- The paper demonstrates that compact MLP-Mixer models with High-Granularity Quantization and Distributed Arithmetic outperform state-of-the-art designs by significantly reducing resource usage and latency.
- The methodology leverages non-permutation-invariant architectures and top-N particle ordering to enable precise bitwidth tuning and FPGA-friendly inference with sub-100 ns latencies.
- Empirical results reveal that the MLP-Mixer achieves comparable or better accuracy than baselines while using up to 97% fewer LUTs and dramatically lowering computational demands.
Fast Jet Tagging with MLP-Mixers on FPGAs: An In-Depth Analysis
Motivation and Problem Statement
The Level-1 trigger (L1T) systems of LHC experiments require real-time decision-making under O(1μs) latency constraints, demanding powerful yet highly resource-efficient classifiers deployable on FPGAs. Jet tagging—classifying jets by origin (e.g., gluons, quarks, W, Z, top)—is critical for downstream physics, but standard architectures such as GNNs or Transformers are computationally prohibitive at L1. Previous hardware-aware models provide partial solutions; however, achieving a superior latency/accuracy/resource Pareto front while exploiting hardware characteristics remains an open task.
Dataset and Model Design
An LHC-like five-class jet dataset serves as the benchmark, leveraging up to 150 particles per jet and 16 per-particle features. The distribution of particles per jet, and the effect of pT thresholding, is provided for realism.
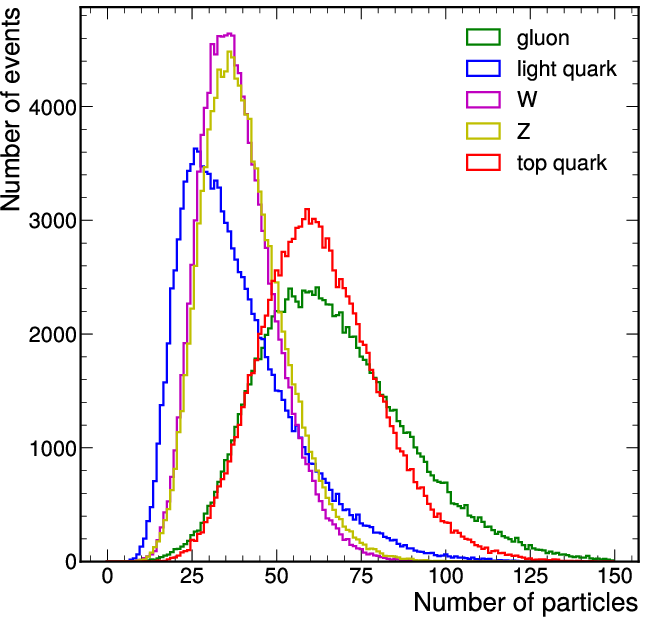
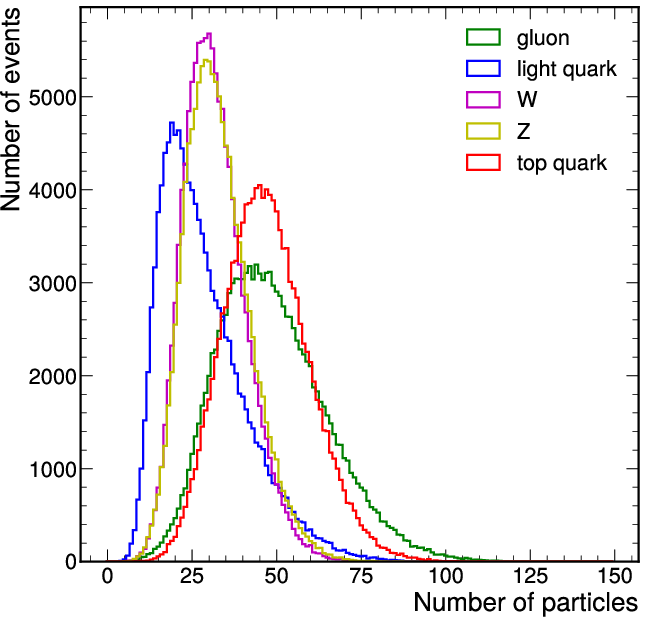
Figure 1: Distribution of the number of particles per jet in the jet tagging dataset, with and without a pT threshold.
