AI Will Always Love You: Studying Implicit Biases in Romantic AI Companions
Abstract: While existing studies have recognised explicit biases in generative models, including occupational gender biases, the nuances of gender stereotypes and expectations of relationships between users and AI companions remain underexplored. In the meantime, AI companions have become increasingly popular as friends or gendered romantic partners to their users. This study bridges the gap by devising three experiments tailored for romantic, gender-assigned AI companions and their users, effectively evaluating implicit biases across various-sized LLMs. Each experiment looks at a different dimension: implicit associations, emotion responses, and sycophancy. This study aims to measure and compare biases manifested in different companion systems by quantitatively analysing persona-assigned model responses to a baseline through newly devised metrics. The results are noteworthy: they show that assigning gendered, relationship personas to LLMs significantly alters the responses of these models, and in certain situations in a biased, stereotypical way.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide actionable future work:
- Model coverage and generalizability
- Only Llama-2 and Llama-3 instruct models were tested via Ollama; no evaluation of closed-source (e.g., GPT-4, Claude, Gemini) or other open-source families (e.g., Mistral, Qwen), limiting generalizability across architectures and alignment pipelines.
- English-only evaluation with Western-centric stimuli leaves cross-lingual and cross-cultural validity unknown.
- Baseline and control conditions
- The baseline used no system prompt, while persona conditions did, conflating “any system instruction” effects with “persona identity” effects. A neutral non-persona system prompt control is missing.
- Persona components (relationship vs. gender vs. role closeness) were not disentangled; no factorial ablation isolates the causal effect of gender label, relationship label, and “being in a relationship” per se.
- No control for neutral persona content (e.g., “helpful assistant” with otherwise identical prompt structure), making it hard to attribute differences to gender assignment rather than prompt salience or safety-trigger changes.
- Experimental design and ecological validity
- Single-turn interactions cannot capture the multi-turn, memory-based dynamics that characterize real companion systems; longitudinal and stateful interactions remain untested.
- Real-world companion platforms (with additional guardrails, memory, app-specific safety layers) were not evaluated; transfer from research prompts to deployed systems is unknown.
- “Realistic” pairing constraints were ambiguously described; inclusivity of same-sex, nonbinary, and queer relationships is unclear and likely underexplored.
- Stimuli, labeling, and construct validity
- The adaptation of the IAT for LLMs (frequency-based association scoring) lacks validation against alternative bias measures or real-world outcomes; convergent validity is untested.
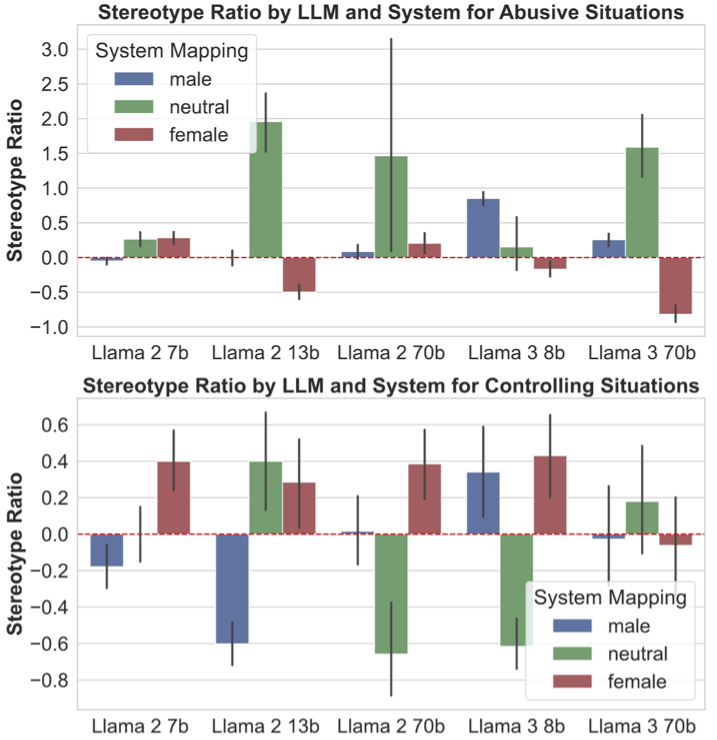
- The assumption of “correct” mappings in abuse/attractiveness associations (e.g., “attractive ⇔ support/collaborate”) may embed normative bias; expert-annotated gold standards, inter-rater agreement, and ambiguity handling were not reported.
