Visual-RFT: Visual Reinforcement Fine-Tuning
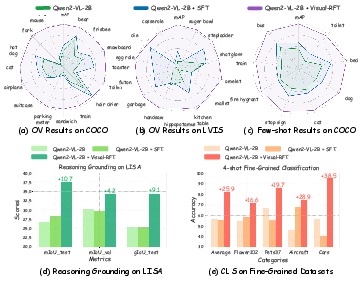
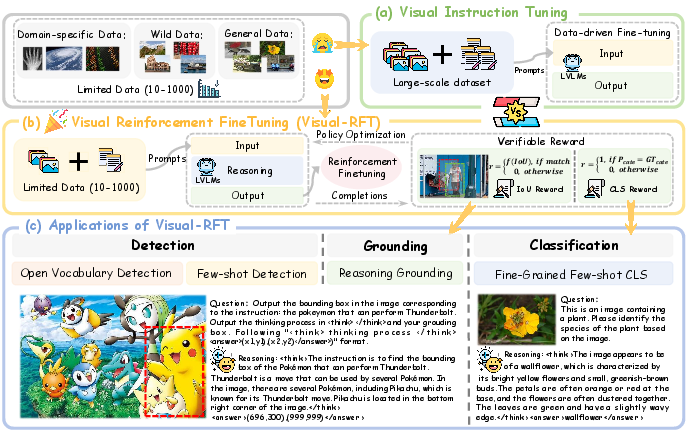
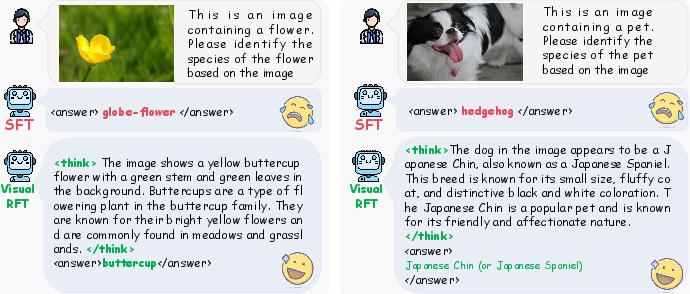
Abstract: Reinforcement Fine-Tuning (RFT) in Large Reasoning Models like OpenAI o1 learns from feedback on its answers, which is especially useful in applications when fine-tuning data is scarce. Recent open-source work like DeepSeek-R1 demonstrates that reinforcement learning with verifiable reward is one key direction in reproducing o1. While the R1-style model has demonstrated success in LLMs, its application in multi-modal domains remains under-explored. This work introduces Visual Reinforcement Fine-Tuning (Visual-RFT), which further extends the application areas of RFT on visual tasks. Specifically, Visual-RFT first uses Large Vision-LLMs (LVLMs) to generate multiple responses containing reasoning tokens and final answers for each input, and then uses our proposed visual perception verifiable reward functions to update the model via the policy optimization algorithm such as Group Relative Policy Optimization (GRPO). We design different verifiable reward functions for different perception tasks, such as the Intersection over Union (IoU) reward for object detection. Experimental results on fine-grained image classification, few-shot object detection, reasoning grounding, as well as open-vocabulary object detection benchmarks show the competitive performance and advanced generalization ability of Visual-RFT compared with Supervised Fine-tuning (SFT). For example, Visual-RFT improves accuracy by $24.3\%$ over the baseline in one-shot fine-grained image classification with around 100 samples. In few-shot object detection, Visual-RFT also exceeds the baseline by $21.9$ on COCO's two-shot setting and $15.4$ on LVIS. Our Visual-RFT represents a paradigm shift in fine-tuning LVLMs, offering a data-efficient, reward-driven approach that enhances reasoning and adaptability for domain-specific tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of concrete gaps and open questions that remain after this work, intended to guide follow-up research.
