- The paper introduces a benchmark evaluating LLMs' ability to infer event descriptions from time series sports data.
- It employs a curated dataset from 4,200 games with 1.7M timestamps to assess reasoning via a multiple-choice framework.
- The study finds that reinforcement learning-enhanced models like DeepSeek-R1 improve inference and generalize across domains.
Inferring Events from Time Series using LLMs
Introduction
The study "Inferring Events from Time Series using LLMs" explores the novel problem of determining natural language events based on time series data. This problem is crucial for various domains that utilize time-based data to drive decision-making, such as finance and healthcare. The paper introduces a benchmark to evaluate the capacity of LLMs to infer event descriptions from time series data comprising real-valued measurements, specifically focusing on sports data with win probabilities. The investigation includes the performance evaluation of different LLMs on this benchmark, identifying capabilities and limitations in this context.
Methodology
The authors curated a comprehensive dataset from 4,200 basketball and football games, providing a substantial corpus of time series data aligned with natural language event descriptions.
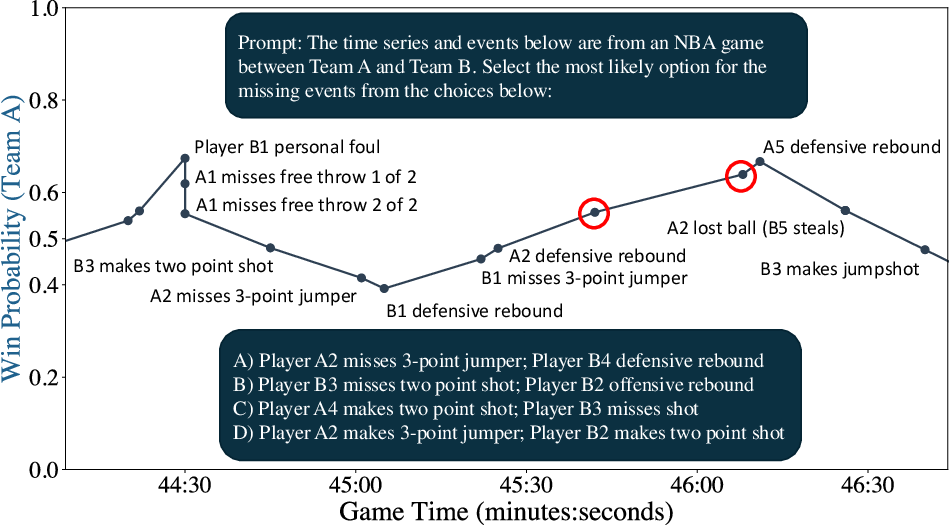
Figure 1: Illustration of time series event reasoning. The prompt provides a time series of real-valued data (win probabilities) and corresponding natural language event descriptions.
The dataset comprises 1.7 million timestamps, each representing an observable change in metrics such as win probabilities provided by ESPN. These metrics are linked with real-time in-game events and are divided into training and testing datasets to mitigate issues such as memorization and contamination within model evaluation.
The core evaluation task involves the LLMs selecting likely sequences of events corresponding to given time series data. The authors employ a multiple-choice format for model evaluation, enabling the isolation of reasoning processes where multiple event sequence options are presented per time series input.
Experimental Results
The paper evaluates 16 different LLMs, including proprietary models like GPT-4o and open-weight models like Qwen2.5. The results indicate substantial variance in the performance of these models in event reasoning tasks, with open-weight models showing competitive abilities relative to proprietary counterparts.
