- The paper introduces a consistent auto-regressive trajectory planning approach that integrates reinforcement learning with temporal consistency to overcome imitation learning limitations.
- The methodology decomposes planning into fixed mode selection and sequential trajectory generation, improving training efficiency and policy stability.
- Results on the nuPlan dataset demonstrate superior performance in safety and progress metrics compared to traditional imitation learning and rule-based planners.
CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving
This essay provides a detailed summary and evaluation of the paper titled "CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving" (2502.19908). The study introduces an innovative reinforcement learning-based trajectory planner for autonomous driving, overcoming key challenges present in existing methods.
Introduction
Trajectory planning is fundamental to autonomous driving, involving the generation of feasible future poses for vehicle control. Current approaches predominantly utilize imitation learning, aligning planned trajectories with human driving demonstrations, which runs into issues like distribution shift and causal confusion. Reinforcement Learning (RL), while promising in other domains, has yet to effectively handle large-scale, real-world autonomous driving scenarios.
CarPlanner proposes a consistent auto-regressive model within a reinforcement learning framework, integrating temporal consistency to improve training efficiency and policy stability. Unlike conventional methods, CarPlanner combines an RL-based planner, a universal reward function guided by expert demonstrations, and an invariant-view module to enhance policy generalization.
Methodology
CarPlanner builds on a Markov Decision Process framework, treating trajectory planning as a multi-step decision problem. The approach decomposes the task into policy and transition models, employing a consistent mode that remains unchanged across time steps, thereby enhancing long-term policy consistency.
Framework Overview
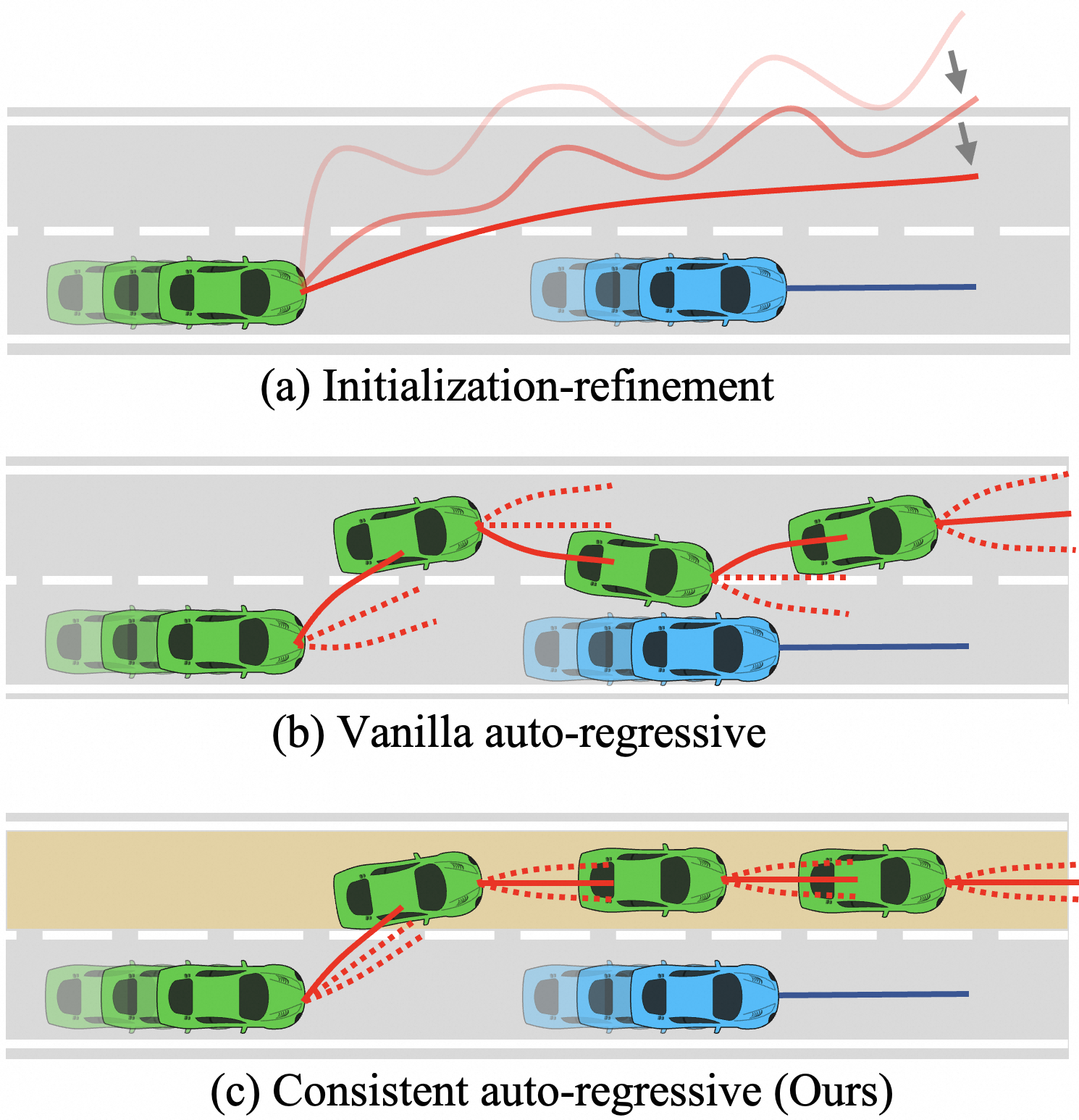
Figure 1: Frameworks for multi-step trajectory generation. (a) Initialization-refinement that generates an initial trajectory and refines it iteratively. (b) Vanilla auto-regressive models that decode subsequent poses sequentially. (c) Our consistent auto-regressive model that integrates time-consistent mode information.
