- The paper demonstrates that targeted synthetic reasoning data and optimized architecture enable a sub-billion parameter model to achieve high-quality audio-text reasoning.
- The methodology integrates an HTSAT-based audio encoder with a fine-tuned SmolLM2 language model, outperforming far larger models on multimodal tasks.
- Empirical results show strong performance in audio understanding, deductive, and comparative reasoning, paving the way for resource-efficient edge deployment.
Mellow: A Compact Audio-LLM for Multimodal Reasoning
Introduction
Mellow (2503.08540) addresses the persistent challenge of equipping sub-billion-parameter Audio-LLMs (ALMs) with genuine reasoning capability over audio and text. Prior advances in ALMs have been achieved primarily by scaling both data and model size, with strong reasoning performance previously exclusive to models at or above the multi-billion parameter regime. Mellow disrupts this playbook by demonstrating that state-of-the-art reasoning—spanning multimodal audio understanding, deductive reasoning, and comparative reasoning—can be realized by careful architecture, synthetic reasoning-focused training data, and optimized model selection, all within 167M parameters and a fraction of the compute and data scale of contemporary models.

Figure 1: Left: Performance of diverse ALMs on MMAU vs parameter size; Mellow matches or surpasses models with over 50× its parameter count. Right: Examples covering Mellow’s reasoning capabilities.
Model Architecture
Mellow adopts a modular composition comprising an efficient HTSAT-based audio encoder, a carefully ablated non-linear projection (mapper), and fine-tuned SmolLM2 as the language core. The model is architected to jointly handle single- and dual-audio input settings, concatenated with a natural language prompt, to produce text outputs.
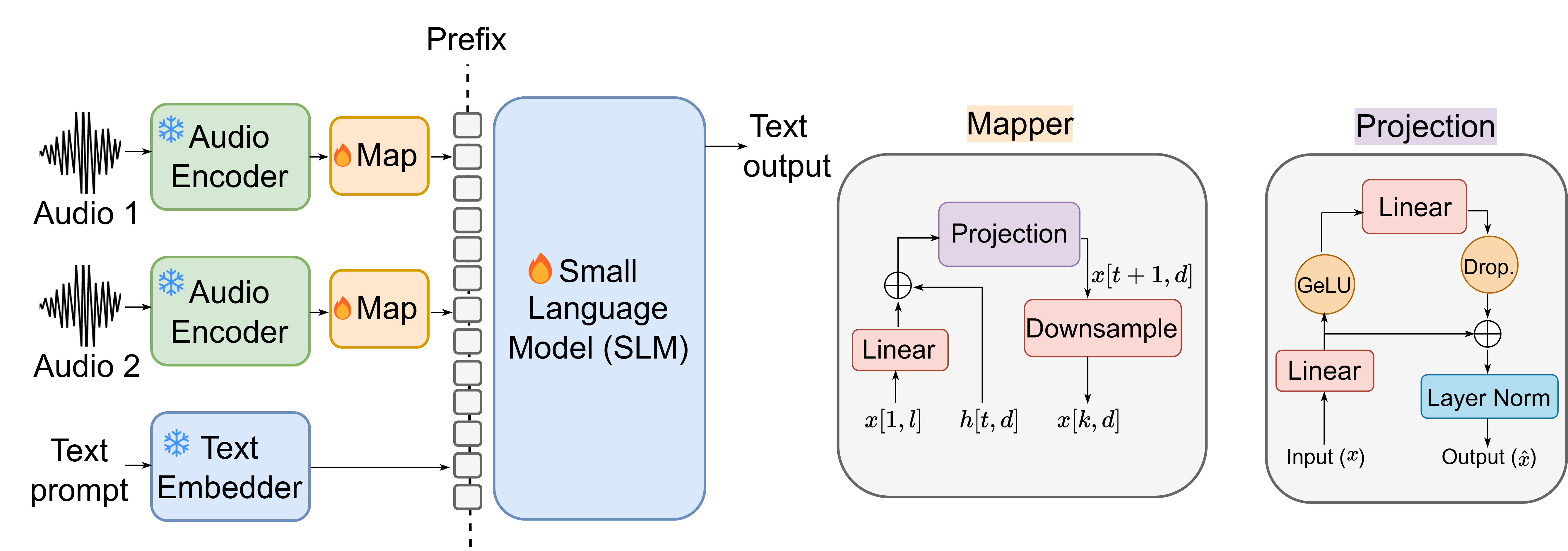
Figure 2: Mellow’s architecture for multimodal reasoning: Dual audio encoders, non-linear mapping, and unified prompt construction for conditioning the LLM.
