CLIP is Strong Enough to Fight Back: Test-time Counterattacks towards Zero-shot Adversarial Robustness of CLIP
Abstract: Despite its prevalent use in image-text matching tasks in a zero-shot manner, CLIP has been shown to be highly vulnerable to adversarial perturbations added onto images. Recent studies propose to finetune the vision encoder of CLIP with adversarial samples generated on the fly, and show improved robustness against adversarial attacks on a spectrum of downstream datasets, a property termed as zero-shot robustness. In this paper, we show that malicious perturbations that seek to maximise the classification loss lead to `falsely stable' images, and propose to leverage the pre-trained vision encoder of CLIP to counterattack such adversarial images during inference to achieve robustness. Our paradigm is simple and training-free, providing the first method to defend CLIP from adversarial attacks at test time, which is orthogonal to existing methods aiming to boost zero-shot adversarial robustness of CLIP. We conduct experiments across 16 classification datasets, and demonstrate stable and consistent gains compared to test-time defence methods adapted from existing adversarial robustness studies that do not rely on external networks, without noticeably impairing performance on clean images. We also show that our paradigm can be employed on CLIP models that have been adversarially finetuned to further enhance their robustness at test time. Our code is available \href{https://github.com/Sxing2/CLIP-Test-time-Counterattacks}{here}.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a smart AI model called CLIP that can match pictures with text, even for categories it wasn’t trained on. That’s called “zero-shot” because it needs zero extra training to recognize new things. The problem is, CLIP can be tricked by tiny, invisible changes to images (called adversarial attacks). The paper’s big idea is simple: use CLIP itself, at test time, to fight back against those attacks without retraining the model.
Key Questions the Paper Asks
- Can we protect CLIP from sneaky, tiny image edits that try to fool it?
- Is there a way to do this quickly, at the moment we use the model, without any extra training or helper networks?
- Can we keep CLIP accurate on normal, clean images while defending against attacks?
- Will this work across many types of image tasks and also help models that were already trained to be robust?
