- The paper introduces a training-free, plug-and-play framework that preserves essential visual information during token compression.
- It employs a two-stage process using attention-guided token selection and merging to reduce tokens to 22.2% of the original with a 1.54% accuracy drop.
- The method achieves a 1.23× inference speedup and cuts KV cache storage by 64%, enhancing computational efficiency in MLLMs.
Introduction
The paper "TokenCarve: Information-Preserving Visual Token Compression in Multimodal LLMs" (2503.10501) presents an innovative approach to the challenge of efficiently compressing visual tokens in Multimodal LLMs (MLLMs). The primary issue addressed is the significant computational overhead associated with processing visual tokens, which form a major component of the input data in MLLMs. Traditional methods either require extensive retraining or fail to preserve performance under high compression rates.
Methodology
The authors propose TokenCarve, a training-free, plug-and-play framework designed to compress visual tokens significantly while preserving the essential information necessary for maintaining model performance. The framework comprises two stages:
- Information-Preservation-Guided Selection (IPGS): This stage utilizes the rank of the attention output matrix to identify and prune low-information tokens. By combining information contribution scores, derived via singular value decomposition, with attention scores from the transformer layers, IPGS effectively retains tokens that are critical for information richness.
- Token Merging: In this stage, tokens are further compressed through merging based on cosine similarity and contribution scores, thus minimizing information loss. This is achieved by categorizing tokens into a higher-scored Set A and a lower-scored Set B, merging the latter with similar tokens in the former.
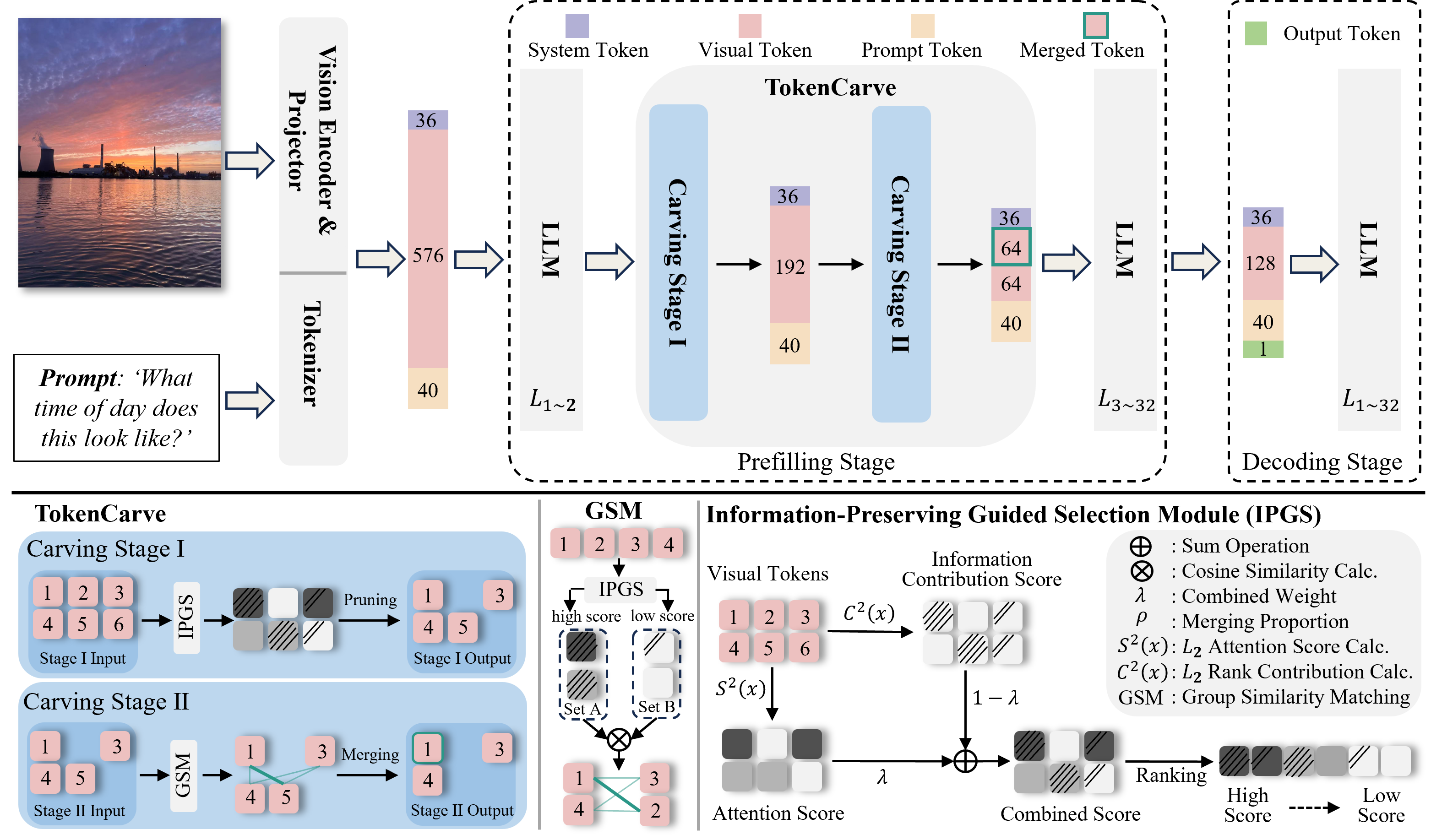
Figure 1: The pipeline of the proposed TokenCarve framework.