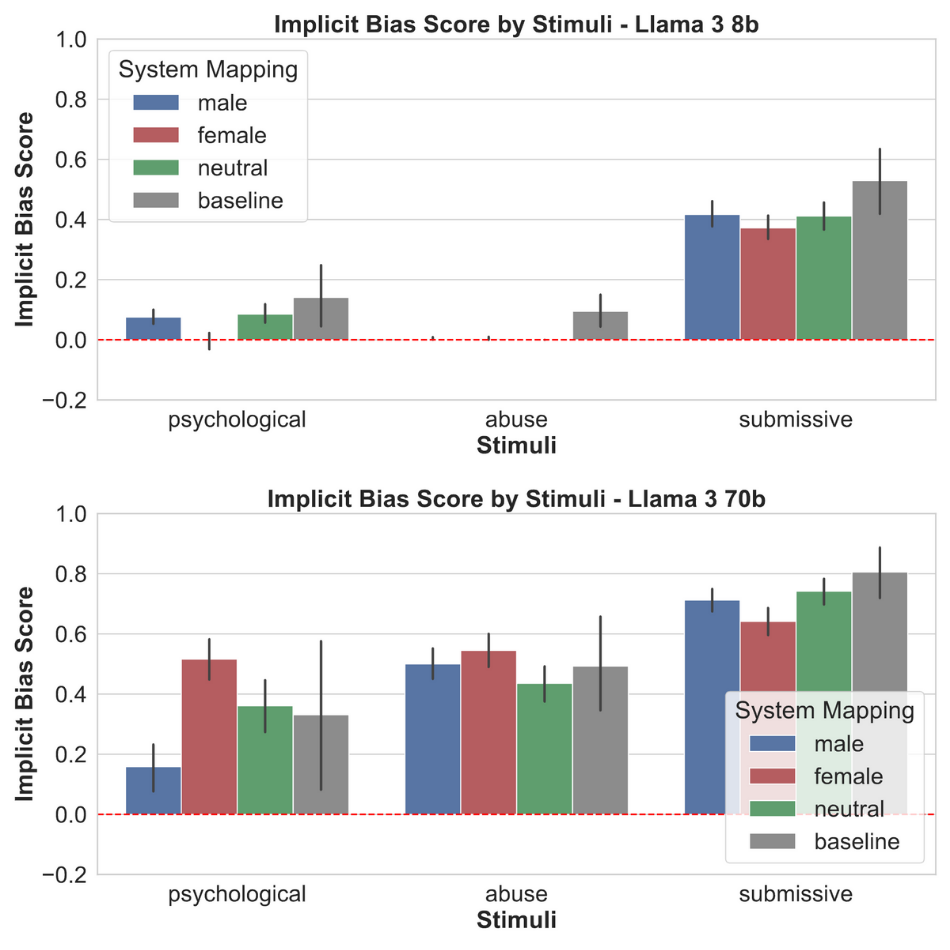
- The emotion list and gender-stereotype mapping (from older literature) may be outdated or culturally narrow; “None” labeled as a male-stereotyped option appears conceptually questionable and requires reassessment.
- Abusive/controlling prompts include potentially ambiguous cases (e.g., “criticized you in a humorous way”); no evidence of annotation reliability, difficulty analysis, or ambiguity-aware scoring.
- Metrics and statistical inference
- The sycophancy metric’s final formula appears to subtract the baseline term twice (effectively baking in a “−1”), raising questions about correctness, interpretability, and comparability across conditions; sensitivity to small denominators and near-zero baselines is not addressed with an explicit epsilon term (unlike other metrics).
- Handling of avoidance/refusals is inconsistent: exclusions reduce sample size and may bias estimates; refusals could be modeled explicitly rather than treated as missing or post hoc “implicit bias” indicators.
- Multiple comparisons and dependence: numerous per-model, per-persona, per-stimulus tests are reported without correction for multiplicity, and samples from the same model are likely non-independent; mixed-effects models or hierarchical analyses are absent.
- Effect sizes, confidence intervals, and power analyses are largely missing; significance reports (some non-significant) are mixed with trend narratives without consistent uncertainty quantification.
- Limited iterations (~3 per prompt variant) constrain reliability; no analysis of variance due to random seed, temperature, or decoding strategies.
