- The paper introduces the ReLIFT framework, which interleaves reinforcement learning with online fine-tuning to enhance LLM reasoning on the hardest questions.
- The study demonstrates that fine-tuning with high-quality CoT solutions significantly outperforms standard RL on challenging problems while reducing response length.
- Experimental results reveal a +5.2 accuracy improvement and more concise reasoning paths in competition-level math and out-of-distribution tasks using ReLIFT.
Summary of "Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions"
Introduction
The paper entitled "Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions" (2506.07527) addresses the limitations inherent in reinforcement learning (RL) when applied to LLMs, particularly in the context of reasoning tasks. RL has shown success in improving models' capabilities via strategies like policy optimization, yet it tends to optimize based on the pre-existing knowledge rather than acquiring new information necessary for solving novel or complex problems. In contrast, supervised fine-tuning (SFT) can introduce new reasoning patterns by leveraging high-quality demonstration data but is limited by data availability and generalization challenges. The paper proposes ReLIFT (Reinforcement Learning Interleaved with Online Fine-Tuning), a synergistic approach that combines RL and SFT to address these challenges, optimizing models to learn beyond their initial scope.
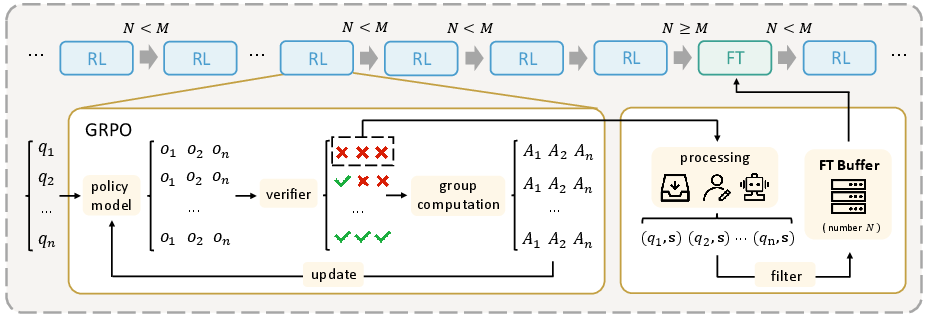
Figure 1: Overview of the ReLIFT Training Framework. The model is mainly trained with RL. When it encounters particularly hard questions, high-quality solutions are collected or generated, then stored in a buffer. Once enough hard examples are gathered, a fine-tuning (FT) step is performed using these examples.
Reinforcement Learning vs. Supervised Fine-Tuning
The study highlights the contrasting strengths of RL and SFT across question difficulty levels. RL efficiently maintains performance on questions within the model's capabilities, as demonstrated by OpenAI-o1~\cite{openai-o1}, DeepSeek-R1~\cite{deepseek_r1}, and Kimi-1.5~\cite{kimi1.5}. However, when faced with harder questions, RL's effectiveness diminishes. SFT, leveraging high-quality data, provides substantial improvements on the most challenging questions. These observations suggest that RL is optimal for easier questions while SFT excels in difficulties beyond the model's inherent capabilities, motivating the integration in ReLIFT.