Experimental Results
The experimental evaluation of TokenCarve covers 11 datasets, demonstrating its capability to reduce visual token counts to 22.2% of the original while maintaining high accuracy. The key findings include:
- Performance Reduction: Only a 1.54% drop in accuracy is observed despite the aggressive token reduction.
- Inference Speedup: Achieving an inference speedup of 1.23×, coupled with a 64% reduction in KV cache storage, substantiates the framework's efficiency.
- Resilience Under Compression: TokenCarve consistently outperforms existing training-free methods, especially when significant token reductions are applied.
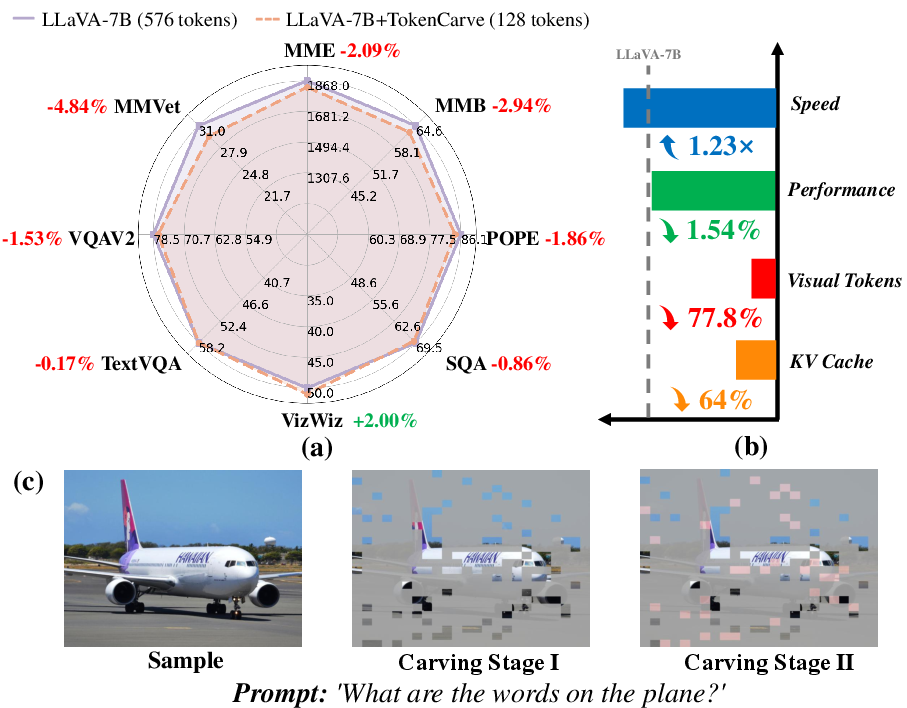
Figure 2: TokenCarve's performance retains close proximity to the uncompressed version even with substantial token reduction.
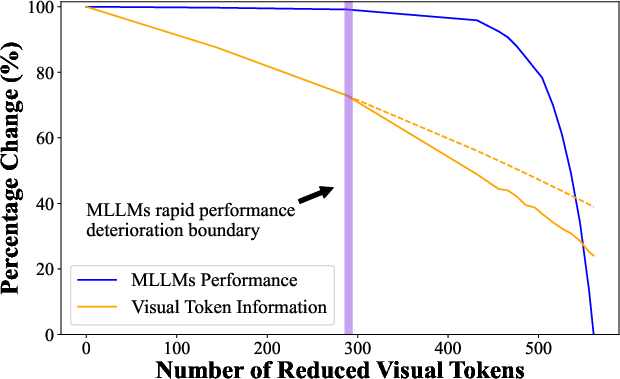
Figure 3: Correlation between MLLM performance and visual token information under compression, indicating robustness in performance.
Implications and Future Directions
The implications of this work are profound for the deployment of MLLMs, where computational efficiency is critical. By minimizing the information loss during token compression, TokenCarve not only reduces computational demands but also maintains high performance, paving the way for more scalable multimodal AI applications.
Future research directions could explore optimizing the architectural integration of TokenCarve to further enhance the inference speed, possibly through hardware enhancements or more efficient computation of positional encodings. Moreover, expanding the framework's applicability to other model architectures could generalize its benefits across different multimodal tasks.
Conclusion
TokenCarve presents a significant advancement in the field of token compression for MLLMs by addressing the critical balance between computational efficiency and information preservation. This framework sets a new standard for token reduction methodologies by achieving substantial compression with minimal performance degradation, offering a viable path forward for the efficient deployment of multimodal AI systems.