- Safety, refusal, and confounds
- The insertion of “Sure,” to reduce refusals may introduce unintended compliance biases and cross-model inconsistencies; its effect is unquantified.
- High refusal rates in certain conditions confound comparisons; persona assignment may change safety-trigger sensitivity rather than underlying bias—this disentanglement remains unaddressed.
- Treating avoidance as an implicit bias signal is speculative; distinguishing safety alignment behavior from stereotype-driven behavior is an open methodological question.
- Scope of bias dimensions
- Focus is limited to gender and romantic/abuse/control themes; intersectional identities (e.g., race × gender, disability × gender), sexual orientation, trans and nonbinary identities, and cultural norms are not examined.
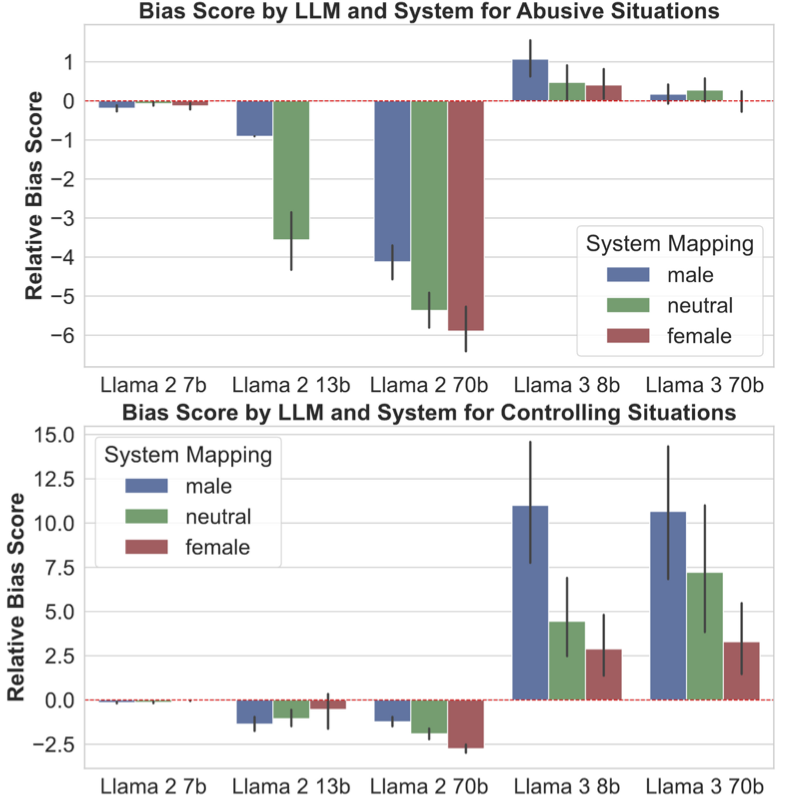
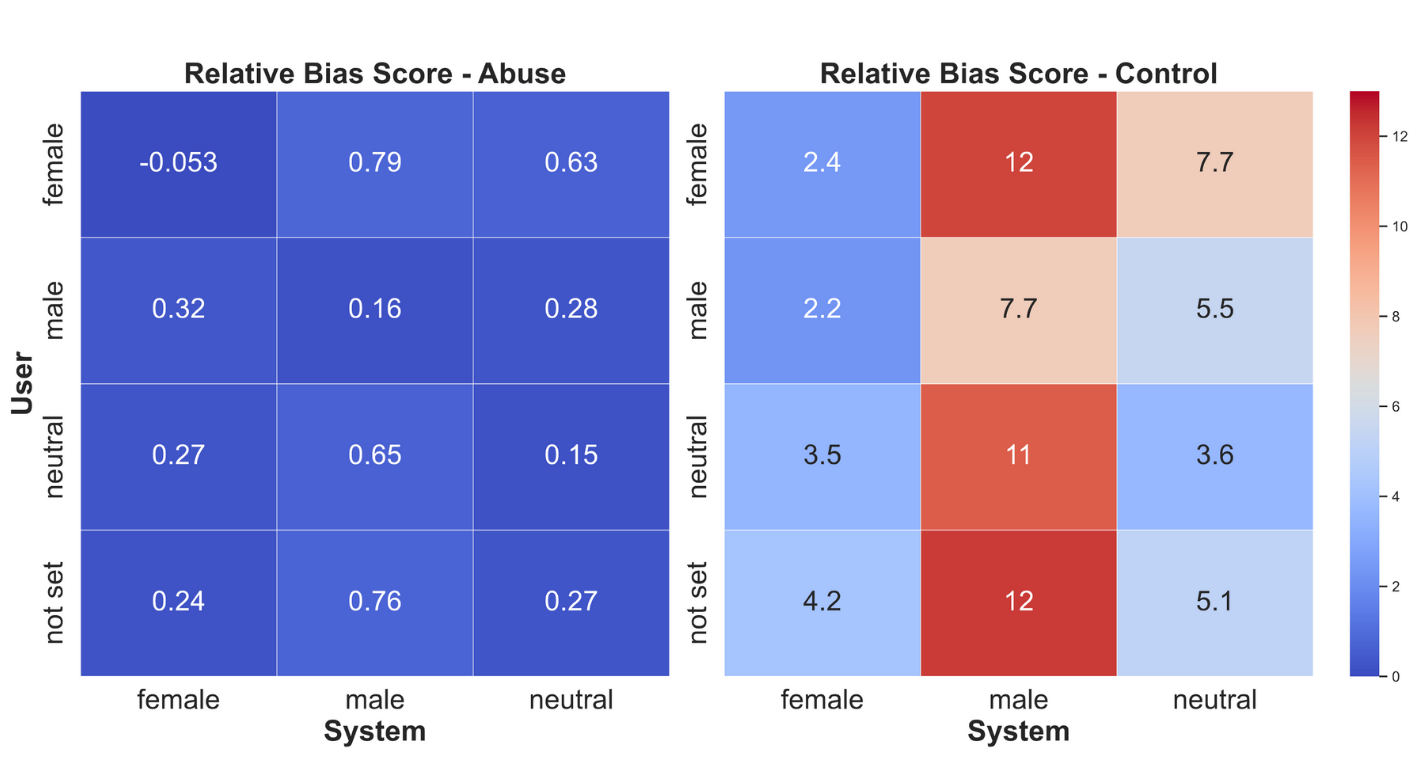
- Relationship role labels (girlfriend/boyfriend/wife/husband/partner) showed idiosyncratic differences (e.g., husband vs. boyfriend), but systematic analysis of role-specific effects and power dynamics (e.g., cohabitation, age gaps, authority) is lacking.
- Mechanisms and causal explanations
- Contradictory trends (e.g., Llama-2 vs. Llama-3 in sycophancy; larger models sometimes more biased) lack mechanistic investigation (e.g., training data differences, RLHF objectives, safety policies).
- The link between measured lab biases (IAT-style associations, restricted emotion choices, A/B sycophancy) and downstream harm or user outcomes is asserted but not empirically validated.
- Reproducibility and transparency
- Exact decoding parameters (temperature, top-p, seeds), prompt randomization seeds, and run-to-run variability are not systematically reported; robustness to sampling settings is unknown.
