- The paper demonstrates that SFT creates pseudo reasoning paths which limit genuine multimodal reasoning in LVLMs.
- It introduces a GRPO-based RL approach using mixed rewards to integrate perceptual and cognitive signals effectively.
- The VLAA-Thinking dataset provides robust, multimodal challenges that pave the way for future advancements in LVLM training.
Training R1-Like Reasoning Large Vision-LLMs: SFT vs RL
Introduction
The paper "SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-LLMs" (2504.11468) investigates the prevalent paradigm of supervised fine-tuning (SFT) followed by reinforcement learning (RL) for developing reasoning capabilities in Large Vision-LLMs (LVLMs). It challenges the notion that SFT invariably benefits subsequent RL by pointing out the formation of "pseudo reasoning paths" during SFT that mimic expert models but are often less informative and incorrect. The authors present VLAA-Thinking, a comprehensive dataset crafted to facilitate visual reasoning, and introduce a mixed reward module within Group Relative Policy Optimization (GRPO) to develop genuine reasoning capabilities in LVLMs.
The VLAA-Thinking Dataset
VLAA-Thinking contains two segments: VLAA-Thinking-SFT, for pseudo-reasoning path imitation through SFT, and VLAA-Thinking-RL, for challenging RL learning. Its construction involves a meticulous six-step pipeline: metadata collection, visual captioning, DeepSeek-R1 distillation, rewriting for fluency, verification for accuracy, and split curation. The dataset provides high-quality reasoning traces and challenges existing LVLMs by mixing simple and intricate reasoning tasks across various modalities.

Figure 1: Initial reasoning traces generation through caption and question input into DeepSeek-R1, refined for fluency and verified using GPT-based methods.
Revisiting Supervised Fine-Tuning
The study reveals significant limitations of SFT, indicating that while it improves alignment and learning specific reasoning formats, SFT restricts models to imitative paths that impede deeper reasoning. Experiments demonstrate that SFT alone can degrade performance, with more data sometimes worsening outcomes. The findings imply that larger models do not necessarily counteract these issues, emphasizing the need for alternative training strategies to develop authentic reasoning abilities.
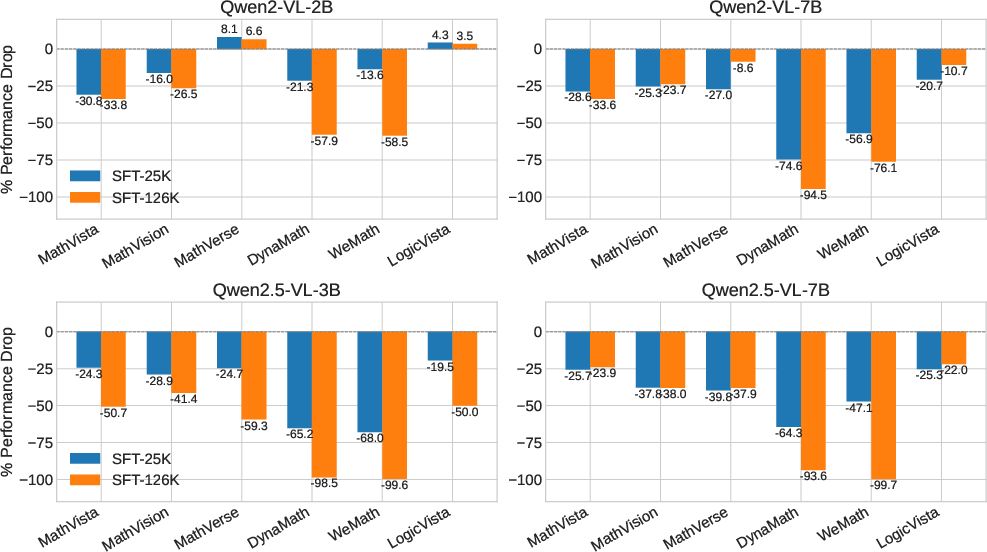
Figure 2: Percentage performance change of models trained with supervised fine-tuning (SFT) only.
Reinforcement Learning with Mixed Rewards
To address these limitations, the paper leverages GRPO with mixed rewards, integrating perception and cognition signals. The RL approach employs complex reward structures encompassing rule-based tasks like math expression matching and open-ended tasks using competent reward models. This design optimizes LVLMs' reasoning capability, outperforming models that rely solely on SFT.
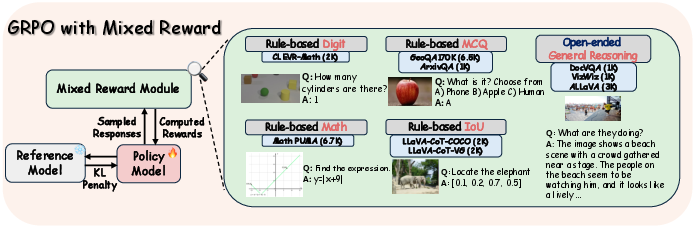
Figure 3: Mixed Reward Module incorporates various reward formats and types for multimodal GRPO training.