How the Method Works (In Simple Terms)
First, a quick picture of the problem:
- CLIP “thinks” about images and texts by placing them in an internal map (an “embedding space”). Similar things end up close together on that map.
- Adversarial attacks make tiny, hard-to-see changes to an image so CLIP places it in the wrong spot on the map, leading to a wrong label.
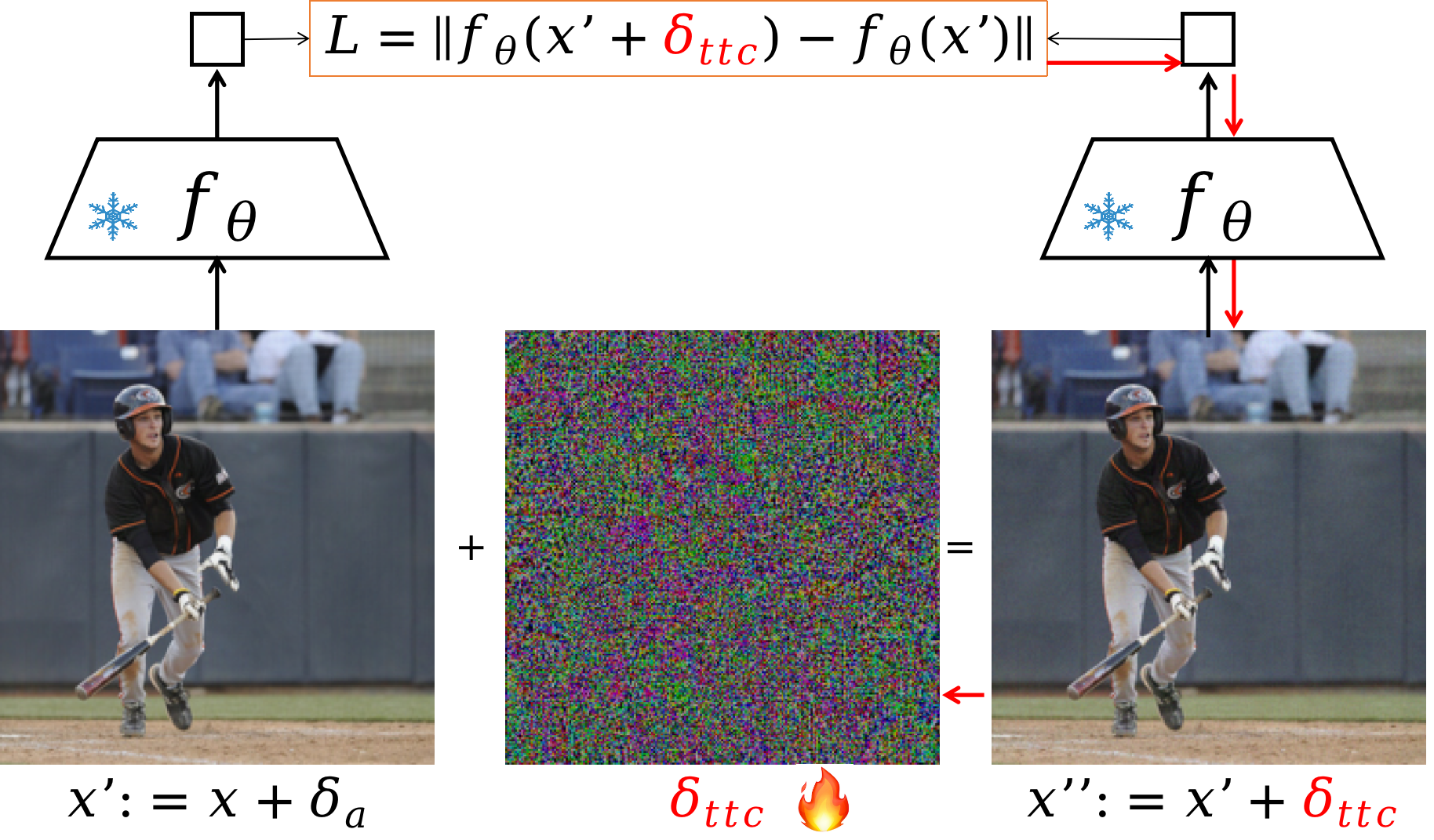
The paper’s defense is called Test-time Counterattacks (TTC). Here’s the idea using everyday language:
- Imagine the attacked image has been pushed into a sticky trap on CLIP’s internal map. When you poke it gently (add small random noise), it barely moves. The authors call this “false stability.”
- For a normal (clean) image, a tiny poke makes its position shift a little, as you’d expect. For an attacked image, the same poke hardly changes anything—like it’s stuck.
The defense has two parts:
- Detect the trap with a quick poke
- They add a very small random wiggle to the image and measure how much the image’s position in CLIP’s map moves.
- If it barely moves, it might be under attack (“falsely stable”). If it moves normally, it’s probably clean.
- Nudge the image out of the trap
- If the image seems attacked, they add a carefully chosen, tiny adjustment that pushes the image away from its current stuck position on the internal map.
- They do this in a few small steps, each step staying within strict limits so the image isn’t changed too much. This “few careful nudges within a safe boundary” is similar to how you might steadily steer a car out of mud without spinning the wheels.
- They also give a bit more importance to later steps, which often make the most helpful corrections.
- If the initial poke suggests the image is fine, they stop early to avoid hurting performance on clean images. This is the “τ-threshold” idea: only do the full rescue if the image looks stuck.
Key technical terms translated:
- Embedding: CLIP’s internal representation of an image (its position on an internal map).
- “Distance” in embedding space: how far two positions are on that map; bigger distance means more different.
- PGD (Projected Gradient Descent): a method that takes multiple tiny, careful steps to improve something while staying inside a safety boundary.
No retraining required, no extra models—just a quick, smart fix at test time.