The paper introduces compact, trigger-oriented MLP-Mixer models that ingest sequences of particle features, diverging from standard permutation-invariant designs. Inputs are top-N particles ordered by pT to reflect practical firmware constraints and maximize the benefit of hardware-aware quantization.
The architecture follows the MLP-Mixer principle—alternate feature-wise and particle-wise linear transformations, but with only two mixer stages and reduced channel sizes for FPGA feasibility.
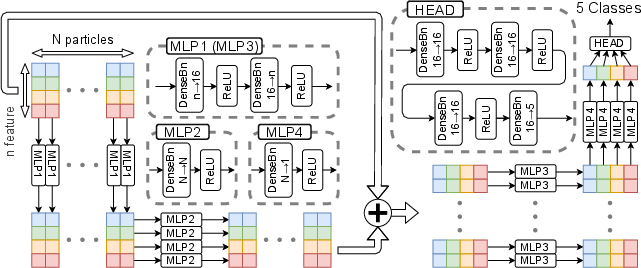
Figure 2: Compact MLP-Mixer architecture: four MLP blocks, a skip connection, and a fusion of dense and BN layers tailored for FPGA deployment.
Efficient Hardware Implementation: Quantization, Optimization, and Deployment
The models employ High-Granularity Quantization (HGQ), which uniquely enables per-parameter bitwidth tuning and unstructured pruning via surrogate gradient optimization, far surpassing layer-wise QAT in resource reduction and compression effectiveness. Distributed Arithmetic (DA) further transforms linear layers into hardware-friendly adder/shift networks, eliminating resource-heavy DSP utilization.
The deployment workflow integrates quantization, pruning, and DA into hls4ml/Vitis HLS for bit-accurate inference on FPGA.
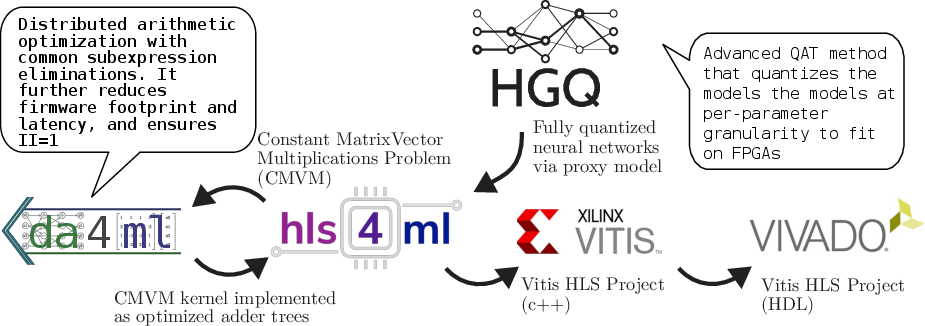
Figure 3: End-to-end workflow for MLP-Mixer training, high-granularity quantization, firmware generation, and final FPGA synthesis.
Empirical Results
Accuracy and Model Efficiency
Full-precision MLP-Mixer models outperform the state-of-the-art JEDI-net baseline across all classes in AUC, even with fewer parameters and lower FLOPs, with the best Np=64 variant yielding the highest scores.
Significant results include:
- MLP-Mixers achieve comparable or better accuracy than JEDI-net while requiring only O(103) parameters and sub-O(105) FLOPs, compared to JEDI-net's O(104) parameters and O(108) FLOPs.
- Increasing input particles improves performance up to saturation at Np=64, highlighting efficient utilization of input information.
