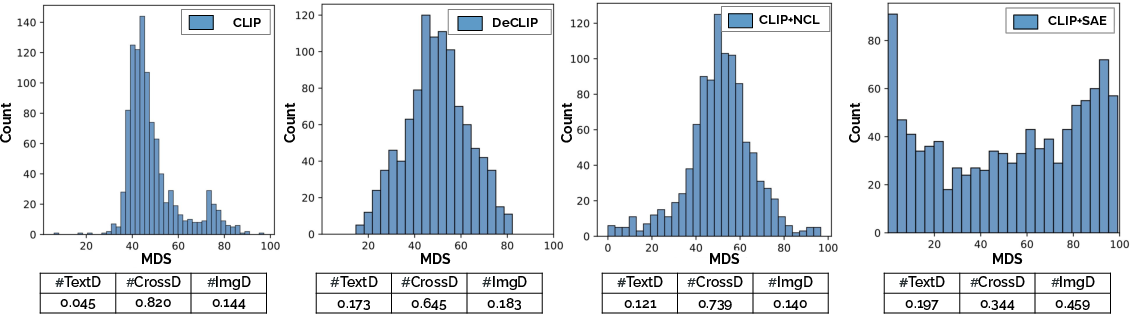
Figure 1: Modality Dominance Score (MDS) distributions of three feature categories for different VLMs.
Decoding Multimodal Monosemanticity
The authors adapt Sparse Autoencoders (SAEs) and Non-negative Contrastive Learning (NCL) models to improve the monosemanticity of features in VLMs. SAE models enhance feature interpretability through sparsity, targeting the most activated features, while NCL leverages a positive contrastive framework to align features non-negatively, facilitating interpretability across modalities.
Modality Specificity with MDS
MDS is introduced to assess the predominant modality influence on the model's features. By analyzing VLMs with MDS, the paper reveals that features show a bias towards image modality and that self-supervision in DeCLIP enhances modality separation.
Understanding Multimodal Monosemanticity
Quantitative and Qualitative Analysis
Monosemanticity is assessed using embedding similarity (EmbSim) and WinRate metrics. The results indicate enhanced interpretability for models employing SAE and NCL paradigms, showcasing clear modality distinctions.
(Figures 3 and 4)
Figures 3 & 4: Demonstrations of how ImgD and TextD features capture dominant visual and semantic concepts respectively.
Practical Implications
Gender Pattern Analysis
By selectively disabling ImgD and TextD features, the study shows their respective roles in gender identification tasks, uncovering modality-specific biases and stereotypes.
Adversarial Attack Defense
A key application explored is in defending multimodal systems against adversarial text injections. Aligning adversarial targets with modality-specific features enhances robustness, especially with TextD due to its profound semantic content.
Text-to-Image Generation Control
The study further applies feature control in text-to-image generation, illustrating how TextD and ImgD influence high-level semantic coherence and low-level visual detail in generated images.
Figure 2: New images generated with varying interventions in modality-specific features.
Conclusion
This research advances the understanding of feature monosemanticity in multimodal neural networks, proposing robust methods for feature extraction that align with human cognitive interpretation. The work demonstrates significant implications in bias reduction, adversarial robustness, and controllable image generation through modality-specific feature interventions. Future explorations may extend these methodologies across diverse architectures to further bridge gaps between human cognition and AI interpretations.