Main Findings and Why They Matter
Here are the main takeaways from tests on 16 different image datasets:
- Big boosts in defense: TTC made CLIP much more robust to attacks that try to maximize classification errors. It worked better and more consistently than other test-time defenses that don’t use extra networks.
- Little harm to clean images: Accuracy on normal images stayed almost the same, with only small drops in some cases.
- Works across many tasks: The method improved results on a wide range of datasets (animals, objects, scenes, textures, etc.).
- Helps strong models too: Even when CLIP had already been adversarially fine-tuned (trained to be tougher), adding TTC on top often improved robustness further.
Why this matters:
- In real life, you don’t always have time or permission to retrain a giant model like CLIP. A simple, “just-in-time” defense that you can switch on when you use the model is very practical.
- It shows that big pre-trained models have hidden strengths we can tap into—if we use them the right way, they can help protect themselves.
What This Could Mean Going Forward
- Practical safety: TTC is training-free and fast, making it easier to defend deployed models in apps, websites, or devices without rebuilding them.
- Plug-and-play: It can wrap around CLIP (and likely similar models) as a lightweight defense.
- Better understanding of attacks: The “false stability” idea gives a new way to spot when an image has been cleverly trapped by an attacker.
- Not a silver bullet: This method is designed for a common kind of attack (ones that push classification loss up). Very advanced attackers might adapt, and there can be a small accuracy trade-off on clean images. Still, it’s a strong, simple step toward safer AI systems.
In short: The paper shows a clever, easy-to-use way for CLIP to “fight back” at test time—by detecting when an image is stuck in an adversarial trap and gently nudging it out—leading to much stronger performance under attack with minimal downsides.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, formulated to guide concrete next steps for future research.
- Adaptive attacker evaluation
- No evaluation against fully adaptive, white-box attackers aware of the defense (e.g., incorporating TTC into the computation graph via BPDA/EOT, AutoAttack with defense-aware settings). Assess whether TTC induces gradient obfuscation and whether robustness persists when attacks are tailored to the defense.
- Threat model realism and scope
- The defense assumes the attacker does not know the user’s test-time operations. Quantify robustness under stronger assumptions (attacker knows/approximates TTC, including τ-thresholding and weighting) and under black-box query-limited attacks.
- Explore physical-world attacks, adversarial patches, unrestricted attacks, low-frequency/semantic perturbations, and text-side (prompt) attacks that are common in VLM settings.
- Attack diversity and evaluation rigor
- Robustness is reported primarily for 10-step PGD (and briefly CW in the appendix). Evaluate with stronger and standardized suites (e.g., AutoAttack, multi-restart PGD with >100 steps, step-size schedules, EOT for randomized defenses, transfer attacks).
- Provide sanity checks for non-obfuscated robustness (monotonic accuracy degradation with increasing ε and steps, gradient-free attacks, random restarts, loss landscape probes).
- Defense visibility and composability
- Analyze to what extent TTC can be embedded in deployment pipelines where defense operations must be visible/auditable. Study interactions when attackers optimize end-to-end through TTC or when defenses must be stateless or non-differentiable.
- Anchor definition ambiguity
- The method “uses the original image embedding fθ(x) as anchor,” but in realistic scenarios the defender receives a possibly adversarial input x′. Clarify whether the anchor is computed from x′, from an estimate of clean x, or from auxiliary views; quantify the impact of each choice on robustness and clean performance.
- Theoretical grounding of “false stability”
- Formalize and prove properties of the “false stability” phenomenon beyond empirical evidence. Characterize when and why maximizing classification loss traps embeddings in “toxic surroundings,” and whether this generalizes across model architectures, norms, and attack objectives.
- Objective design and representation choice
- Justify L2 distance in the final image embedding as the maximization target. Compare against cosine/geodesic distances, multi-layer feature distances, text-conditioned anchors, or multi-augmentation anchors; study which yields the best robustness–fidelity trade-off.
