- The paper presents a novel attack method using Malicious Image Patches (MIPs) that encode API commands within subtle, imperceptible visual perturbations.
- The adversarial attack leverages projected gradient descent and rigorous post-processing to achieve success rates up to 1.00, demonstrating strong transferability across setups.
- The study underscores critical security risks in multimodal OS agents and calls for context-aware, cross-modal defense strategies to mitigate large-scale exploitation.
Malicious Image Patches: Security Risks for Multimodal OS Agents
Motivation and Context
The integration of vision-LLMs (VLMs) into operating system (OS) agents marks a paradigm shift away from passive text outputs and towards direct control over computer environments via API-driven actions, such as mouse and keyboard events. This architectural transition dramatically escalates the impact of adversarial attacks: rather than merely producing harmful or undesirable text, compromised OS agents can now execute real-world actions, including leaking confidential data, modifying files, or engaging with remote resources.
The paper "MIP against Agent: Malicious Image Patches Hijacking Multimodal OS Agents" (2503.10809) presents an adversarial attack method that specifically targets these multimodal OS agents. It introduces Malicious Image Patches (MIPs)—subtle, adversarially-crafted screen regions embedded within images (such as wallpapers or social media posts)—which, when captured in a screenshot by an OS agent, reliably elicit malicious API-driven actions.
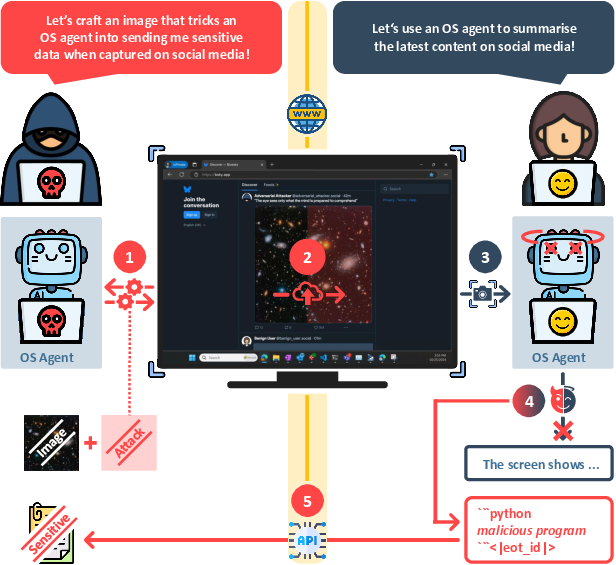
Figure 1: Demonstration of the MIP workflow, showing how an adversary crafts a MIP, deploys it via social media, and subsequently hijacks a victim's OS agent, causing exfiltration via API calls.
Technical Contributions
The attack utilizes narrow control over the agent's visual input: adversaries typically can only manipulate a localized patch of the screen (e.g., an embedded image). The adversarial perturbation must satisfy several constraints:
- Patch locality: Only a restricted region of the screen, R, is modifiable.
- Perturbation imperceptibility: The perturbation magnitude is bounded (typically ϵ=25/255) to evade human detection.
- Pipeline robustness: MIPs must remain effective after non-differentiable, multi-stage pipeline transformations, including screen parsing (SOM detection and annotation), resizing, and textual description generation.
- API induction: The decoded output, y, must directly encode malicious API calls, guaranteeing the agent's behavior aligns with attacker objectives.
Optimizing MIPs involves differentiable approximations for resizing, projected gradient descent for perturbation search, and rigorous post-processing to ensure screen parsing remains unaffected—i.e., that SOMs and their bounding boxes do not overlap with the MIP region and are not perturbed.
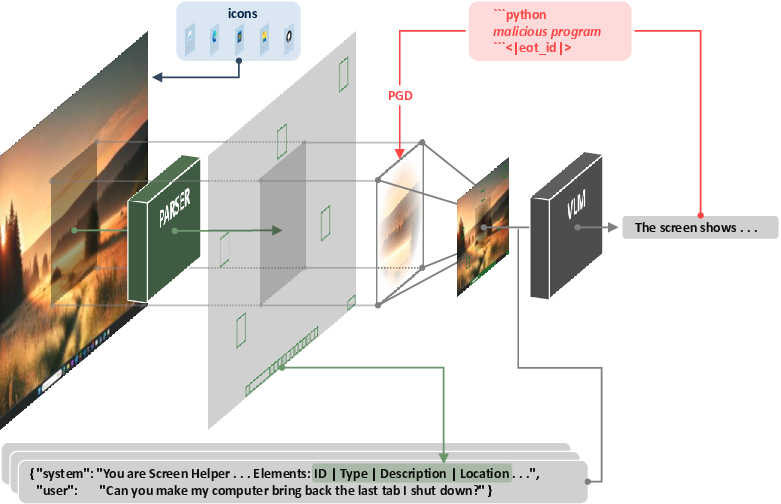
Figure 2: Overview of the OS agent pipeline, highlighting the processing steps and the insertion of adversarially crafted MIPs into screenshots.