Audio Encoder and Mapping
The audio encoder utilizes a Hierarchical Token Semantic Transformer (HTSAT) trained on AudioSet, delivering robust and temporally granular representations. The projection layer was extensively ablated: in the fine-tuned regime, simpler non-linear projections yielded comparable performance to large transformer-mappers, supporting a compute-efficient design without compromising cross-modal grounding.
LLM Backbone
SmolLM2, a state-of-the-art small LLM, is shown to significantly outperform GPT-2 for open-ended reasoning tasks when fine-tuned directly, a result confirmed in thorough ablations. Importantly, full LLM fine-tuning outperforms prefix-tuning and LoRA adaptations for audio-specific reasoning, although LoRA confers greater retention of generic world knowledge.
ReasonAQA: Synthetic Multimodal Reasoning Supervision
A critical enabler for Mellow's performance is the ReasonAQA dataset, which provides strong reasoning supervision absent in previous ALM corpora. ReasonAQA is constructed by leveraging audio captioning datasets (AudioCaps, Clotho), from which rich prompt-driven QA (both multiple-choice and detailed) pairs are generated using LLMs focused explicitly on sound events, scene composition, signal properties, and listener affect.
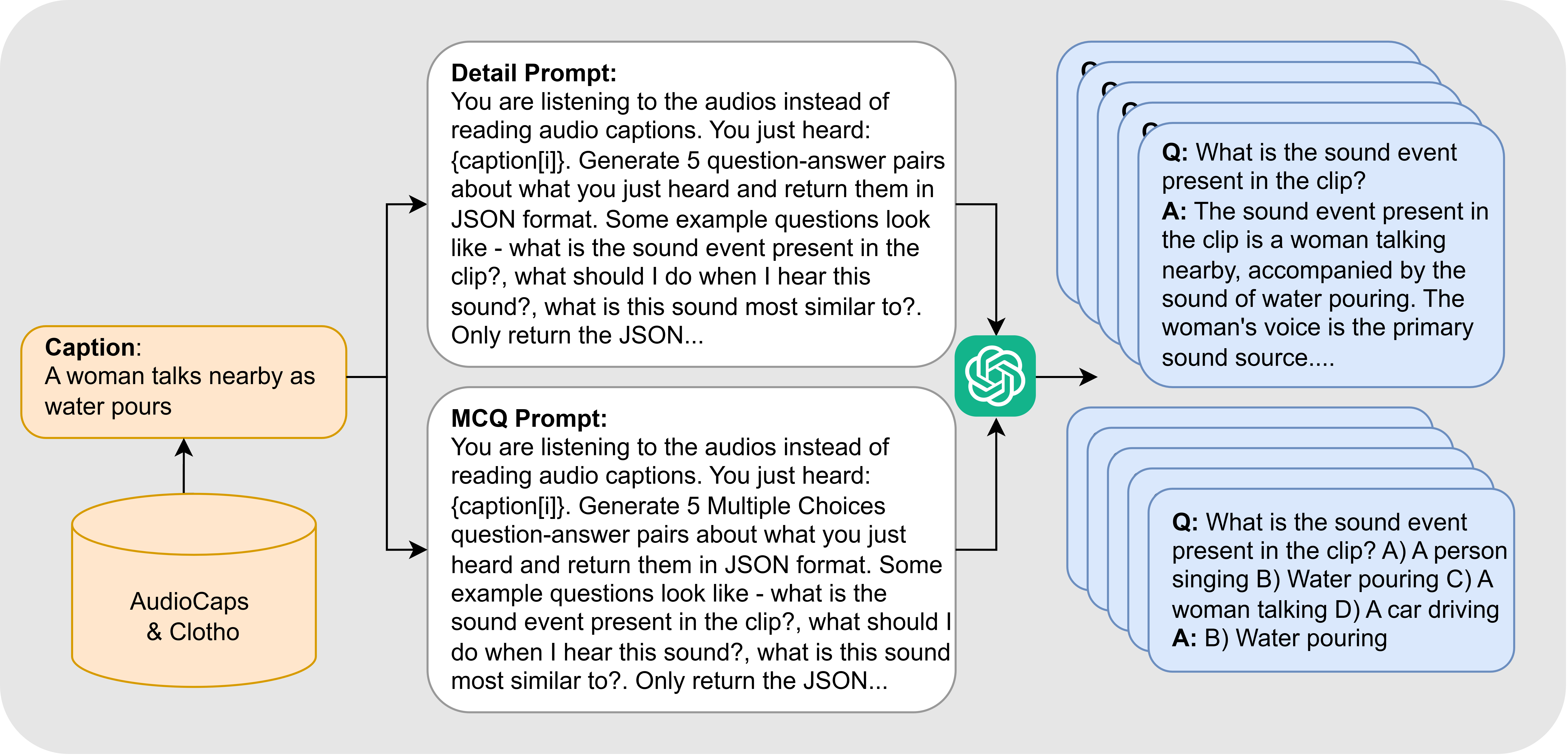
Figure 3: Data generation pipeline for ReasonAQA: LLM-generated prompts over diverse audio descriptions yield high-quality MCQ and open QA pairs.
A series of prompt ablations and vocabulary analyses (see Figures 4, 5, 7, and 8) confirm the synthetic data’s focus on inference, compositional reasoning, and deep audio grounding, resulting in a training set superior to prior open benchmark datasets in terms of reasoning specificity and diversity.
Empirical Evaluation Across Multimodal Reasoning Tasks
Mellow is systematically evaluated on a comprehensive battery of multimodal benchmarks, with direct comparisons to both small and large ALMs and LLMs that use audio captions as proxies for audio inputs.
Multimodal Audio Understanding and Reasoning (MMAU)
Mellow achieves 52.11 average accuracy on the MMAU benchmark, directly comparable to much larger models such as Qwen2 Audio (52.5, 50× more parameters and 60× more data), and superior to other compact ALMs by >30 absolute points. This marks a strong contradiction to the presumed necessity of massive scale for cross-modal reasoning robustness. Mellow’s robustness to out-of-distribution data is validated by the absence of audio overlap between training and MMAU evaluation.
