- The paper introduces HALO, a framework that reduces critical-path delays in LLM inference through hardware-aware quantization.
- It combines sensitivity-aware uniform and delay-aware non-uniform quantization with adaptive DVFS to optimize performance on GPUs and TPUs.
- Experimental results show up to 353% speedup and 51% energy savings, significantly enhancing efficiency in hardware-accelerated LLM deployments.
HALO: Hardware-aware Quantization with Low Critical-path-delay Weights for LLM Acceleration
This essay provides a detailed summary of the paper "HALO: Hardware-aware quantization with low critical-path-delay weights for LLM acceleration" (2502.19662). The paper introduces a novel framework, HALO, aimed at optimizing LLM inference through a hardware-aware quantization method that reduces critical-path delays by strategically selecting low-delay weights. The approach integrates seamlessly with accelerator platforms like GPUs and TPUs, achieving significant performance and energy efficiency improvements.
Introduction and Motivation
The preponderant growth in Transformer-based LLMs, expanding 100-fold biennially, has extensively outstripped hardware advancements. This discrepancy results in prohibitive inference costs due to the computational demands of models like LLaMA and GPT-4, necessitating efficient methodologies like quantization. Existing techniques are predominantly hardware-agnostic, constrained by bit-width limitations, and overlook the variances in Multiply-Accumulate (MAC) unit's critical paths. HALO addresses these limitations through a comprehensive framework that optimizes LLM inference by minimizing critical path delays, enabling high-frequency and energy-conserving deployment on heterogeneous hardware architectures.
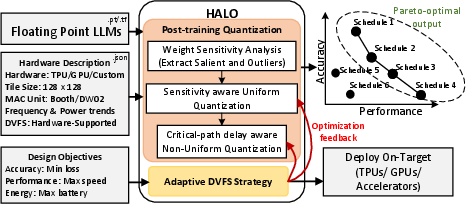
Figure 1: HALO quantization framework, using architectural details to yield Pareto-optimal trade-offs for diverse deployments.
HALO Framework Overview
HALO provides a versatile post-training quantization (PTQ) framework leveraging MAC unit properties to minimize delays and enable dynamic voltage and frequency scaling (DVFS). It is implemented in several steps:
- Sensitivity-aware Uniform Quantization identifies and preserves critical weights essential for maintaining model integrity.
- Critical-path delay Aware Non-Uniform Quantization adjusts quantization levels to align with hardware constraints, optimizing weight patterns for efficient hardware utilization.
- Adaptive DVFS dynamically adjusts operating frequencies to match quantization levels, maximizing performance gains while capping power budgets.
These processes are designed to work in tandem to deliver 270% average performance gains and 51% energy savings with minimal accuracy degradation.
Implementation Considerations
The implementation of HALO involves adapting the quantization process to distinct hardware typologies, specifically targeting LLM accelerators such as TPUs and GPUs. By incorporating MAC unit characteristics directly into the quantization strategy, it capitalizes on frequency-scaling opportunities presented by dynamic weight sensitivities. These adjustments are achieved through a detailed analysis of weight distributions and activation behaviors, taking into account both salient and outlier weights.
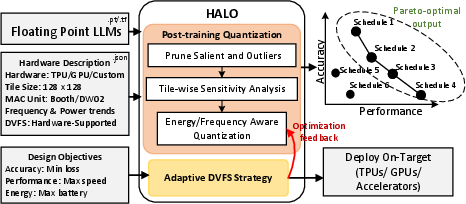
Figure 2: HALO quantization framework, using architectural details to yield Pareto-optimal trade-offs for diverse deployments.
Another critical aspect is the integration with modern hardware's DVFS capabilities. As GPUs, such as the NVIDIA GA100, support 181 DVFS configurations, HALO utilizes this flexibility to adjust operational frequencies in line with quantization outcomes, further enhancing performance and energy efficiency without extensive hardware modifications.
The paper demonstrates HALO's effectiveness through comprehensive evaluation across various LLM models and datasets, using a custom simulator for systolic arrays and GPU evaluations through modified AccelSim configurations. Results show HALO outperforms conventional approaches like FP16 and W8A8 quantization, providing up to 353% execution speedup and delivering significantly better energy efficiency.
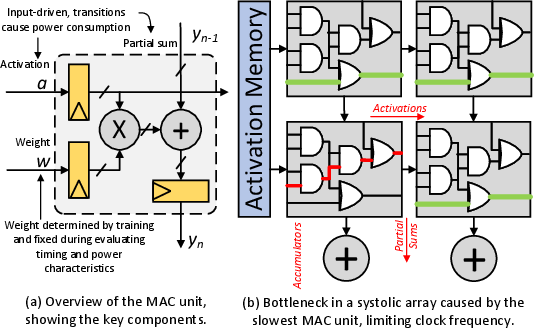
Figure 3: Impact of MAC unit on systolic array efficiency.
The integration of HALO with existing and future hardware is a focal point, ensuring adaptability across various hardware configurations without compromising model accuracy, making it a robust solution for scalable LLM deployments.
Conclusion
HALO represents a significant advancement in model efficiency for LLM acceleration, offering a scalable and hardware-aware quantization strategy that effectively bridges the gap between model size and hardware capabilities. By minimizing power consumption and critical-path delays, HALO enables efficient, high-performance inference across heterogeneous architectures, marking a pivotal development in hardware-aware deep learning optimizations. The potential for further research lies in extending HALO's capabilities to additional hardware configurations and exploring more sophisticated adaptation mechanisms for broader LLM applications.