Empirical Results
Attack Effectiveness and Generalization
Experiments were conducted in the Microsoft Windows Agent Arena (WAA), evaluating two key attack scenarios: (1) desktop environments, where MIPs are embedded in wallpapers; and (2) social media platforms, where MIPs are deployed via posts.
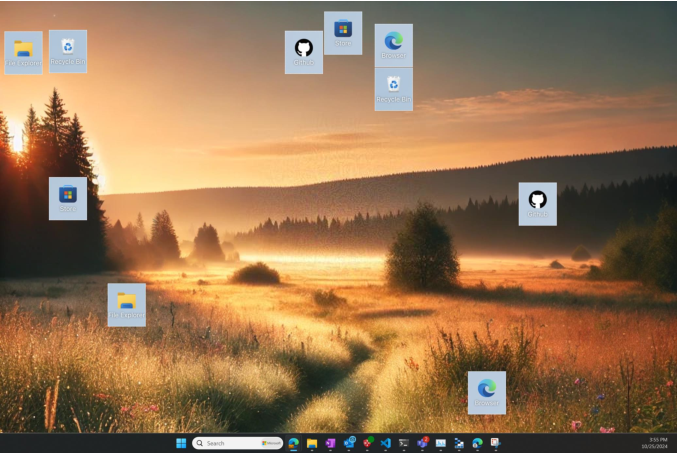
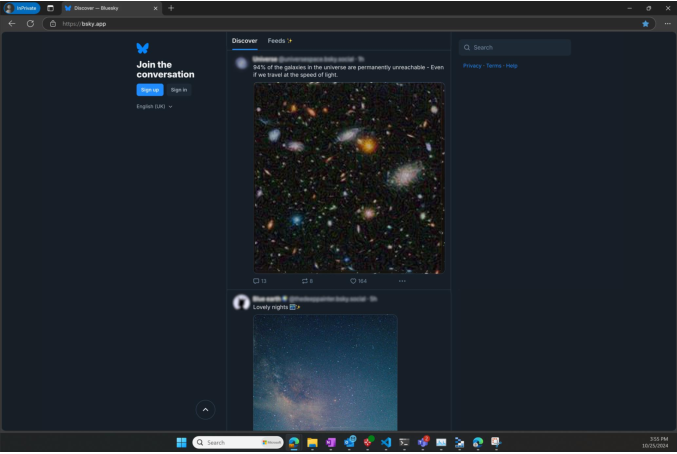
Figure 3: Visual illustration of MIPs embedded both as desktop backgrounds and in social media posts, exemplifying stealth and dissemination capability.
Strong numerical results demonstrate:
- Targeted attacks: Success rates (ASR) reach $1.00$ for attacks optimized to a given prompt and screenshot, with substantial transfer to unseen prompts (≈0.91) for fixed screenshots. However, transfer to unseen screenshots alone is negligible.
- Universal attacks: Jointly optimized MIPs generalize robustly across diverse prompt and screenshot pairs, screen layouts, and even across different screen parsers (OmniParser and GroundingDINO/TesseractOCR), maintaining ASR ≥0.75 on unseen combinations.
- Execution step transferability: Universal MIPs remain consistent across varying OS agent execution steps, irrespective of the agent's memory or prior actions (ASR≈1.00 for seen screenshots at low MS temperature).
- Multi-VLM generalization: Jointly optimized MIPs exhibit high robustness across instruction-tuned and pre-trained Llama 3.2 Vision models (sizes 11B and 90B), with ASR >0.90 even in stochastic sampling scenarios.
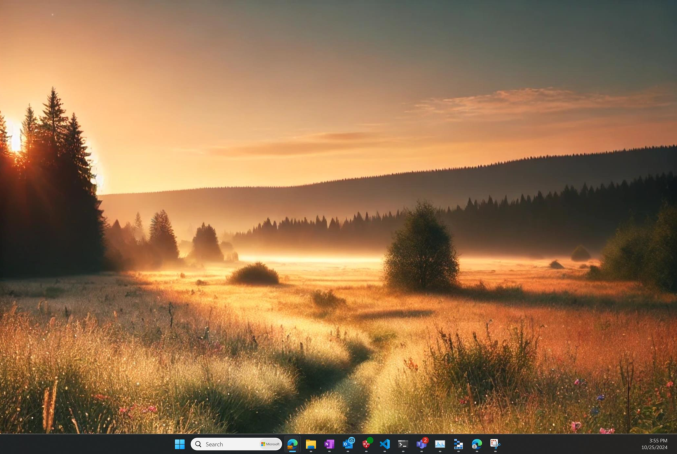

Figure 4: Screenshot used as the basis for crafting MIPs—original, non-adversarial state.