Deductive Reasoning (Audio Entailment)
On audio entailment (CLE, ACE datasets), Mellow reaches 91.16% accuracy, surpassing both contrastive and generative ALMs, large (7B-13B) and small (<300M), regardless of finetuning or training objective. Mellow is particularly adept at clear-cut entailment and contradiction cases but still exhibits room for improvement on neutral cases, reflecting the general ALM difficulty with plausible-but-not-certain inference.
Comparative Reasoning (Audio Difference)
Mellow shows state-of-the-art comparative reasoning in distinguishing between dual audio inputs, outperforming prior small ALMs across most granularity tiers. Only on the linguistically easiest (Tier-2) tasks do larger LMs using full finetuning marginally exceed Mellow, attributed to richer language output rather than integrated perceptual reasoning.
Grounded Audio Captioning and Binary QA
Despite its small size, Mellow closely tracks or exceeds the performance of baseline LALMs on binary audio QA and achieves competitive SPICE scores for audio captioning (17.8, vs. Pengi’s 12.7), but is limited by its lack of large-scale concept coverage.
Ablation Analyses
Mellow’s design choices are validated by detailed ablation studies.
- LLM finetuning consistently outperforms prefix-tuning and LoRA by large margins for audio-centric reasoning, although LoRA may be advantageous when broad world knowledge must be retained.
- SmolLM2 as the backbone is essential: replacing GPT-2 with SmolLM2 results in improved open-ended reasoning, especially when generating detailed audio difference explanations.
- Audio encoder quality governs coverage: shifting from CNN14 to HTSAT increases coverage and downstream accuracy, but does not in itself add new reasoning patterns.
- Synthetic reasoning-focused data is critical: ReasonAQA’s explicit emphasis on inference and compositional audio-text relationships leads to clear benefits over datasets dominated by world-knowledge or repetitive/ambiguous QA pairs. Prompt design and choice of LLM for question generation further influence the depth and diversity of the dataset (see Figure 4 and Figure 5).
