- The paper introduces HyPlan, a hybrid framework that integrates DRL with explicit POMDP planning for collision-free navigation under partial observability.
- It employs confidence calibration and vertical pruning to reduce computational overhead while maintaining high safety in dynamic, unpredictable environments.
- Experimental evaluations on the CARLA-CTS2 benchmark show superior safety (SI90 = 7) and efficiency, outperforming pure DRL and other hybrid planners.
Hybrid Learning-Assisted Planning for Safe Autonomous Driving: The HyPlan Framework
Introduction
HyPlan introduces a hybrid learning-assisted planning paradigm for collision-free navigation (CFN) in autonomous driving under partial observability. The framework integrates multi-agent behavior prediction, deep reinforcement learning (DRL) via proximal policy optimization (PPO), and explicit online POMDP planning with confidence-based vertical pruning. The primary objective is to achieve high safety in navigation while reducing the computational overhead typically associated with explicit planning methods, especially in complex, dynamic traffic environments with occlusions and unpredictable pedestrian behavior.
The CFN problem is formalized as a discrete-time POMDP (S,A,T,R,γ,Z,O), where the state space S encodes the ego-car and exogenous agents' configurations, including positions, velocities, orientations, and goals. Observability is partial: the ego-car's state is fully observable, while exo-agents may be occluded. Actions comprise steering angles and discrete acceleration choices. The transition model leverages the bicycle kinematics for ego-car and straight-line motion for exo-agents. The reward function penalizes collisions and near-misses, incentivizing rapid goal attainment. This formalization enables principled reasoning about uncertainty and risk in real-world traffic scenarios.
HyPlan Architecture
HyPlan's architecture orchestrates several modules for robust decision-making:
- Multi-Agent Behavior Prediction: AutoBots predicts exo-agent trajectories, informing downstream planning.
- Ego-Car Path Planning: A hybrid A* planner computes the shortest safe path using a costmap enriched with predicted exo-agent paths.
- Velocity Planning via IS-DESPOT: An explicit online POMDP planner, IS-DESPOT, is guided by a PPO-based DRL agent (NavPPO) for velocity control.
- Confidence Calibration and Vertical Pruning: During deployment, NavPPO's value estimates are calibrated using CRUDE, and IS-DESPOT* leverages confidence-based vertical pruning to terminate planning early when high-confidence value estimates are available.
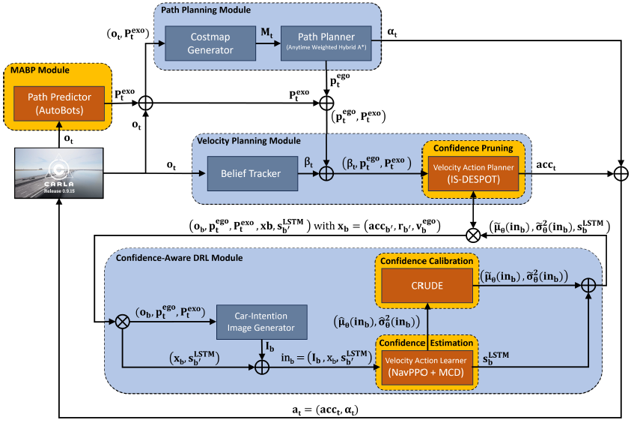
Figure 1: Overview of HyPlan architecture with CARLA, illustrating the integration of behavior prediction, path planning, DRL, and explicit POMDP planning.
This modular separation of steering and velocity planning enables HyPlan to poll control actions at 4 Hz, balancing responsiveness and computational efficiency.
Deep Reinforcement Learning Component: NavPPO
NavPPO is a DRL agent employing an actor-critic architecture with shared visual feature encoding. The input comprises an RGB intention image (costmap with predicted paths) and non-visual state features (previous reward, last velocity action, current velocity). The network processes the intention image via convolutional layers, concatenates the resulting latent vector with state features, and passes them through an LSTM. The actor head outputs logits for velocity actions, while the critic head estimates state value.
