- The paper introduces GRPO and scene graph-based CoT prompting, significantly improving spatial reasoning accuracy and generalization in VLMs.
- It details a structured multi-stage prompting framework and reinforcement learning techniques that outperform traditional supervised fine-tuning.
- Findings have practical implications for robotics and autonomous navigation, promoting robust model design against linguistic variations.
Enhancing Spatial Reasoning in Vision-LLMs via Chain-of-Thought Prompting and Reinforcement Learning
Introduction
The paper investigates the spatial reasoning capabilities of Vision-LLMs (VLMs), focusing on techniques such as Chain-of-Thought (CoT) prompting and reinforcement learning. Spatial reasoning, crucial for tasks involving object locations, geometric relations, and spatial alignment, presents significant challenges even in advanced models. This study evaluates different prompting strategies and explores the efficacy of structured multi-stage prompting and reinforcement learning approaches to boost spatial reasoning proficiency.
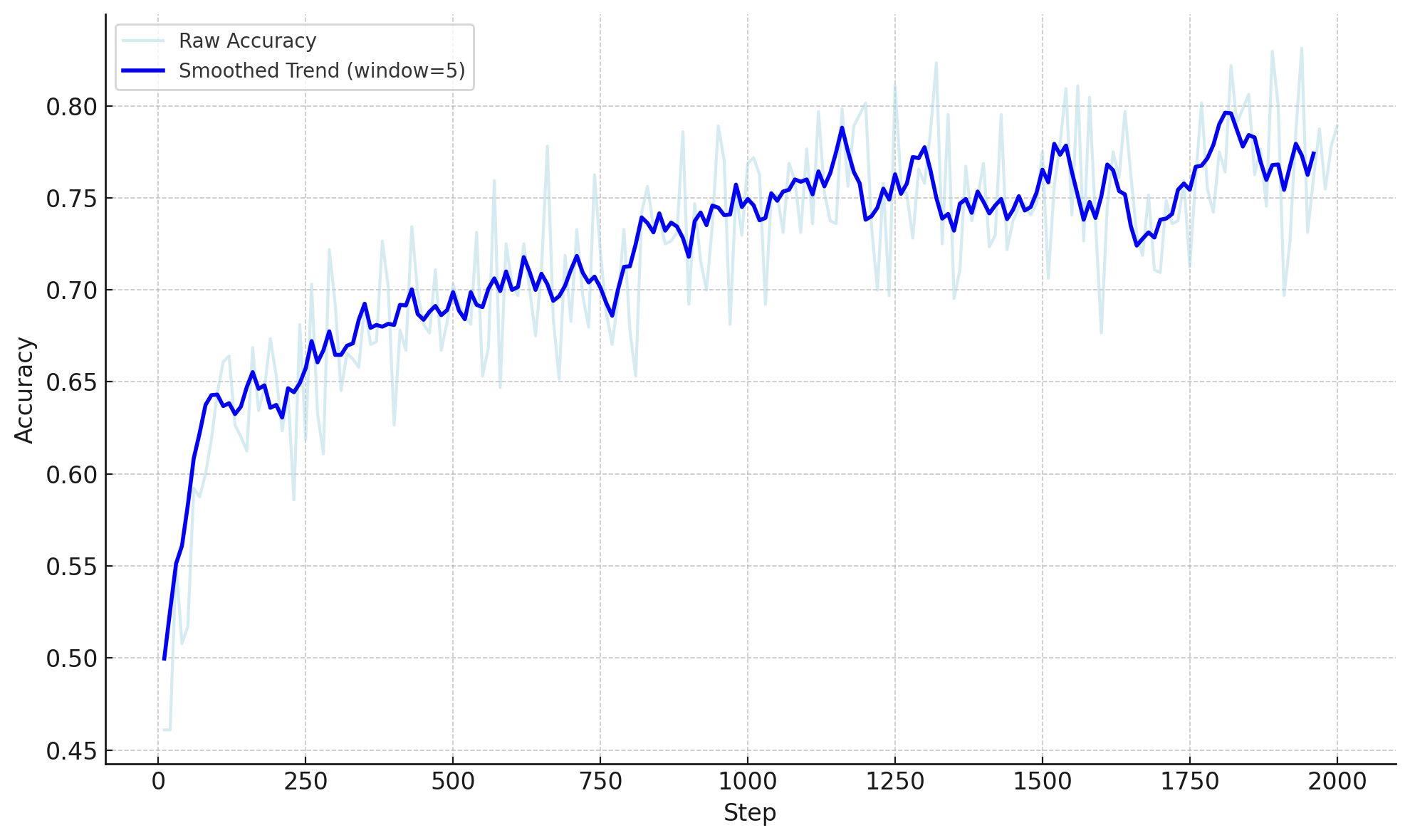
Figure 1: Accuracy Reward of GRPO-v2 model.
Methodology
Dataset Selection and Benchmarking
The study employs several benchmarks including CLEVR, Super-CLEVR, the Visual Spatial Reasoning (VSR) dataset, and CVBench to evaluate VLM spatial reasoning capabilities. The results indicate that simple CoT formats can harm model performance. However, structured prompting using scene graphs significantly improves accuracy, indicating the importance of structured reasoning cues.
GRPO Implementation and Fine-Tuning
Group Relative Policy Optimization (GRPO) is applied to fine-tune models on the SAT dataset, demonstrating improved performance compared to Supervised Fine-Tuning (SFT). GRPO exhibits better accuracy, particularly in out-of-distribution (OOD) evaluations, by encouraging reliable generalization beyond surface-level linguistic patterns.
Structured Prompting Framework
Structured multi-stage prompting based on scene graphs provides a robust framework for spatial reasoning. This strategy involves generating comprehensive scene representations before prediction, ensuring models leverage relational information effectively for accurate reasoning.
Results
The study's experiments reveal that GRPO fine-tuning significantly enhances model robustness and accuracy in spatial reasoning tasks, outperforming traditional supervised methods. The GRPO-v2 variant achieves notable gains, reinforcing alignment between visual and language modalities and maintaining performance under linguistic variation.
Additionally, incorporating scene graph-based CoT has yielded consistent improvements, with structured reasoning facilitating enhanced spatial interpretation across multiple tasks and datasets. Despite challenges such as reward hacking in naive CoT prompting, this study demonstrates that careful design of reasoning steps can substantially elevate VLM capabilities.
Implications and Future Developments
The paper presents implications for AI systems relying on spatial reasoning, such as robotics and autonomous navigation, emphasizing the necessity for strategies that overcome generalization barriers in VLMs. Future research may focus on integrating temporal dynamics, enhancing model architectures with segmentation-aware encoders, and exploring rich input representations like depth maps and 3D priors.
Considering the emergent trends, further work will extend GRPO applications to video-based tasks and investigate interactions between structured spatial prompting and rich visual cues. Refining object detection and integrating attention mechanisms are promising avenues to advance spatial reasoning in multimodal environments.
Conclusion
This paper offers a comprehensive examination of VLMs in spatial tasks, underscoring the efficacy of structured reasoning and reinforcement learning techniques. Through GRPO and SceneGraph CoT prompting, vision-LLMs can achieve heightened accuracy, aligning visual and linguistic content in demanding spatial contexts. The findings advocate for reinforcing model architectures with advanced alignment strategies to propel future advancements in spatial reasoning applications.