- Scaling data improves coverage but not inherent reasoning: Adding more audio concept data increases performance in coverage-limited domains (e.g., music), but improvements on pure reasoning tasks saturate rapidly, indicating architectural or supervision limits rather than data constraints.
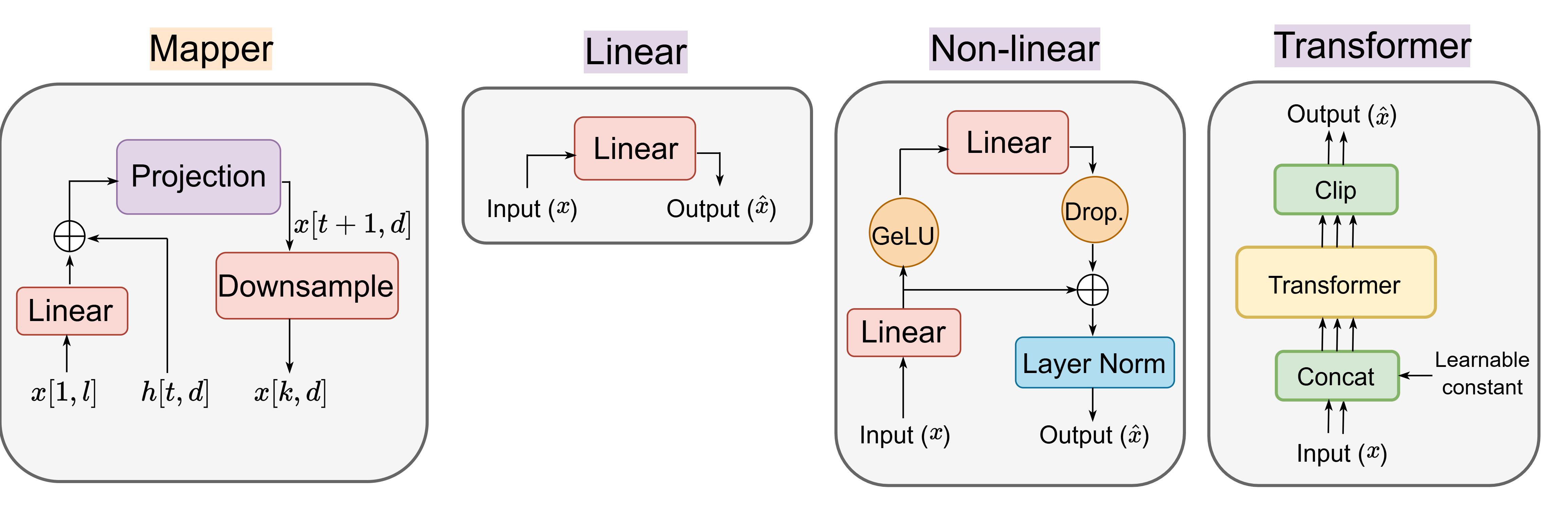
Figure 6: Projection layer design ablation: Linear, non-linear, and transformer-based mappers, with empirical results supporting minimal designs for fine-tuned SLMs.
Practical and Theoretical Implications
Mellow demonstrates that strong, practical multimodal reasoning is feasible on resource-constrained devices, paving the way for edge deployment of ALMs in privacy-sensitive or embedded audio-processing scenarios. The findings challenge previous assumptions regarding the necessity of massive models and motivate a re-examination of scaling laws and supervision strategies in cross-modal reasoning.
On the theoretical front, Mellow establishes the importance of (1) targeted synthetic data, (2) architecture-scaling complementarity, and (3) analysis tools for differentiating coverage gaps from reasoning deficits. The results imply that improvement paths for compact ALMs involve a mixture of high-leverage supervision and carefully tuned architecture, rather than brute-force data or parameter scaling.
Conclusion
Mellow sets a new standard for compact Audio-LLMs, delivering high-quality reasoning over audio and text at a fraction of the scale of current SoTA systems. It achieves this via an overview of optimized architecture, small but powerful language modeling, and reasoning-specific synthetic data. The strong empirical results and comprehensive ablation analysis reveal new possibilities for resource-efficient multimodal AI, extending the reach of ALMs beyond the cloud toward ubiquitous reasoning agents.