- Hyperparameter selection and robustness
- Provide systematic, defense-agnostic procedures for setting τ_threshold, β, step size, number of steps N, and ε_ttc that generalize across datasets and models without per-dataset tuning. Quantify sensitivity and failure modes when mis-specified.
- Clean accuracy degradation and gating
- Clean accuracy drops vary substantially across datasets (e.g., notable on ImageNet, SUN397, OxfordPets). Develop principled per-sample gating or confidence-based mechanisms (beyond a fixed τ) to minimize harm on clean inputs, and characterize the Pareto frontier of robustness vs. accuracy.
- Perceptual quality and user constraints
- Although the defense perturbation “need not be imperceptible,” practical deployments often require preserving visual fidelity. Measure perceptual impact (e.g., LPIPS, SSIM, human studies), test lower ε_ttc regimes, and explore perceptual constraints or in-display transformations.
- Computational and latency cost
- No analysis of runtime/latency and throughput overhead vs. baselines (e.g., TTE). Profile compute cost across N, image resolution, and model size; study real-time feasibility and energy implications for edge devices.
- Generalization beyond zero-shot classification
- The evaluation is limited to closed-set classification. Test TTC on open-vocabulary classification, retrieval, multi-label classification, detection, and segmentation to validate broader applicability to VLM use cases.
- Model and backbone diversity
- Results focus on one CLIP configuration. Evaluate across multiple CLIP backbones (RN50, ViT-B/L/14, OpenCLIP variants) and other VLMs (e.g., ALIGN, BLIP, Florence) to substantiate the “easily applicable to other VLMs” claim.
- Interaction with adversarial finetuning
- TTC yields modest gains on supervised AFT (e.g., TeCoA, PMG-AFT) possibly due to reduced expressiveness post-AFT. Systematically study co-design strategies (e.g., regularizers that preserve feature sensitivity, joint training with TTC-aware losses) and how data choice, ε, and supervised vs. unsupervised AFT affect TTC efficacy.
- Universality and calibration of τ-thresholding
- The paper states τ_threshold depends only on τ of clean images and random noise strength, but does not validate cross-dataset, cross-model, and cross-preprocessing stability. Provide calibration protocols that avoid dataset-specific tuning and quantify false-positive/false-negative rates in gating.
- Norms and perturbation models
- Attacks are predominantly L∞-bounded; TTC maximizes L2 in embedding space. Evaluate robustness under L2/L1/LPIPS-bounded attacks and corruptions (e.g., ImageNet-C), and study whether alternative defense objectives better match diverse threat models.
- Prompting and text-side defenses
- CLIP performance is sensitive to prompt engineering, but the defense uses a single prompt template and does not interact with adversarial prompt tuning. Explore joint image–text defenses, prompt ensembling, and robustness when the attacker manipulates text prompts.
- Distribution shift and OOD robustness
- Despite using many datasets, evaluations target in-distribution classification within each dataset. Assess robustness under distribution shift, OOD inputs, and class-imbalance scenarios, and whether τ gating or TTC exacerbates OOD errors.
- Fairness of defense vs. attack budgets
- TTC often uses ε_ttc ≥ ε_a. In scenarios where modifying inputs is constrained, defense budgets may be limited. Characterize defense performance when ε_ttc ≤ ε_a, and propose constrained or transformation-based countermeasures.
- Certified guarantees
- No certified (provable) robustness guarantees are provided. Investigate whether TTC can be integrated with certification frameworks or whether alternative objectives admit partial certificates.
- Failure case analysis
- Provide detailed qualitative/quantitative analyses of cases where TTC fails (e.g., certain classes/datasets), including how TTC perturbs semantics, when it causes label flips on clean samples, and whether specific content types are especially vulnerable.
- Deployment considerations
- Examine compliance and pipeline constraints (e.g., when inputs cannot be altered, or only metadata can be changed), robustness to compression/codec artifacts, and the impact of pre/post-processing mismatches between attacker and defender.
Collections
Sign up for free to add this paper to one or more collections.