- The paper demonstrates that SAE-derived features do not provide a systematic performance advantage in probing LLM activations across diverse tasks.
- The evaluation rigorously compares SAE probes against robust baselines such as logistic regression, PCA, KNN, and attention-based pooling, highlighting baseline robustness.
- The study underlines that while SAE representations are interpretable, they fail to generalize under conditions like data scarcity, covariate shift, and label noise.
Authoritative Summary of "Are Sparse Autoencoders Useful? A Case Study in Sparse Probing"
Motivation and Scope
Sparse autoencoders (SAEs) have been increasingly leveraged in mechanistic interpretability to decompose LLM activations into monosemantic latent features. Despite their prominence, intrinsic evaluation metrics (e.g., reconstruction loss, feature monosemanticity) have dominated SAE research, leaving open questions about their pragmatic utility, particularly for downstream tasks where interpretability is presumed to enable better model control or explanation. This work rigorously studies whether SAE-derived features actually confer an advantage in linear activation probing, especially under regimes commonly encountered in real-world model analysis: data scarcity, class imbalance, label noise, and covariate shift.
Methodological Foundation
The paper utilizes probes trained on SAE latents and compares them against robust baselines, including logistic regression, PCA regression, KNN, XGBoost, and MLP, across more than 100 binary classification tasks drawn from diverse sources. Two LLMs are probed: Gemma-2-9B and Llama-3.1-8B, with SAE variants from Gemma Scope and Llama Scope. The primary evaluation metric is test AUC, and a "Quiver of Arrows" protocol selects the best-performing probe based on validation AUC in each regime, thereby avoiding test data leakage and emulating practitioner decision dynamics.
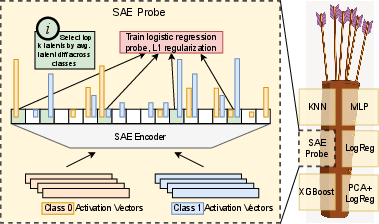
Figure 1: SAE probing protocol and ensemble evaluation (quiver of arrows) for robustness across probe choices.
Standard Conditions
In scenarios with balanced classes and ample training data, SAE probes consistently underperform relative to logistic regression directly applied to model activations and provide no substantial interpretability benefit over baselines when their performance is averaged across datasets.
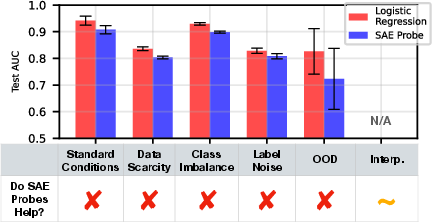
Figure 2: SAE probes underperform logreg baselines across datasets and regimes.

Figure 3: Incorporating SAEs into the probe ensemble results in a slight decrease in average performance.
Data Scarcity, Class Imbalance, and Label Noise
SAEs were hypothesized to yield an inductive bias more robust under difficult data regimes. However, empirical results show that SAE probes offer no meaningful advantage over baselines in any of these settings. Even when selected by the quiver, their test AUCs are systematically lower or indistinguishable from those of baselines.
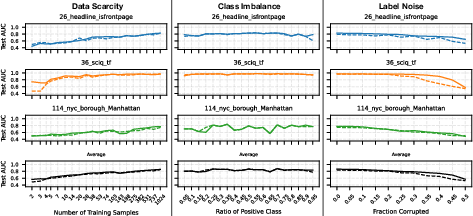
Figure 4: Probing performance in data scarcity, imbalance, and label noise; SAE quiver performance (dashed) fails to rise above baseline (solid).

Figure 5: Marginal AUC difference with SAE probes is null across all challenging regimes (95% CIs).
Covariate Shift
When tested for out-of-distribution robustness (OOD), SAE probes generalize poorly compared to logistic regression. Pruning latents deemed spurious via autointerp could marginally improve OOD performance, but SAE features themselves often lack cross-distribution stability, e.g., a latent highly predictive for English "living room" does not activate for translations.
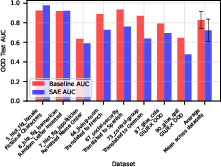
Figure 6: Logistic regression outperforms SAE probes in covariate shift scenarios.