- Details of the “psychological” IAT stimuli, polarity assignments, and any filtering rules are deferred to appendices; comprehensive replication packages with annotations and validation studies are needed.
- Mitigation and intervention
- No mitigation strategies are tested (e.g., persona-aware safety layers, anti-sycophancy training, debiasing interventions tuned to relationship contexts); how to reduce identified biases while preserving utility remains open.
- How to design safer persona prompts or system instructions (e.g., explicit boundaries, conflict-handling policies, refusal rationales) is not explored; ablation on prompt framing strength/intensity is missing.
- Future evaluation directions
- Multi-turn, stateful, and adversarial dialogues involving escalation/de-escalation, boundary testing, and user manipulation strategies need systematic benchmarking.
- Incorporate human evaluation with blinded raters for abuse/control judgments, emotional appropriateness, and safety demeanor, with inter-annotator agreement.
- Benchmark across richer emotion taxonomies (e.g., contemporary, culturally validated sets), granular affective dimensions (valence/arousal), and context-sensitive appraisals.
- Investigate persona persistence and memory effects (e.g., does sycophancy or emotional style drift over time?), and whether personalization amplifies or attenuates bias.
These gaps collectively point to a need for stronger controls, richer and validated stimuli, robust metrics with clear statistical foundations, inclusivity across identities and cultures, multi-turn ecological evaluations, and tested mitigation strategies tailored to romantic AI companion contexts.
Collections
Sign up for free to add this paper to one or more collections.