- Non-reactive World Model: Predicts trajectories of other traffic agents using the initial state as input through neural networks optimized for GPU acceleration.
- Mode Selector: Determines fixed longitudinal and lateral mode conditions from the initial state, generating multiple trajectory hypotheses efficiently.
- Trajectory Generator: Employs an auto-regressive structure conditioned on consistent mode information to generate mode-aligned multi-modal trajectories and utilizes policy rollouts complemented by an expert-guided reward function.
- Rule-augmented Selector: Incorporates a rule-based selector to assess safety, comfort, and progress metrics that were learned during the selection phase, favoring the highest-scoring trajectory.
Training and Reward Function
The training consists of first learning the world model, followed by the mode selector and trajectory generator. The proximal policy optimization (PPO) framework is leveraged with a universal reward function comprising expert alignment and driving standards like collision avoidance and drivable area compliance.
The CarPlanner system is the first to surpass the state-of-the-art IL and rule-based planners on the nuPlan dataset, achieving impressive performance metrics. In non-reactive environments, CarPlanner displayed excellent overall scores, particularly in safety and progress metrics, demonstrating its capability in navigating complex real-world scenarios.
Qualitative Evaluation
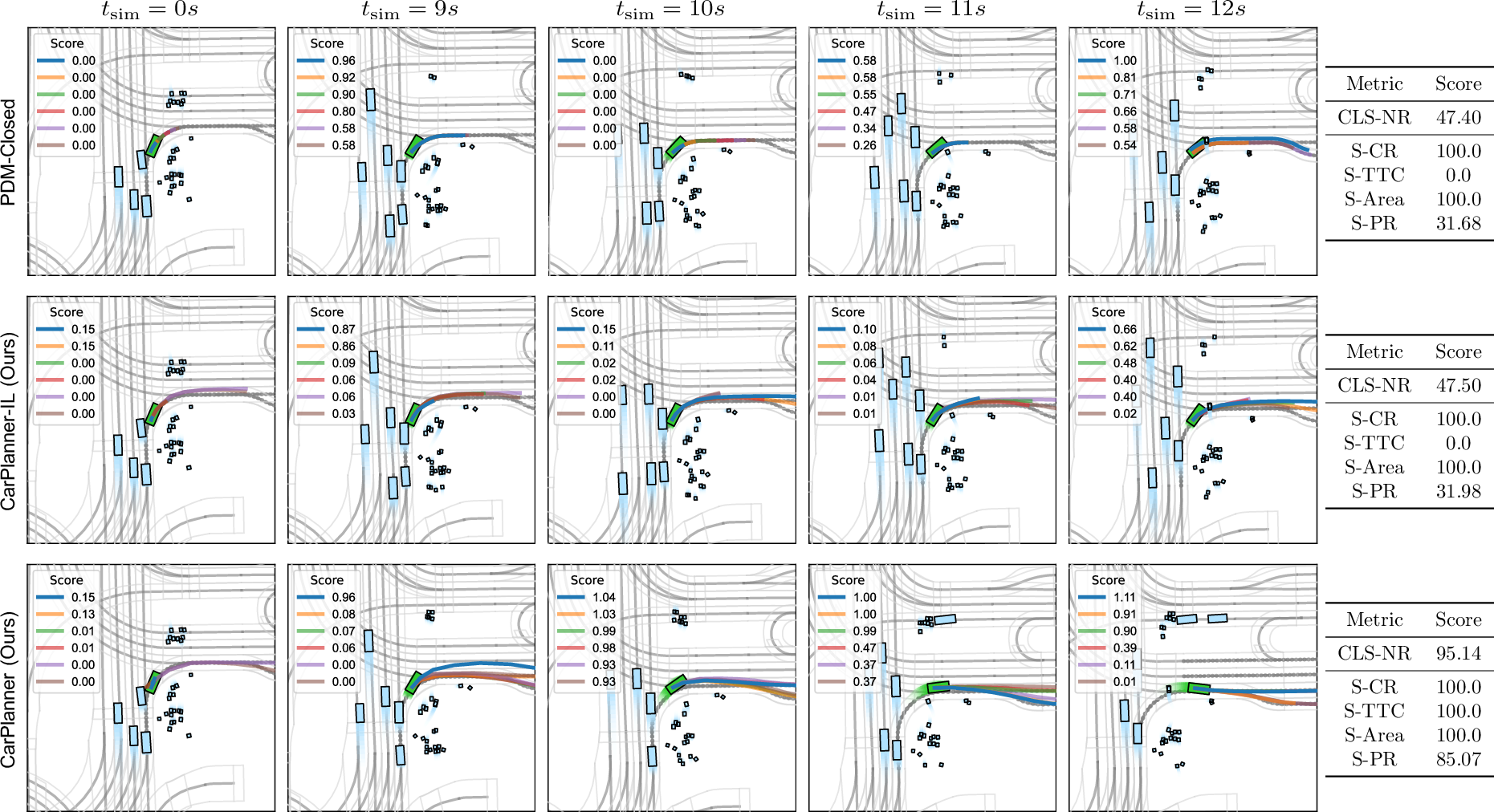
Figure 2: Qualitative comparison of PDM-Closed and our method in non-reactive environments. The scenario is annotated as waiting_for_pedestrian_to_cross. In each frame shot, ego vehicle is marked in green, showcasing improved decision making over previous models.