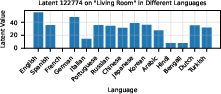
Figure 7: SAE latent 122774 demonstrates language specificity, failing to generalize on translation.
Multi-token Probing and Baseline Design
Prior claims of SAE probing superiority largely stem from multi-token pooling. When baseline probes are properly aggregated (e.g., via attention-based pooling), SAE probes no longer outperform, indicating that claimed advantages are illusory and contingent upon baseline weakness.
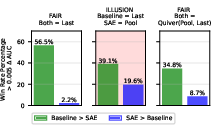
Figure 8: SAE probe win rate declines when pooled, attention-inspired baselines are introduced.
Interpretability Analysis
While SAEs do not provide a performance advantage, their latent representations are inherently decomposable and interpretable. Natural language autointerp on latents enables rapid identification of spurious correlations and dataset flaws, sometimes outperforming baseline classifiers, e.g., a monosemantic latent can be superior for diagnostic probing of mislabelled data (CoLA) and AI-vs-human text. However, in most cases, baseline probes are capable of uncovering these same issues, especially with infrastructural support.
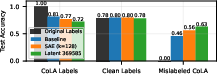
Figure 9: SAE latent 369585 outperforms a dense SAE probe and baseline logreg on mislabelled CoLA data.
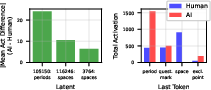
Figure 10: Latent activations differentiating AI-generated vs. human text correlate with syntactic tokens.
Architectural Trends in SAE Development
The study evaluates a spectrum of SAE architectures (ReLU, Gated, TopK, JumpReLU, BatchTopK, p-annealing, Matryoshka) to determine whether innovations yield probing improvements. Statistical analysis shows no robust, generalizable gain in probe performance with newer architectures; positive trends are slight and dominated by variance.
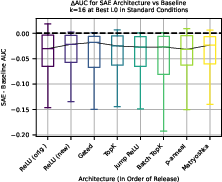
Figure 11: Recent SAE architectures yield a marginal uptick in performance, but variance predominates.
Replication on Llama-3.1-8B
Results generalized to Llama-3.1-8B: optimal probing layers are mid-model, but SAE probes again underperform or fail to improve on baselines, both in standard and challenging regimes.
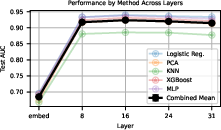
Figure 12: Optimal layer for baseline probing is mid-model in Llama-3.1-8B.
Figure 13: No improvement from SAE probes in Llama-3.1-8B on core regimes.
Practical and Theoretical Implications
This comprehensive evaluation reveals fundamental limitations in current SAE methodologies:
- The inductive bias of monosemantic SAE features does not translate to improved probe effectiveness, even under conditions expected to favor sparse representations.
- Prior positive results are attributable to insufficient baseline rigor and/or artifact-prone probing setups (e.g., pooling without matched baseline aggregation).
- SAE interpretability infrastructure (e.g., Neuronpedia autointerp) is a practical advantage, but baseline probes—when paired with comparable infrastructure—are similarly capable.
- Interpreter analysis can mislead, as proxies (e.g., test AUC, autointerp description fit) may mask latent gaps in robustness and generalization.
Prospective Directions
The results motivate further research in interpretability to develop and validate methods via downstream tasks with strong baseline comparisons. Future studies could target toy models with known ground-truth features or integrate advanced proxy metrics beyond reconstruction loss—aiming to directly assess concept fidelity and robustness. Optimization of SAE probing baselines, as demonstrated in recent work (e.g., feature binarization and full latent dimension probing), must be matched by equivalent baseline advancement. The field should critically evaluate the interpretability utility of dictionary learning and sparse representations beyond static, dataset-bound analysis.
Conclusion
Across a broad empirical landscape, sparse autoencoders as currently implemented do not yield a systematic or robust advantage for activation probing in LLMs. Their utility is not disproven for all interpretability tasks, but strong performance and interpretability claims must be contextualized with rigorous baseline methodology. The study contributes an essential datapoint for the interpretability community, emphasizing methodological rigor and highlighting the need for more comprehensive, robust task-driven evaluation.