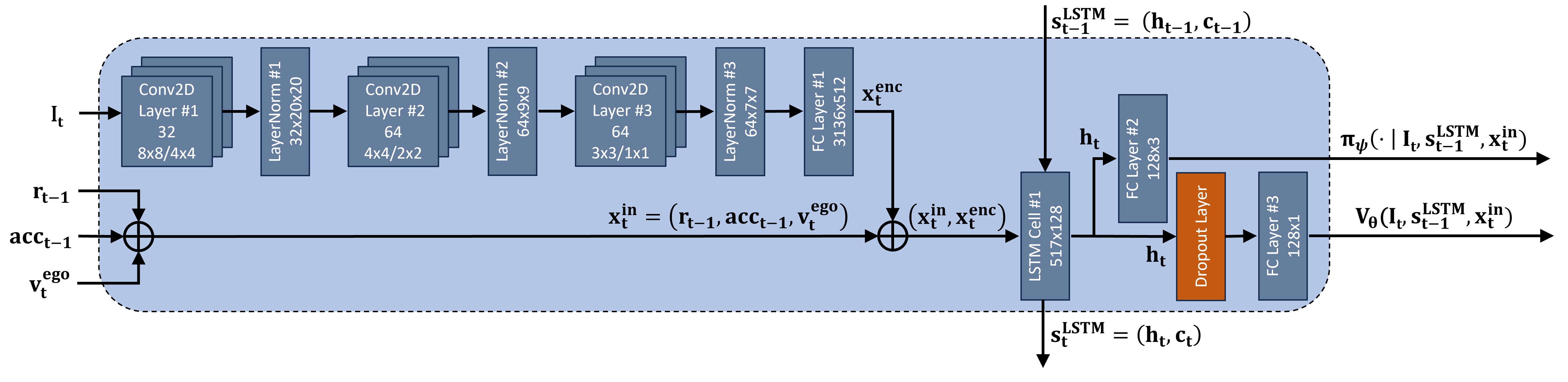
Figure 2: DRL NavPPO network architecture, showing the flow from intention image and state features through convolutional, LSTM, and actor-critic heads.
NavPPO is trained to imitate the IS-DESPOT* planner policy using a PPO-based loss, with the advantage estimate A^t computed via GAE. The probability ratio ρt(ψ) between the DRL policy and planner policy is clipped to stabilize training. Regularization is applied to prevent overfitting.
Confidence Calibration and Vertical Pruning
Post-training, NavPPO's value predictions are calibrated using CRUDE. During deployment, multiple stochastic forward passes (via MC dropout) yield mean and variance estimates for belief state values. The calibrated mean serves as the heuristic upper bound for IS-DESPOT*, while the inverse variance quantifies confidence. The planner uses a confidence-weighted sum of the lower and upper bounds to determine whether to continue planning from a belief node. High-confidence, high-value nodes trigger early termination (vertical pruning), reducing planning depth and computational cost without sacrificing safety.
Experimental Evaluation
HyPlan was evaluated on the CARLA-CTS2 benchmark, comprising 23,000+ critical traffic scenes with pedestrian crossings, derived from real-world accident data (GIDAS). Baselines included pure DRL agents (NavPPO, NavA2C), explicit planners (IS-DESPOTp), and hybrid planners (HyLEAP, LEADER, HyLEAR).

Figure 3: Scenarios of CARLA-CTS2 benchmark with pedestrian crossing, highlighting the diversity and complexity of test cases.
Safety and Efficiency Metrics
HyPlan achieved the highest safety index (SI90 = 7), lowest crash (12.36%) and near-miss (8.04%) rates among all baselines. However, its time to goal (TTG = 19.97s) was higher, reflecting a more cautious driving policy. Execution time (161.17ms) was significantly faster than other explicit and hybrid planners, though still slower than pure DRL methods.
Planning Effort
HyPlan's IS-DESPOT* with vertical pruning exhibited the lowest planning time (149.94ms), fewest belief nodes (15.62), and shallowest planning trial depth (2.21), outperforming all other explicit and hybrid planners in computational efficiency.
Ablation Study
Ablative analysis revealed that omitting vertical pruning improved safety but increased execution time, while removing confidence calibration led to over-optimistic pruning and degraded safety. The integration of pedestrian path prediction marginally improved safety and reduced planning effort. The full HyPlan configuration provided the best trade-off between safety and efficiency.
Theoretical and Practical Implications
HyPlan demonstrates that hybrid learning-assisted planning can bridge the gap between safety and computational efficiency in autonomous driving. The use of DRL-guided explicit planning with confidence-based pruning enables rapid, safe decision-making in complex, uncertain environments. The empirical results challenge the notion that deep learning alone suffices for safety-critical navigation, highlighting the value of explicit reasoning under uncertainty.
Future Directions
Potential future developments include:
- Extending HyPlan to handle richer agent models (e.g., non-linear pedestrian intent, multi-modal behaviors).
- Integrating multimodal sensor fusion and LLM-based reasoning for more robust perception and planning.
- Scaling HyPlan to real-world deployment with hardware-in-the-loop testing and domain adaptation.
- Investigating formal safety guarantees via logic-based verification modules.
Conclusion
HyPlan advances the state-of-the-art in hybrid planning for autonomous driving by combining DRL, explicit POMDP planning, and confidence calibration. The framework achieves superior safety and planning efficiency on challenging benchmarks, though further work is needed to close the inference speed gap with pure learning-based methods. The results underscore the importance of principled hybrid approaches for safe, reliable autonomous navigation in uncertain environments.