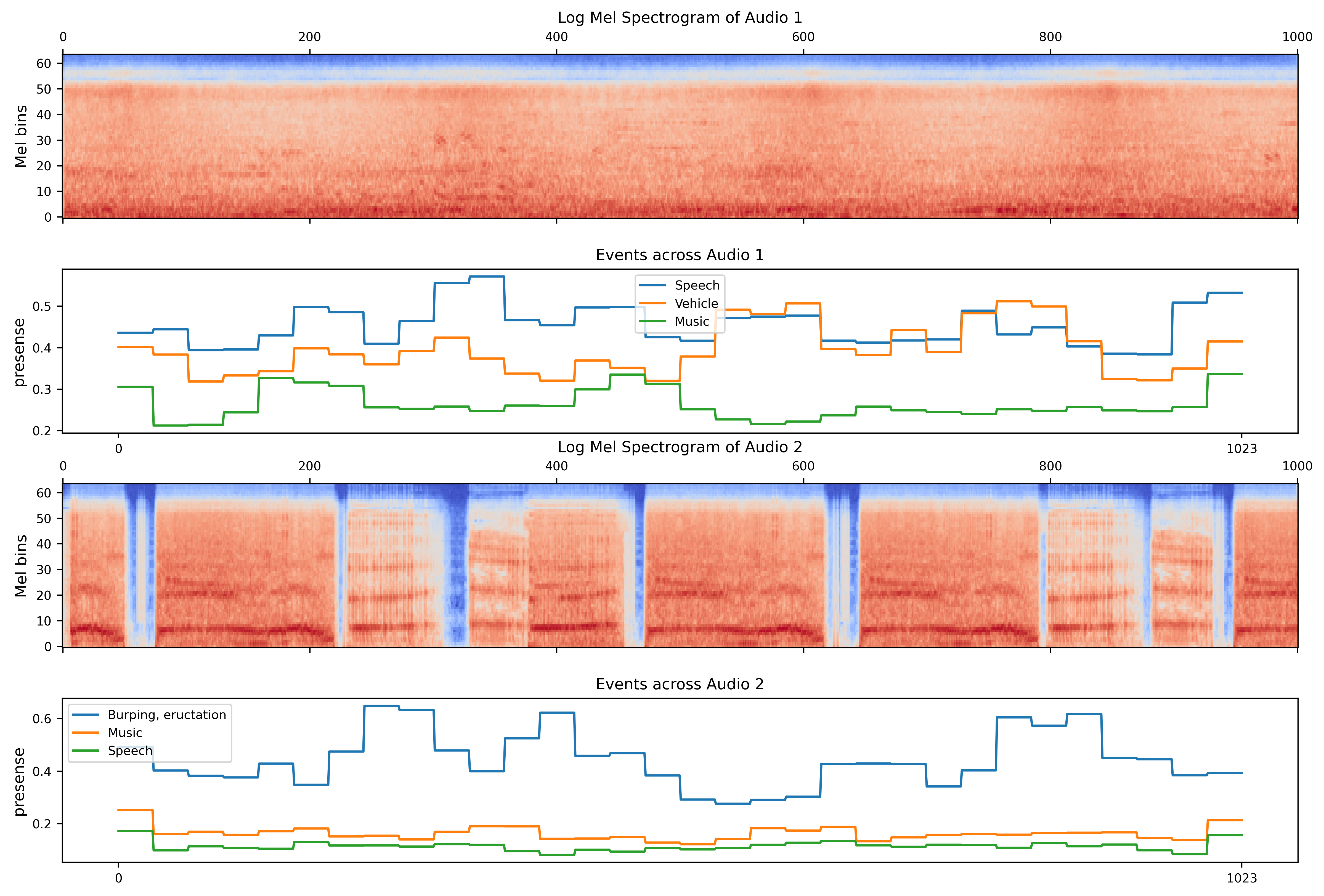
Figure 7: Usage of audio event presence probabilities from HTSAT to inspect and diagnose possible hallucinations in Mellow’s LLM output.