Effect of SFT on GRPO Training
The study further explores SFT's compatibility with GRPO, finding that even smaller SFT datasets can impair GRPO's effectiveness in multimodal contexts. Results challenge the assumption that longer response lengths correlate with higher rewards and indicate that more efficacious reasoning can emerge directly from well-implemented RL processes. Models trained using GRPO without preceding SFT demonstrate significant improvements over baseline models.
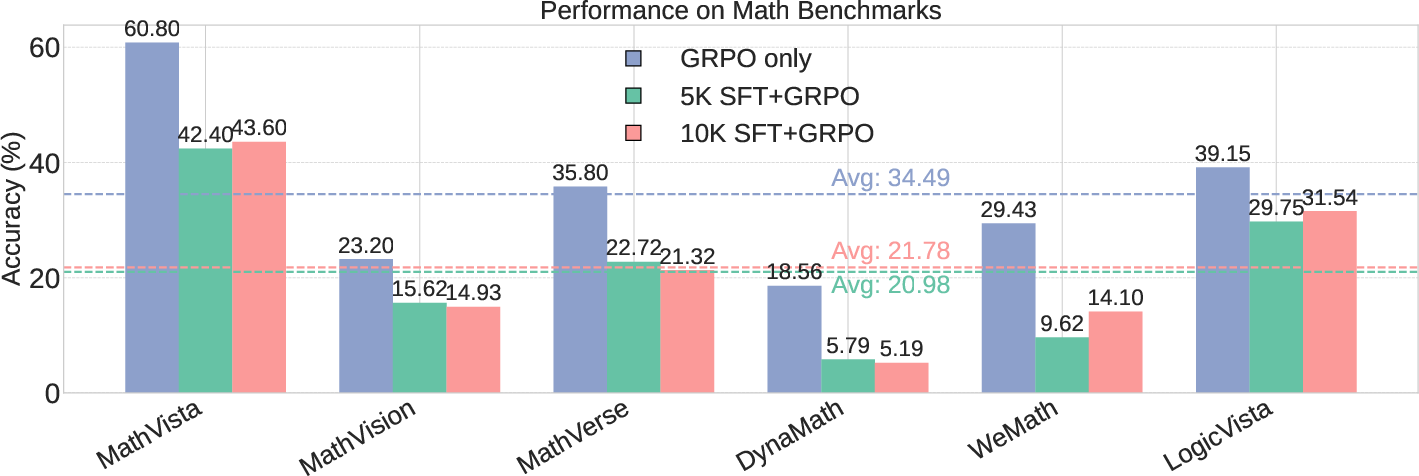
Figure 4: Impact of SFT size on GRPO performance indicates persistent degradation.
Conclusion
The paper concludes that reasoning in LVLMs is better developed through GRPO-driven RL than SFT-initiated pathways. It provides important insights into training paradigms, suggesting RL as a native avenue for evolving reasoning capabilities. The findings advocate a shift away from traditional SFT-first methodologies towards more exploratory reward-based RL approaches, providing a framework for future LVLM enhancement. The release of VLAA-Thinking offers a robust dataset for continued research in this domain, supporting the inherent adaptability and genuine reasoning in LVLMs.
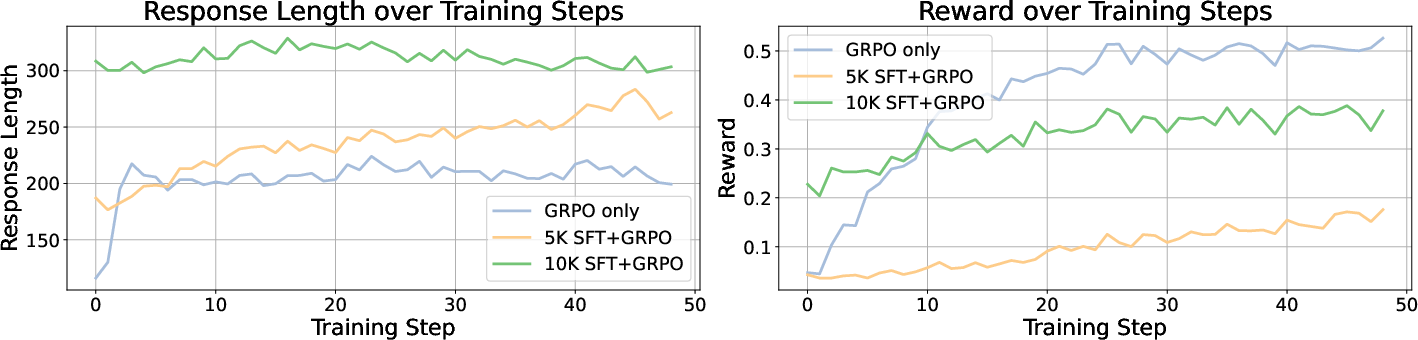
Figure 5: GRPO-trained models achieve high rewards regardless of response length variation during training.
These insights have vital implications for LVLM development, providing a new direction for cultivating advanced multimodal reasoning with flexible and comprehensive training methodologies.