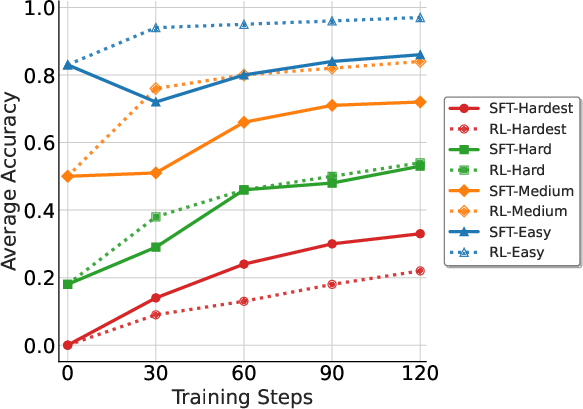
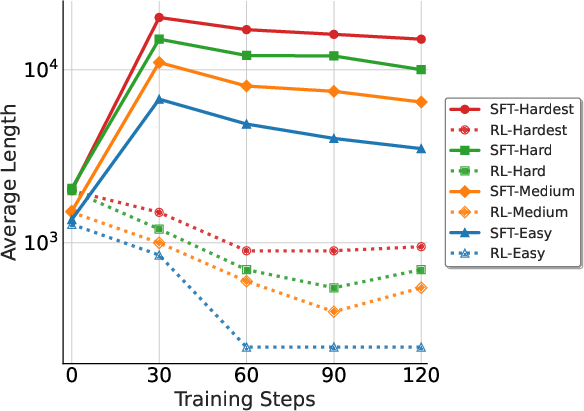
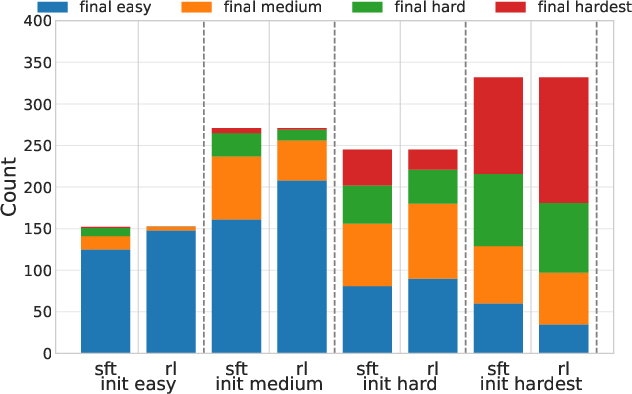
Figure 2: Average Accuracy.
The ReLIFT Approach
ReLIFT introduces an adaptive training paradigm, interleaving RL with fine-tuning exclusively on the hardest questions. During RL training, the model identifies particularly challenging examples based on rollout accuracy. High-quality CoT solutions are curated or generated for these examples, and the training process alternates between RL and SFT. This alternation helps the model integrate new information effectively, providing improvements in reasoning capabilities and efficiency, demonstrated by a reduction in average response length.
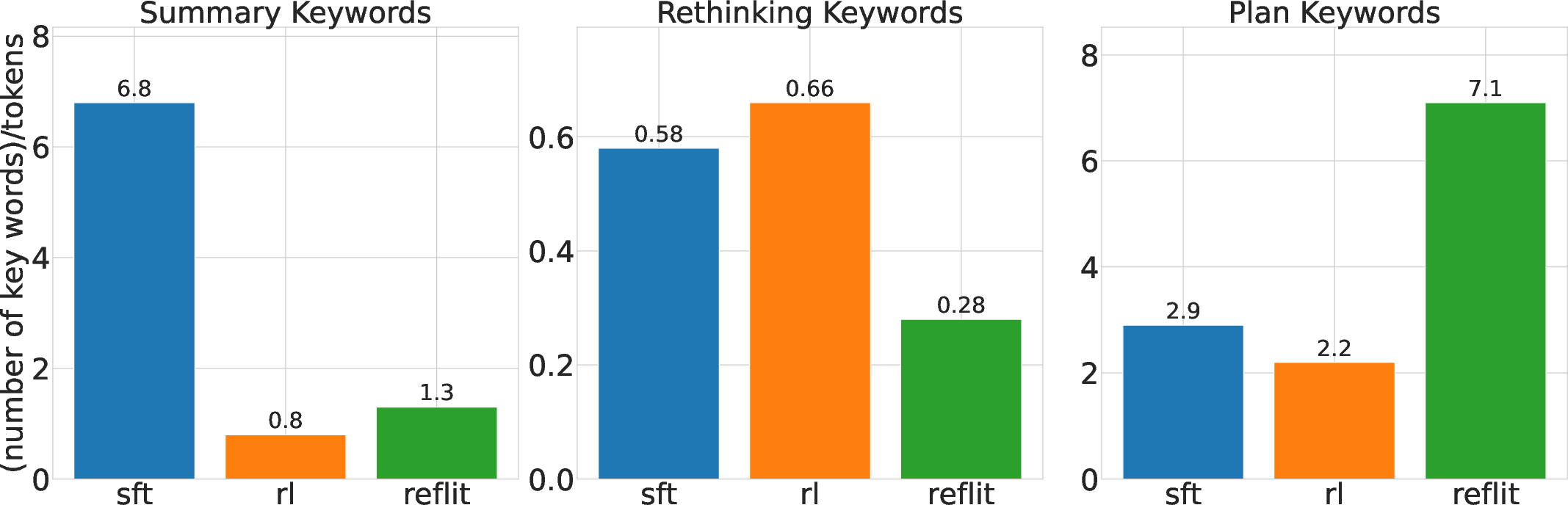
Figure 3: Normalized Keyword Counts for RL, SFT, and ReLIFT Models on AIME25.
