- The paper demonstrates that PCA whitening transforms the SAE optimization landscape by aligning high sparsity with improved feature recovery.
- It shows that whitening enhances interpretability metrics significantly—with improvements up to 372% for causal feature isolation—while incurring slight fidelity losses.
- The study indicates that whitening provides a model-agnostic bias for disentangling features, particularly benefiting ReLU-based architectures over Top-K variants.
Data Whitening as a Catalyst for Interpretable Sparse Autoencoder Learning
Introduction
The study titled "Data Whitening Improves Sparse Autoencoder Learning" (2511.13981) rigorously examines the role of PCA whitening in enhancing sparse autoencoder (SAE) training, primarily for mechanistic interpretability of large neural models. SAEs are instrumental for extracting disentangled, human-interpretable features from the activations of LLMs, a necessity given the mixed and polysemantic nature of individual neurons. Historically, classical sparse coding methods utilized whitening as a standard preprocessing step, but it has not been widely adopted for modern SAE training pipelines. This work bridges that gap, providing both theoretical and empirical support for whitening’s utility in producing more interpretable latent representations.
Theoretical Analysis of Whitening's Impact on the Optimization Landscape
Whitening acts by decorrelating and equalizing the variance of input data, fundamentally altering the geometry of the optimization landscape encountered during SAE training. The authors construct a simulation framework to visualize the effects in a controlled 2D sparse coding setting. In unwhitened data, regions corresponding to high sparsity in solution space are misaligned with those yielding accurate feature recovery, leading to a rugged, anisotropic, and poorly conditioned landscape. Conversely, whitening yields a smooth, isotropic, and more convex-like basin where the objectives of sparsity and feature recovery coincide.
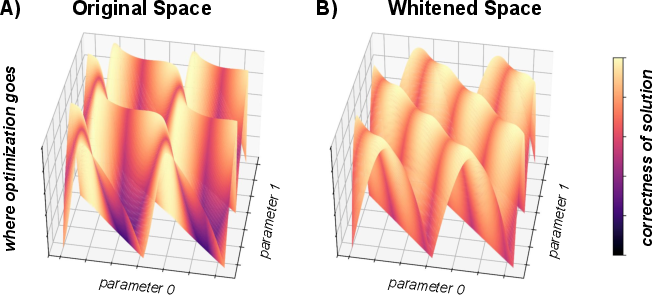
Figure 1: Whitening transforms the optimization landscape, aligning high sparsity regions with those of accurate feature recovery, thereby making the landscape isotropic and easier to optimize.
The simulation further demonstrates that, post-whitening, optimizing for sparsity naturally guides solutions toward interpretable features. The Hessian of the loss at optima exhibits improved conditioning, indicating robust convergence properties under gradient-based training schemes.
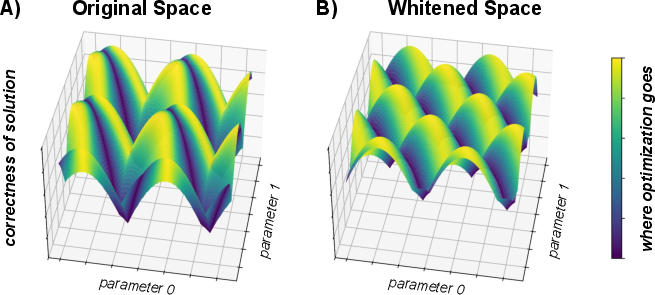
Figure 2: Complementary view showing that, post-whitening, regions of high sparsity directly overlap with optimal feature recovery, unlike the unwhitened case where these objectives can conflict.
Empirical Evaluation: Whitening's Effects on SAE Interpretability and Reconstruction
The experimental protocol leverages the SAEBench framework to benchmark both ReLU and Top-K SAE variants across distinct model architectures and dictionary widths. PCA whitening is incorporated as a preprocessing step—input activations from selected model layers are mean-centered and projected into a space with identity covariance before encoding.
ReLU SAE Results
Whitening induces robust improvements in interpretability metrics for ReLU SAEs:
- Sparse Probing (+7.15%): Enhanced accuracy of linear probes in diagnosing underlying concepts from encoded activations.
- Spurious Correlation Removal (SCR) (+54.03%): Marked capacity for disentangling confounding variables.
- Targeted Probe Perturbation (TPP) (+372.00%): Dramatic gains in causal feature isolation.
Accompanying these improvements are modest declines in reconstruction quality: CE Loss (-2.64%) and Explained Variance (-5.02%). Notably, the substantial interpretability gains challenge the conventional notion that optimal sparsity–fidelity trade-offs equate to maximal interpretability.

Figure 3: In ReLU architectures, whitening yields significant increases in Sparse Probing, SCR, and TPP while only modestly decreasing CE Loss and Explained Variance.
Top-K SAE Results
For Top-K SAEs, whitening robustly increases sparse probing accuracy (+7.30%) while leaving SCR and TPP metrics unchanged. Reconstruction metrics decrease slightly (CE Loss: -2.27%; Explained Variance: -5.22%), with statistical significance.

Figure 4: In Top-K architectures, whitening reliably boosts Sparse Probing, with little impact on SCR/TPP and minor reductions in reconstruction metrics.
Architectural Implications
The gains from whitening are most pronounced for ReLU-based architectures, suggesting that soft-sparsity constraints permit distributed and co-active feature learning that benefits disproportionately from improved conditioning and isotropy. For Top-K, the hard sparsity constraint truncates weaker activations, limiting the extent of disentanglement improvements possible through whitening.
Practical and Theoretical Implications
The results of this study have several implications:
- Interpretability Optimization: SAE training regimens focused on the reconstruction–sparsity frontier may miss the mark for interpretable feature discovery unless data whitening is included.
- Training Stability and Feature Disentanglement: Whitening provides an inductive bias for feature independence and causal disentanglement without any architectural or loss-function modification.
- Modality Generalization: Although the work focuses on middle layers of sub-2B LLMs, the principles may extend to other modalities (vision, audio) and model scales, warranting further investigation.
Fundamentally, whitening alters the optimization geometry, making sparse solutions more semantically meaningful and disentangled, even at the expense of slight reductions in fidelity. The study also highlights open avenues such as combining whitening with denoising and applying it across model layers or in conjunction with advanced SAE architectures.
Conclusion
This work demonstrates via theoretical modeling, simulation, and comprehensive benchmarking that PCA whitening transforms the SAE optimization landscape, yielding substantially more interpretable latent representations with only minor detriment to reconstruction fidelity. Whitening should be considered an essential preprocessing step for SAE training when interpretability is paramount. These findings challenge dominant paradigms linking sparsity–fidelity trade-offs with interpretability and underscore the importance of activation geometry in feature disentanglement. As the mechanistic interpretability community continues to evolve methodologies, whitening provides a principled, model-agnostic enhancement to latent feature extraction in large neural networks.