- The paper introduces EmbodiedVSR, a framework that improves spatial reasoning in embodied tasks by using dynamic scene graphs and chain-of-thought processes.
- It leverages adaptive spatial knowledge representations to model object dynamics and causal relationships, enhancing performance on the eSpatial Benchmark.
- Experimental evaluations on LEGO assembly tasks demonstrate significant improvements in accuracy and coherence over current MLLM-based approaches.
EmbodiedVSR: Dynamic Scene Graph-Guided Chain-of-Thought Reasoning for Visual Spatial Tasks
Introduction
"EmbodiedVSR: Dynamic Scene Graph-Guided Chain-of-Thought Reasoning for Visual Spatial Tasks" (2503.11089) addresses significant limitations in Multimodal LLMs (MLLMs) concerning spatial reasoning for complex, long-horizon embodied tasks. The paper introduces EmbodiedVSR, a novel framework that integrates dynamic scene graph-guided Chain-of-Thought (CoT) reasoning, enhancing spatial understanding without task-specific fine-tuning. The framework disentangles intricate spatial relationships and aligns reasoning steps with actionable environmental dynamics. To evaluate performance, the paper presents the eSpatial-Benchmark, featuring real-world scenarios with fine-grained spatial annotations and adaptive task difficulty levels. The results showcase significant enhancements in accuracy and coherence over existing MLLM-based methods, particularly for tasks demanding iterative environmental interactions.
Framework Architecture and Methodology
EmbodiedVSR fundamentally reimagines spatial reasoning within embodied intelligence through the induction of dynamic scene graphs and physics-constrained CoT processes. The core innovation lies in constructing adaptive spatial knowledge representations that explicitly model object state dynamics, inter-object relational constraints, and action-induced environment transitions. The framework uses a dynamic scene graph that evolves through interaction cycles, maintaining causal relationships between agent behaviors and scene transformations. The reasoning mechanism hierarchically decomposes tasks into atomic inference steps validated against scene graph consistency rules, thereby anchoring language-based reasoning to structured spatial substrates.
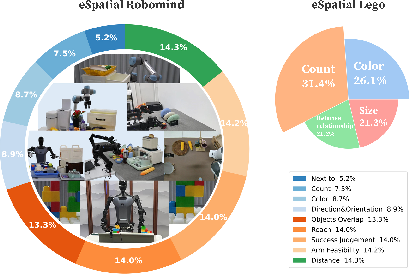
Figure 1: Overview of EmbodiedVSR framework integrating multimodal interaction and dynamic task execution.
Benchmarking: eSpatial-Benchmark
The paper introduces the eSpatial-Benchmark to assess spatial reasoning capabilities. This benchmark recalibrates spatial annotations in existing datasets and introduces new embodied reasoning challenges centered around LEGO-based assembly tasks. These benchmarks evaluate models' ability to understand object attributes, spatial dependencies, and hierarchical assembly sequences, mimicking real-world manipulation challenges through configurable setups. The benchmarks aim to fill gaps between traditional visual QA and actionable spatial cognition, facilitating research in embodied intelligence.
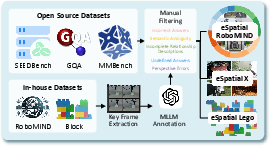
Figure 2: eSpatial filtering process.
Experimental Evaluation
EmbodiedVSR demonstrated substantial improvements in spatial reasoning tasks compared to existing MLLM-based approaches. In empirical evaluations using the eSpatial-Benchmark, the framework improved task accuracy and coherence significantly, emphasizing its utility in real-world applications. The LEGO reassembly task further showcases the practical implications of EmbodiedVSR in complex robotic operations, validating its capability to model spatial dynamics and reason about physical interactions effectively.

Figure 3: LEGO block reassembly task setup with humanoid robot and EmbodiedVSR integration.
Comparison and Ablation Study
The paper conducts a comprehensive comparison with state-of-the-art methods, highlighting EmbodiedVSR's superiority in handling spatial tasks requiring dynamic scene understanding. An ablation study further examines the contributions of each component within the framework, confirming the importance of integrating dynamic scene graphs with CoT reasoning for enhancing spatial awareness in MLLMs. These studies underscore the framework’s ability to generalize across diverse embodied scenarios, outperforming other models in accuracy and reasoning depth.
Conclusion
EmbodiedVSR represents a significant advancement in embodied intelligence, providing a robust framework for spatial reasoning by leveraging dynamic scene graphs and CoT processes. The research opens new avenues for reliable deployment of multimodal large models in real-world spatial scenarios, contributing to the broader field of AI research. The development of eSpatial-Benchmark offers fundamental infrastructure for evaluating and driving progress in embodied intelligence, facilitating future exploration in integrating structured reasoning into robotics and AI systems.