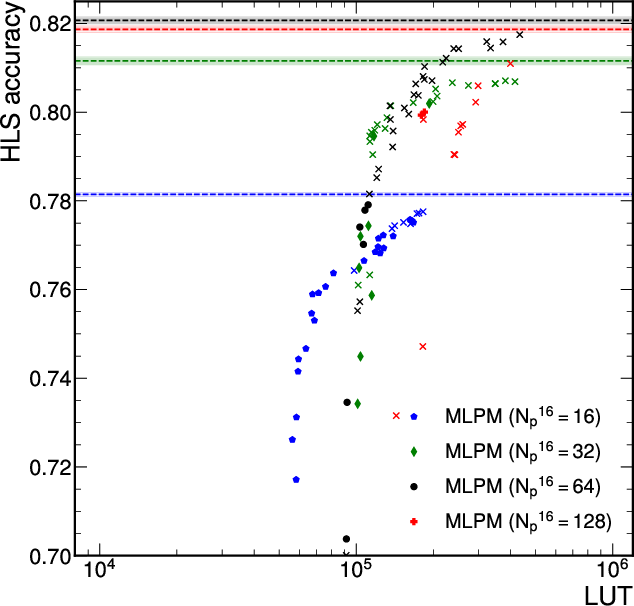
FPGA Resource Utilization and Latency
Quantized, DA-optimized MLP-Mixers set new benchmarks for accuracy/resource/latency trade-offs, fully exploiting LUT-based inference with zero DSP usage, and consistently achieving sub-100 ns latencies and >107 jets/s throughput.
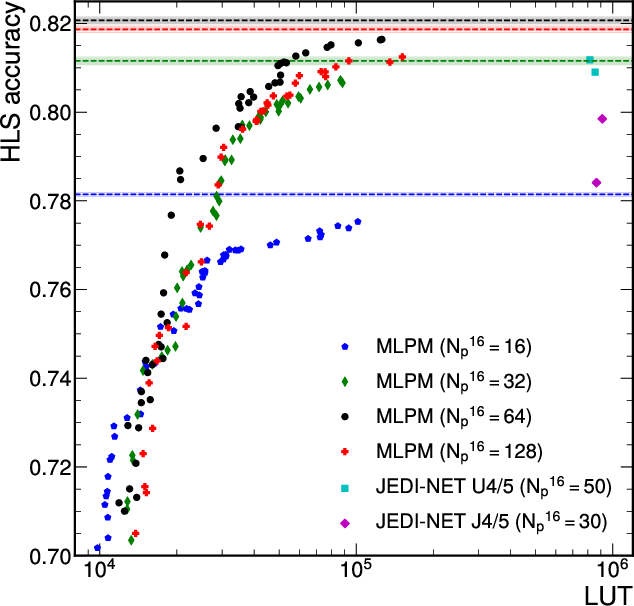
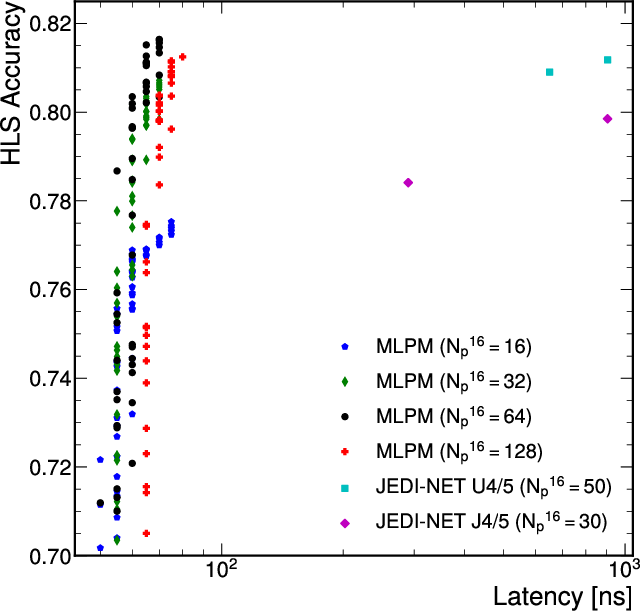
Figure 4: Accuracy-resource-latency Pareto front for quantized MLP-Mixer and JEDI-net models; MLP-Mixer is strictly superior.