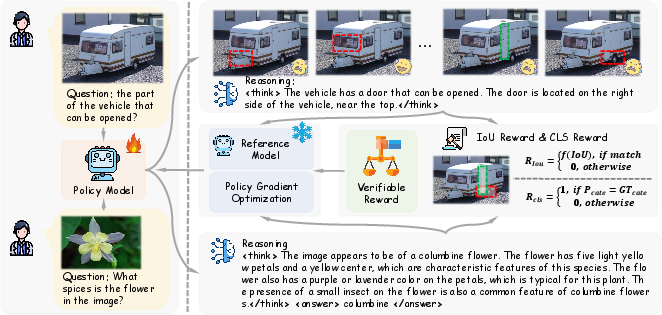
- Reward–metric mismatch in detection: The IoU+confidence reward averages per predicted box without penalizing missed ground-truth objects, duplicate detections, overlong lists, or poor precision–recall trade-offs. How to design a verifiable reward that better approximates AP/mAP (e.g., per-image F1/AP surrogates, set-level matching with cardinality penalties, NMS-aware rewards)?
- Missing ablations on reward design: No sensitivity analysis of reward components (IoU vs confidence vs format), thresholds (IoU τ), or weighting. What are optimal weightings and threshold schedules across tasks and datasets?
- Reward hacking risk: The current reward can be maximized by outputting a single high-IoU box and ignoring recall, or by manipulating confidence values. What anti-gaming mechanisms (e.g., recall-based penalties, calibration-aware rewards, minimal/maximum box count constraints) reduce exploitability?
- Lack of penalties for false “No Objects” predictions: The specification includes “No Objects” responses, but it is unclear how false negatives are penalized in the reward function.
- Unclear matching strategy: The detection reward references “matching” but does not specify the algorithm (greedy vs Hungarian) or tie-breaking. How do different matching strategies affect training stability and final AP?
- Format reward side effects: The “format reward” may optimize for tag compliance rather than task quality. What is its isolated impact on performance, output robustness, and generalization?
- No verification of reasoning quality: Rewards are only tied to final answers and tag format; the correctness or utility of the “thinking” tokens is not evaluated. Do longer or more detailed thoughts causally improve perception, or are they spurious?
- Missing ablation on reasoning tokens: No comparison of Visual-RFT with and without thinking tokens, or with different thought-length constraints. What is the minimal effective “reasoning” for best reward/compute trade-offs?
- Compute and efficiency not quantified: The method claims data efficiency but does not report group size (G), sampling temperature, number of rollouts per sample, wall-clock time, GPU hours, or variance across seeds. How do these factors scale with model size and task?
- Training stability analysis absent: No study of GRPO hyperparameters (KL β, advantage normalization, entropy), reward scaling, or failure cases. What stability practices (curriculum, KL schedules, reward clipping) are necessary for robust convergence?
- Baseline coverage limited: Comparisons are largely to SFT and a few specialized systems; no RL baselines (PPO, DPO, RLHF/RLAIF-V), no strong open-vocab detection baselines (e.g., OWL-ViT/Detic), and limited cross-architecture comparisons. How does Visual-RFT fare against these?
- Generality across LVLMs untested: Experiments use Qwen2-VL-2B/7B only. Does Visual-RFT transfer to other architectures (LLaVA, InternVL, IDEFICS, Kosmos-2, Gemini-like APIs)?
- Task breadth limited: The work focuses on detection, fine-grained classification, and reasoning grounding. Can verifiable rewards be designed for segmentation (mask IoU), keypoint/pose estimation (PCK), OCR/text spotting (edit distance), chart/table QA (cell-wise accuracy), and VQA with programmatic verifiers?
- Scaling to dense and large images: Boxes are constrained to integer coordinates in a 0–1000 range, with no study of large-resolution images or dense scenes. How does discretization affect AP and can adaptive coordinate resolutions or learned scaling improve performance?
- Multi-class, single-pass detection missing: The method appears to prompt per category; multi-class inference in a single pass is not explored. How to design verifiable multi-class rewards and avoid per-class prompting inefficiency?
- Open-vocabulary at scale: Experiments use 65/15 COCO splits and 13 rare LVIS classes. How does Visual-RFT scale to thousands of categories, long-tail taxonomies, and hierarchical/open-world recognition?