Experimental Results & Analysis
Various models, including Qwen2.5-Math-7B, were benchmarked against five competition-level math reasoning tasks and one out-of-distribution task. ReLIFT achieved superior accuracy improvement (+5.2 points) over baseline methods without extensive data requirements, thus setting a new state-of-the-art. Furthermore, ReLIFT demonstrated more concise reasoning paths substantially shortening average response length compared to SFT.
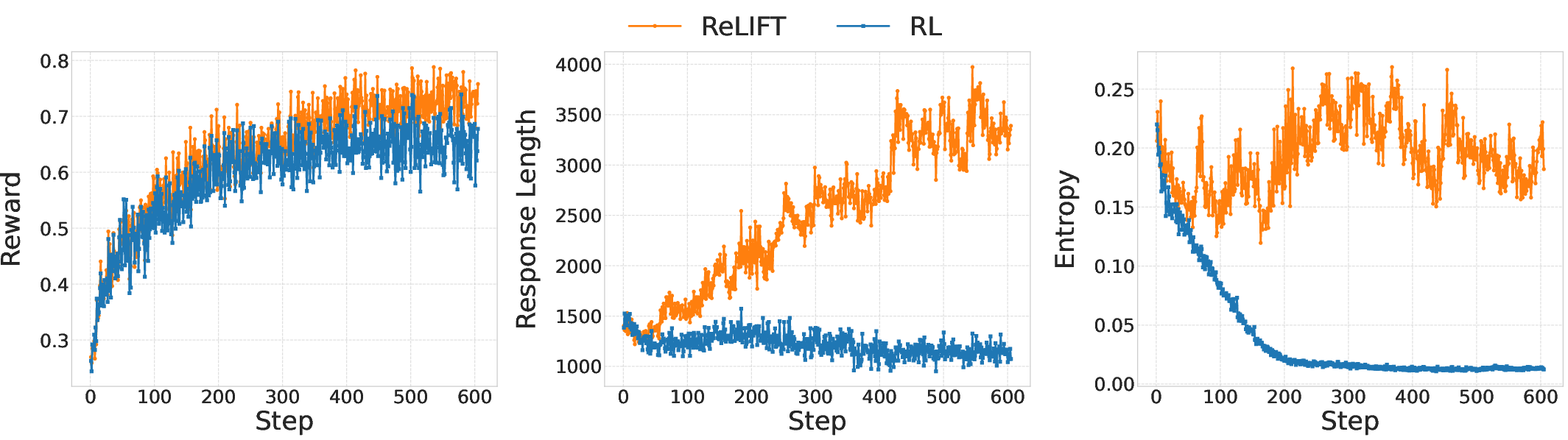
Figure 4: Training Dynamic of rewards, response lengths, and the training entropy during RL and ReLIFT training.
Implications and Future Work
ReLIFT's demonstrated capacity to outperform traditional RL and SFT paradigms using reduced demonstration data heralds new potential for scalable and effective LLM training methodologies. The paper's analysis highlights the complementary strengths of RL and SFT, emphasizing the importance of dynamically interleaving these methodologies based on data characteristics and model performance. Future research may expand ReLIFT's application to larger models and explore adaptive strategies for further optimizing the integration between RL and SFT, aiming to continually enhance LLM reasoning abilities and generalization.
Conclusion
The ReLIFT framework presents a compelling advancement in overcoming RL's limitations using adaptive fine-tuning strategies. As the field moves forward, such hybrid approaches can significantly boost the reasoning capabilities of LLMs, further bridging the gap between current cognitive constraints and smarter autonomous systems. This study establishes foundational methodologies with the potential to evolve AI's abilites particularly in complex reasoning tasks, offering new directions for training protocols that extend beyond existing paradigms.