CarPlanner's use of consistent mode information allowed the autonomous vehicle to handle pedestrian-crossing scenarios with better foresight and reaction compared to traditional non-consistent models.
Discussion
CarPlanner's consistent architecture provides a novel approach to enhancing RL efficiency in trajectory planning, yet it leaves room for handling the challenging nature of reactive environments due to simulated traffic agents' behaviors. Further research could integrate more sophisticated models for reactive environments, optimizing CarPlanner's policies to better accommodate dynamic changes in real-time.
Conclusion
CarPlanner represents a significant advancement in the use of reinforcement learning for autonomous driving, demonstrating enhanced training efficiency and superior performance over existing models. This approach highlights RL's potential to address the limitations of imitation learning in trajectory planning. Future work will focus on refining reactive world models and exploring scalable hardware implementations to further push the efficacy of RL-based planning systems.
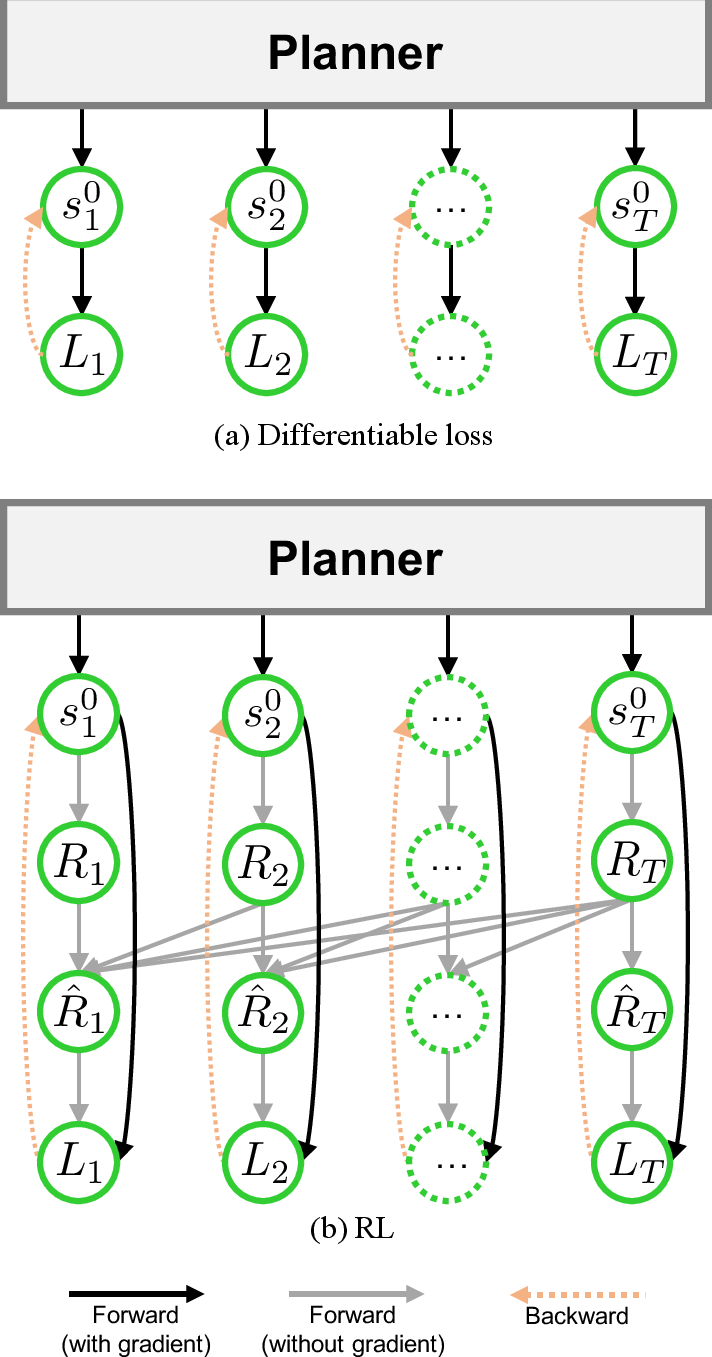
Figure 3: The computational graph of differentiable loss (a) and RL (b) framework for optimizing same metrics such as displacement errors, collision avoidance, and adherence to drivable area.