- The paper presents MP-SAE that unrolls matching pursuit into sparse autoencoders, achieving provable reconstruction monotonicity.
- MP-SAE outperforms shallow SAEs on MNIST by extracting more expressive and correlated features with fewer parameters.
- The iterative approach leverages residual-guided atom selection to build efficient hierarchical representations for enhanced interpretability.
Evaluating Sparse Autoencoders: From Shallow Design to Matching Pursuit
Introduction
Sparse Autoencoders (SAEs) have emerged as pivotal tools for interpretability by employing dictionary learning to extract sparse and meaningful features from largely nontransparent neural representations. The paper assesses the efficacy of SAEs in a constrained environment using the MNIST dataset, revealing that current architectures lean on quasi-orthogonality, limiting the extraction of correlated features. To advance beyond these limitations, the paper introduces a Multi-Iteration Sparse Autoencoder (MP-SAE) by unrolling a Matching Pursuit (MP) process. This approach promotes the residual-guided extraction of correlated features with provable reconstruction monotonicity as more atoms get selected.
Background and Theory
Sparse dictionary learning attempts to represent data as sparse combinations of learned basis vectors (atoms), essential across many scientific fields such as medical imaging, and image restoration. Traditional dictionary learning involves a bi-level optimization problem, focusing on estimating sparse codes and updating the dictionary iteratively. The introduction of unrolled iterative solutions into neural networks allows for fixed-complexity approximations, expediting convergence.
SAEs, particularly, are used to impose a sparse structure on latent representations. However, inherent limitations due to the implicit emphasis on quasi-orthogonal dictionaries restrict the extraction of coherent concepts. This motivates the exploration of MP techniques to disentangle and efficiently extract features even from coherent datasets.
Unrolling Matching Pursuit into MP-SAE
MP-SAE introduces an iterative inference mechanism that sequentially reduces residuals by adding atoms through a greedy selection. Each iteration selects the atom that aligns best with the current residual, orthogonally adjusting the reconstruction and residual. Theoretical underpinnings provide that these residuals maintain orthogonality with the selected atoms, and they decrease monotonically, converging to the orthogonal projection onto the dictionary's span.

Figure 1: Example of Sequential Reconstruction for k=10.
Experimental Results
The paper evaluates MP-SAE against various shallow SAEs using MNIST. MP-SAE is shown to produce more expressive representations, indicated by improved reconstruction accuracy at varying sparsity levels despite having fewer parameters due to weight tying.
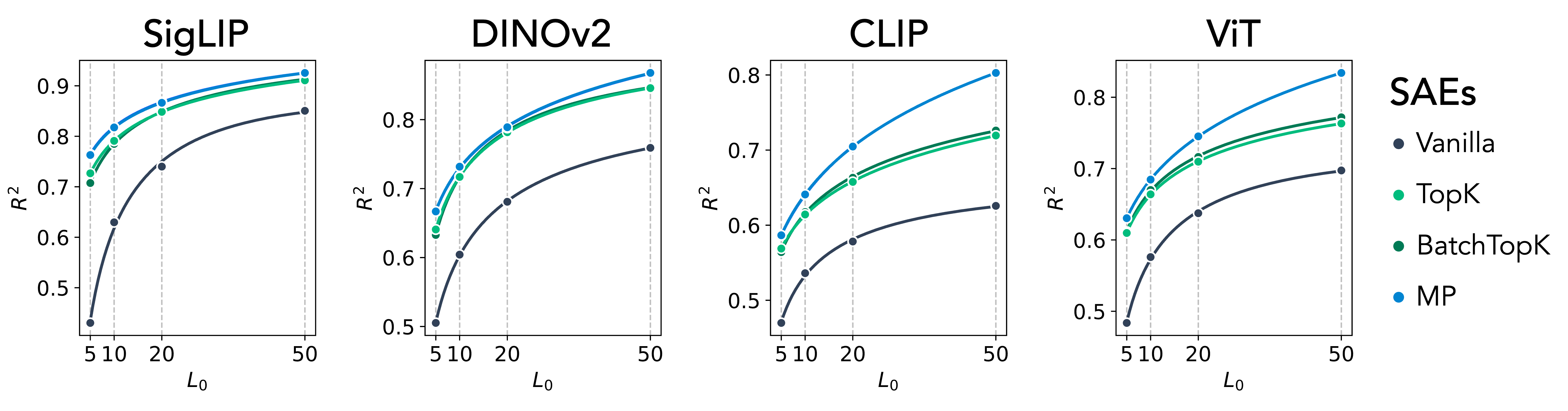
Figure 2: MP-SAE recovers more expressive atoms than standard SAEs. Reconstruction performance (R2) as a function of sparsity level; SigLIP, DINOv2, CLIP, and ViT.
Further analysis reveals that MP-SAE learns dictionaries with low coherence, selecting incoherent subsets at inference. This structure allows MP-SAE to leverage hierarchical representational capacities, facilitating meaningful feature extraction reflecting the inherent structure of the data.

Figure 3: MP-SAE learns more coherent dictionaries but selects incoherent atoms. Babel scores for full dictionaries and co-activated subsets.
MP-SAE demonstrates hierarchical reconstruction capabilities, building from coarse outlines to fine details, promoting more advanced interpretability and mirroring realistic feature organization. Unlike shallow SAEs, MP-SAE progresses through rank-selected atoms which allows refined successive improvement seen in inference experiments.
Conclusion
This study clarifies the strengths of the MP-SAE framework over traditional shallow SAEs by advancing reconstruction expressivity, addressing coherence challenges, and facilitating effective hierarchical feature learning. The approach's applicability extends beyond MNIST to other vision models, highlighting MP-SAE’s potential to become a standard tool in interpretable machine learning models. Future extensions could explore its application in more complex hierarchical scenarios and in other fields requiring efficient sparse representations.