- The paper demonstrates that computer vision models trained on natural images partially replicate human low-level vision traits through rigorous psychophysical tests.
- Methodologies included contrast detection, contrast masking, and supra-threshold contrast matching, using cosine similarity metrics to assess model alignment with human data.
- Findings suggest specific models like DINOv2 and OpenCLIP excel in contrast sensitivity and masking, guiding future improvements in human-like visual processing.
Analyzing Low-Level Vision in Computer Vision Foundation Models
Introduction
The paper "Do computer vision foundation models learn the low-level characteristics of the human visual system?" (2502.20256) explores whether foundation models, such as DINO and OpenCLIP, trained on large-scale image datasets, exhibit characteristics similar to the human visual system (HVS). Specifically, the study assesses the alignment of computational models with low-level human vision traits including contrast detection, masking, and constancy. By evaluating the image encoders of 45 foundation and generative models, the research aims to illuminate whether the observed similarities indicate a convergence towards human-like interpretation of real-world imagery.
Methodology
The authors devised a rigorous testing framework involving nine test protocols to examine the low-level visual characteristics of 45 models. The tests were based on psychophysical stimuli traditionally used in human vision science. These included contrast detection tests, where models were evaluated on their ability to perceive small contrast variations against uniform and patterned backgrounds; contrast masking tests, assessing the impact of supra-threshold patterns on visibility; and supra-threshold contrast matching, analyzing the invariance of visual perception across spatial frequencies (2502.20256).
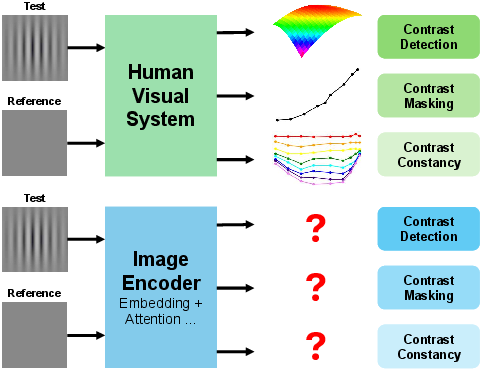
Figure 1: To determine whether image encoders of foundation models exhibit a similar low-level characteristic as human vision, models were tested on psychophysical stimuli.
The study implemented a specialized protocol using cosine similarity metrics to represent the perceived differences between test images and references, all within a structured luminance space simulating real-world viewing conditions. Foundation models were thereby assessed for their alignment with established human vision data.
Experimental Results
Contrast Detection
The paper reports that the models, particularly DINOv2 and SD-VAE, exhibit band-pass characteristics in their sensitivity to spatial frequency, resembling the human Contrast Sensitivity Function (CSF). However, computational models tend to show irregular responses to chromatic contrasts and lower sensitivity at reduced luminance levels, deviating slightly from human visual trends. Models displayed heightened drop-off in sensitivity with decreasing luminance—attributable perhaps to the training data's inherent noise characteristics.
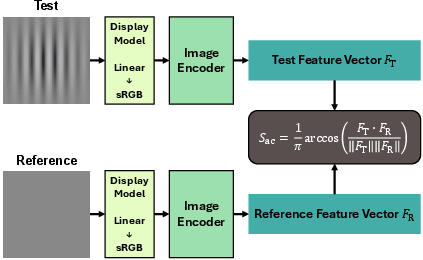
Figure 2: Pipeline for computing Sac through feature extraction and similarity computations based on modified inputs.
Contrast Masking
Foundation models such as OpenCLIP and DINOv2 aligned better with human data when subjected to contrast masking tests. They showed familiarity with human traits, especially under phase-incoherent conditions, suggesting that training datasets may contain ample stimuli for such traits to develop naturally. This alignment underscores training datasets' role in fostering human-like bottleneck characteristics.
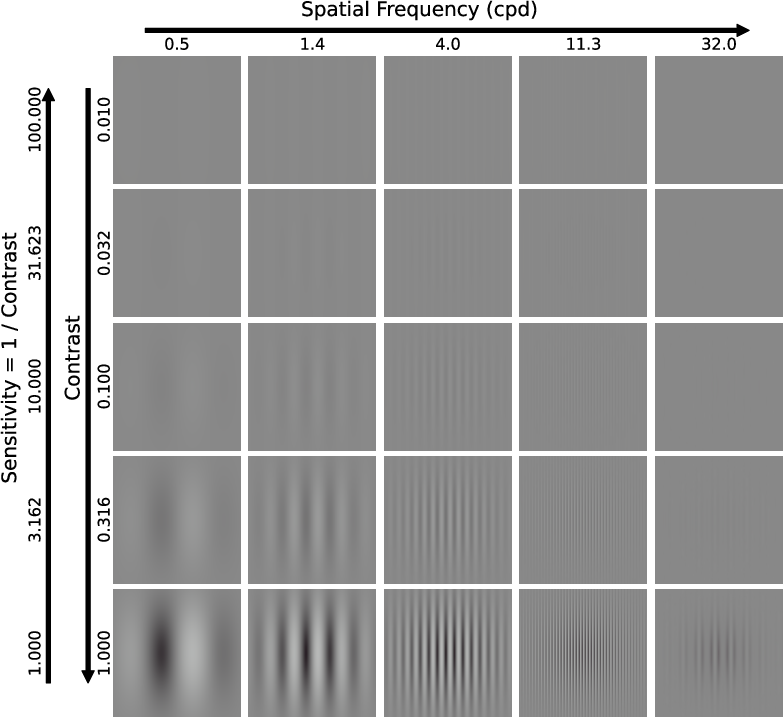
Figure 3: Gabors with different spatial frequencies and contrast, demonstrating model responses in the contrast detection tests.