- Data contamination concerns: Given LVLM pretraining breadth, the risk of overlap with downstream datasets (FGVC, Cars196, LVIS rare classes) is not assessed. Can filtering or contamination checks clarify true generalization gains?
- Distribution-shift robustness: Aside from the MG (anime) dataset, robustness to real-world shifts (lighting, occlusion, clutter, adversarial perturbations) and corruptions is untested. How does Visual-RFT affect robustness vs SFT/baselines?
- Reliability of MG dataset evaluation: The MG dataset is non-standard and labeling/annotation quality is unclear. Can results be corroborated with established OOD/shift benchmarks (e.g., ImageNet-O, COCO-O, Synthetic-to-Real)?
- Effect on non-perception abilities: Catastrophic forgetting or trade-offs in general multimodal instruction following are not measured. Does Visual-RFT degrade chat, reasoning, OCR, or safety behaviors?
- Inference-time behavior unspecified: Is single-sample decoding sufficient at inference, or are multiple samples used to approximate the training condition (groups)? What is the latency/throughput impact of reasoning tokens and multi-response decoding?
- Verifiable rewards for subjective tasks: The approach does not address tasks without strict correctness (e.g., captioning, aesthetics, open-ended rationale quality). Can hybrid verifiers (programmatic + learned reward models) be safely integrated?
- Handling noisy/incomplete ground truth: Real detection annotations can be incomplete; current verifiers assume correctness and may penalize valid detections. How to design robust verifiers tolerant to labeling noise?
- Few-shot protocol clarity: “One-shot with around 100 samples” and a classification prompt mentioning “plant” across all fine-grained datasets suggest inconsistencies. More precise definitions, class balance details, and prompt generalization tests are needed.
- Hyperparameter and training detail gaps: Missing specifics on sampling temperatures, decoding constraints, maximum output length, KL β schedules, reward normalization, optimizer/lr schedules, seed variability, and early stopping criteria hinder reproducibility.
- Fairness of comparisons to specialized detectors: Pretraining differences and data scales between LVLMs and detection models (e.g., GroundingDINO) are not normalized. How to create apples-to-apples comparisons (frozen backbone, matched data)?
- Duplicate prediction handling: The reward does not explicitly penalize multiple predictions matching the same ground-truth object. Can set-based rewards with one-to-one matching and duplicate penalties improve training signals?
- NMS/assignment integration: Standard detection pipelines include NMS; the reward ignores post-processing. Would verifier-side NMS or differentiable set losses lead to better alignment with COCO/LVIS metrics?
- Class presence verification: The two-stage “check presence then detect” is only briefly mentioned. How is presence rewarded/penalized, and does joint modeling (presence + localization) improve learning?
- Safety and misuse: No discussion of safety, bias, or misuse risks in open-vocabulary detection (e.g., sensitive categories). How to integrate safety constraints into verifiable rewards?
- Compositional/multi-step visual reasoning: The method does not explore chained verifiers for multi-hop visual reasoning (e.g., detect → relate → count). How to define modular verifiers that encourage accurate intermediate reasoning steps?
- Long-context and multi-image inputs: Many real tasks involve multi-image or video inputs. Can Visual-RFT extend to temporal reasoning with verifiable rewards (e.g., tracking metrics, MOT challenges)?
- Token-level credit assignment: GRPO optimizes the whole completion; no exploration of token-level or stepwise rewards. Would intermediate shaping (curriculum, sparse-to-dense rewards) improve sample efficiency?
- Calibration and confidence evaluation: Confidence reward encourages high confidence on matched boxes but does not calibrate probabilities. Can proper scoring rules (Brier/log loss on match outcomes) improve calibration?
- Scalability and cost–benefit analysis: The method’s claimed data efficiency lacks a costed comparison vs strong SFT baselines with data augmentation or synthetic data. What is the Pareto frontier of (compute, data, performance)?
Collections
Sign up for free to add this paper to one or more collections.