Feature Selection and Interpretability
Analysis of per-channel and per-particle bitwidths reveals that HGQ enables the model to prioritize high-salience features and discard noise adaptively. For example, more bits are dedicated to kinematic variables and high-pT particles, in alignment with domain knowledge and physical constraints.
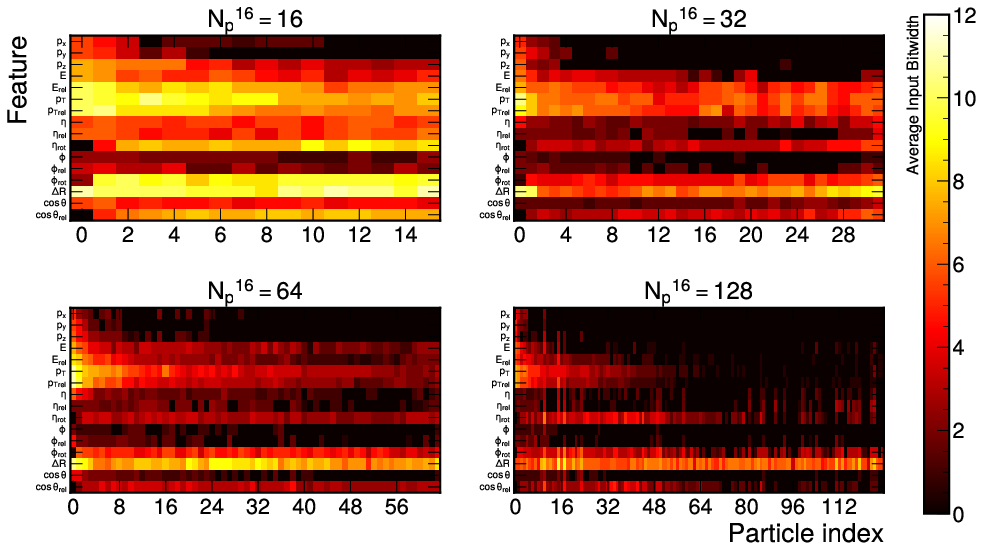
Figure 6: Layerwise average input bitwidths showcase data-driven selective quantization and dynamic feature prioritization capabilities of the HGQ-trained MLP-Mixer.
Architectural and Algorithmic Implications
- Breakdown of permutation invariance is critical for hardware Pareto improvement, leveraging low-level trigger ordering guarantees to enable aggressive quantization and selective attention.
- The direct mapping of mixer computations to DA further unlocks resource and latency reductions across all major FPGA families, a substantial advance over previous QAT and pruning approaches.
- Comparative ablations demonstrate that even MLP baselines can outperform legacy FPGA-targeted Interaction Network and Deep Sets models when equipped with DA and HGQ.
Broader Significance and Future Perspectives
The deployment of MLP-Mixers with HGQ and DA establishes a new reference for edge AI in collider triggers, simultaneously maximizing inference throughput and minimizing power and hardware overheads without substantial accuracy compromise. These approaches generalize beyond HEP: selective quantization and non-permutation-invariance are broadly applicable for event sequence processing at the hardware edge (e.g., for rapid vision, audio, or anomaly detection at sensor frontends).
The results also inform architectural co-design: ensuring firmware-level data orderings, integrating adaptive quantization and DA in tooling, and customizing training for physical hardware cost functions. Additional gains are anticipated via more targeted regularization, co-optimized DA logic mapping, and fine-grained per-particle kernel differentiability.
Conclusion
MLP-Mixers, when co-designed with high-granularity quantization and distributed arithmetic, achieve a superior accuracy-latency-resource trade-off to all previous FPGA-deployable models for online jet tagging. The results demonstrate that exploiting architectural non-invariance, adaptive bitwidth allocation, and optimized arithmetic are critical for sustaining performance under extreme resource and real-time constraints.
This methodology portends practical impact on trigger upgrades and provides a reference for efficient, interpretable, and truly hardware-aware neural inference in other low-latency scientific and industrial applications.