Supra-threshold Contrast Matching
The findings demonstrate partial alignment in contrast constancy, crucial for visual perception stability across changing viewing conditions. DINOv2, noted for effective contrast matching, reflects considerations that mimic scale invariance akin to biological vision, albeit with inconsistencies across low frequencies.

Figure 4: Examples of test images for contrast detection and contrast masking used in the study.
Model Alignment Scores
Aggregate analysis indicated substantial variability among model variants, hinting at the randomness involved in capturing human visual traits. Interestingly, certain models, such as OpenCLIP, showed unexpectedly high alignment with human vision data, primarily masked contrast, surpassing even specialized human vision modeling like ColorVideoVDP.
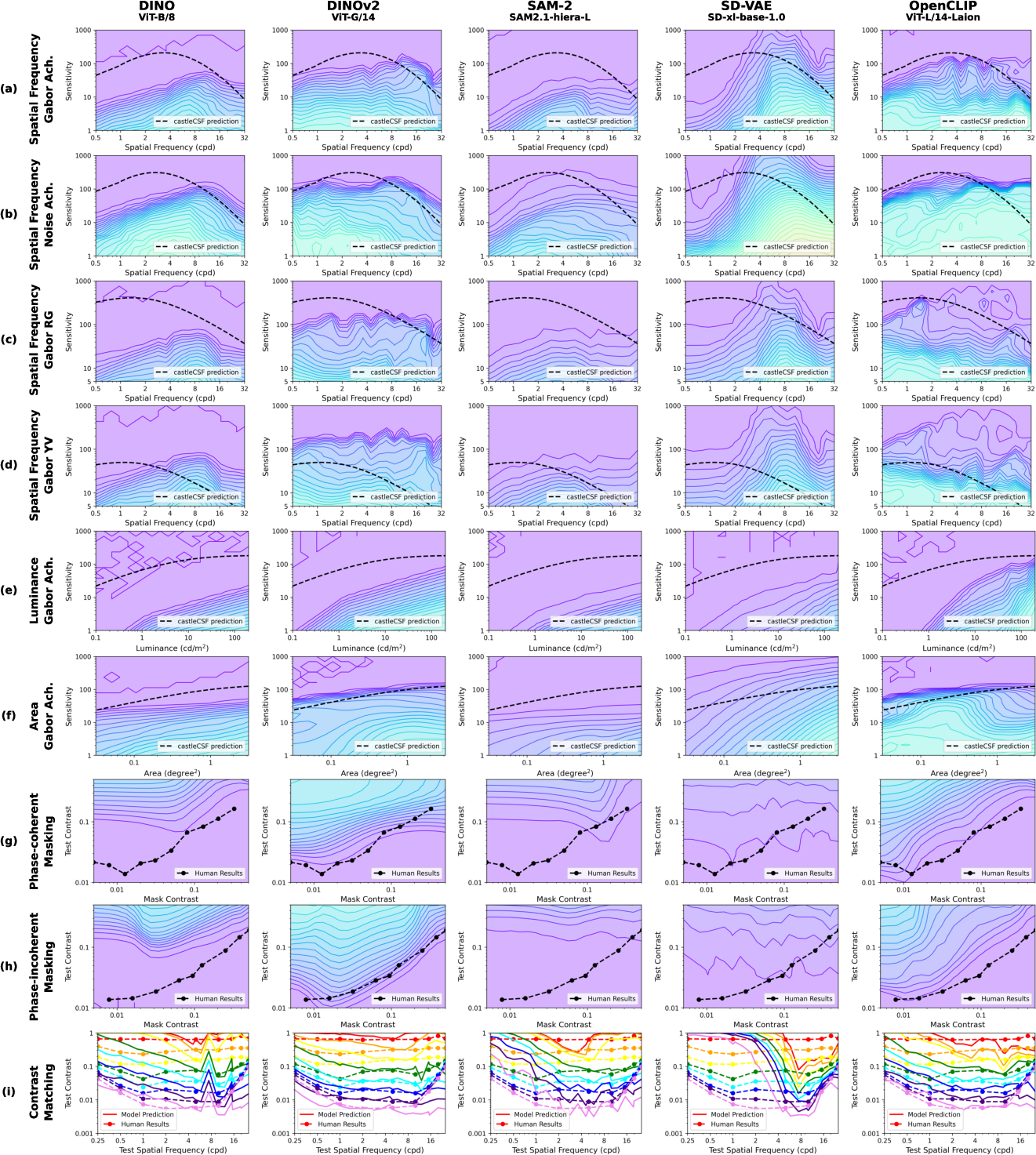
Figure 5: Selected representative experimental results showcasing test and model comparisons for various vision characteristics.