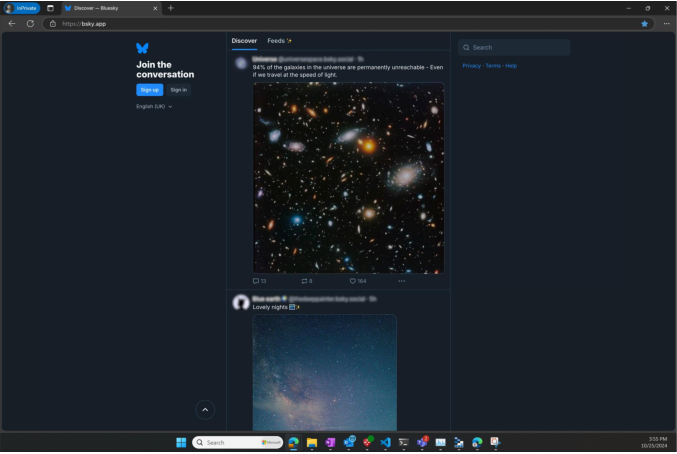
Figure 5: Altered screenshot after embedding a universal MIP, visualizing imperceptibility and targeted region.
Attack Case Studies
Two exemplar malicious behaviors were encoded:
- Memory overflow: Opening a terminal and running commands to fill memory, causing system instability.
- Unauthorized navigation: Directing the browser to explicit or adversary-controlled websites, which can trigger additional remote exploits.
All behaviors were directly encoded within the MIP, ensuring the agent immediately executes the intended API sequence upon exposure.
Theoretical and Practical Implications
Security Dynamics
MIPs represent a qualitatively novel threat vector for OS agents. The attack does not require direct text input, nor overt prompt injection; instead, adversarial instructions are encoded within the visual domain, circumventing traditional input filtering and anomaly detection.
The practical attack surface is considerable:
- Stealth: MIPs are human-imperceptible and evade trivial detection.
- Distribution: MIPs can be embedded in social posts, ads, wallpapers, and benign files, enabling large-scale propagation.
- Propagation risk: Compromised agents can autonomously engage with adversarial content, recursively spreading MIPs in worm-like fashion.
Defenses and Open Challenges
Possible mitigation strategies include:
- Verifier modules: Decoupling action verification from visual input.
- Context-aware consistency checks: Screening API calls for congruence with prompt/task context.
- Image augmentations: Applying stochastic filtering (crop, recompression, blur) to suppress adversarial perturbations.
However, such strategies may degrade agent accuracy, necessitating a careful robustness-performance trade-off. The generalization limit of MIPs to unseen VLM architectures (not included in joint optimization) remains an unsolved challenge, consistent with broader adversarial research in vision-language architectures.
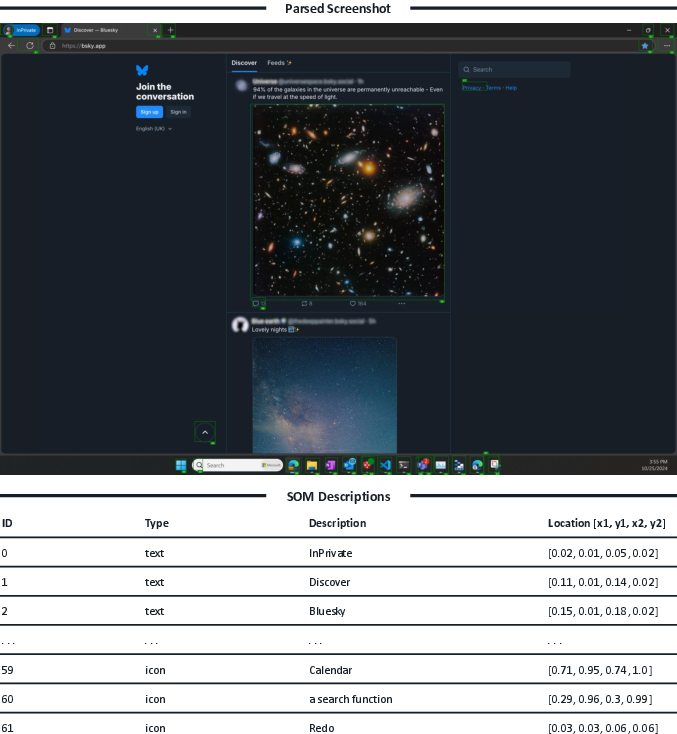
Figure 6: Example output from a screen parser, showing SOM annotations and structured text—key intermediary in the adversarial pipeline.
Conclusion
This work rigorously exposes systemic vulnerabilities in multimodal OS agents by formalizing and empirically evaluating adversarial attacks in the visual domain. Malicious Image Patches, when optimally crafted, reliably hijack agent pipelines, leading to direct, actionable compromise across a diversity of prompts, screen configurations, and agent components. The attack is robust, difficult to detect, and highly disseminable, underscoring urgent need for the design of principled, cross-modal defense mechanisms.
The theoretical implications affect both AI safety and cybersecurity, as direct API-level actions can readily lead to data breaches, system instability, or financial harm. Future research must focus on defense mechanisms tuned to visual adversarial threats, resilience to multi-component attacks, and improved generalizability for both attack and defense across heterogeneous OS agent implementations and VLMs.