Implications and Future Work
The study suggests that large-scale training on natural images can indeed foster low-level vision traits akin to human vision. Some models reveal invariant encoding features, potentially beneficial for tasks requiring robust object detection and recognition. Future research could build upon these insights to refine computer vision models enhancing their adaptability to human-like perceptual tasks and exploring applications in areas like automated visual quality assessments, medical imaging, and advanced surveillance systems.
Conclusion
While notable progress exists, foundation models display partial alignment with low-level human vision characteristics, particularly in supra-threshold vision tasks. This alignment suggests both convergences in visual processing between biological and computational systems and divergence due to their distinct operational principles. This research invites more nuanced exploration into optimizing models for truly human-like visual interpretation and error resilience.
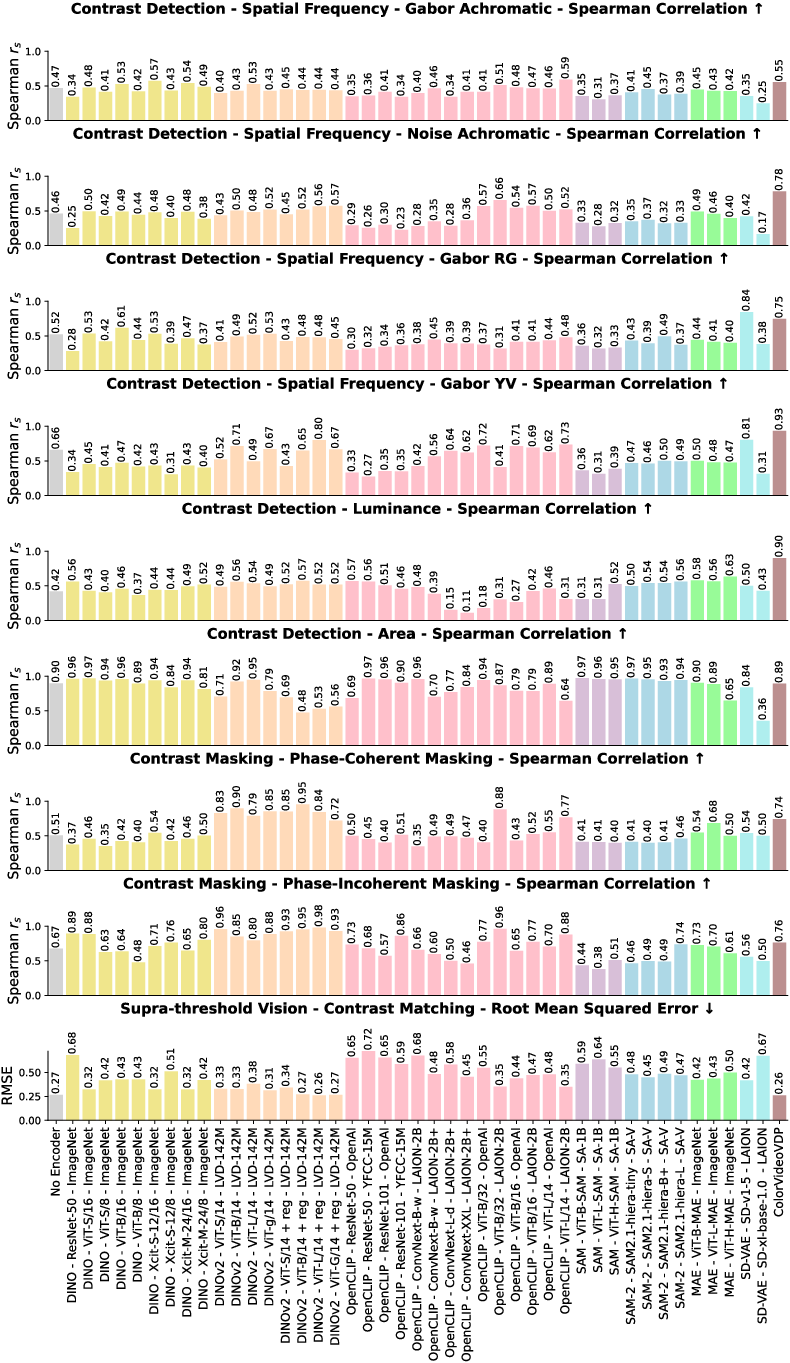
Figure 6: The quantified similarity error between all 45 models and HVS under various tests, illustrating comparative proximity to human vision.