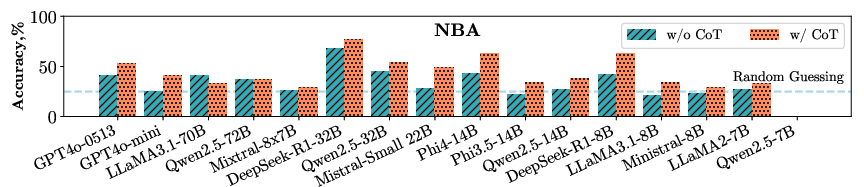
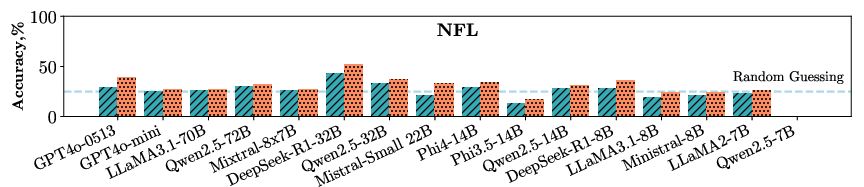
Figure 2: The performance of various LLMs on events reasoning indicates that open-weights models, such as Qwen2.5 72B, achieve comparable or superior results to proprietary models like GPT-4o.
Significant findings include the efficacy of reasoning-oriented models like DeepSeek-R1, which exhibit enhanced performance due to reinforcement learning approaches tailored for reasoning.
An extensive exploration into contextual factors influencing model performance revealed that the availability of additional context (timestamps, scores, partial event descriptions) improves reasoning accuracy. The study also identifies that logical consistencies in event sequences can augment inference, demonstrating models' sensitivity to inherent narrative structures within data.
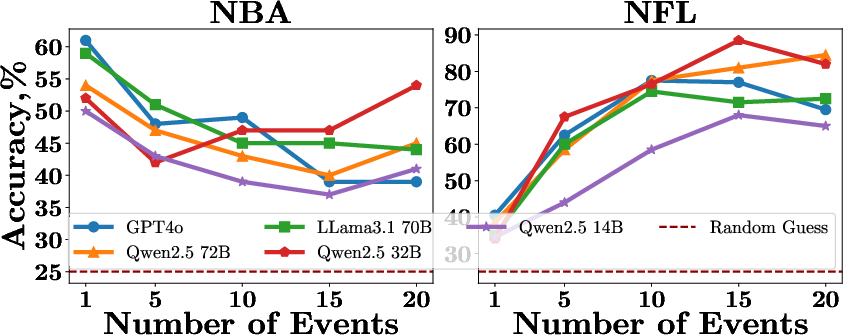
Figure 3: The reasoning performance of LLMs across event sequences of various lengths.
Analysis of Time Series Similarity
The impact of time series similarity on event reasoning was explored by quantifying the Euclidean distance between pairs of time series. The results demonstrated that as similarity distance increases, the models show improved differentiation capabilities, albeit within bounds of logical consistency.
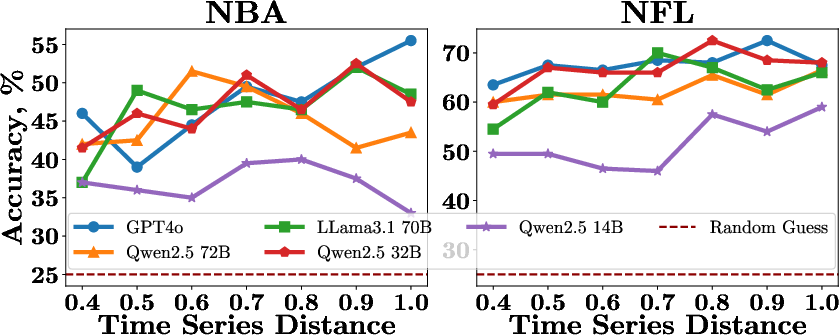
Figure 4: The performance of LLMs in distinguishing events corresponding to time series with different levels of similarity.
Cross-Domain Evaluation
In evaluating LLMs across other domains such as finance and energy, the study extends the applicability of time series-event relationships beyond sports, revealing consistent patterns in model capabilities across these varied datasets. It showcases the potential of LLMs to generalize event reasoning from structured environments like sports to broader economic landscapes.
Conclusion
The paper provides substantial evidence that LLMs possess inherent capabilities to infer events from time series data, revealing both promising applications and areas for enhancement. The introduction of benchmarks featuring real-world datasets offers a valuable tool for future iterations and improvements in LLM design tailored toward multimodal understanding. The demonstrated potential extends beyond the focused domains, offering insights applicable to various decision-critical applications reliant on real-time data analysis. Future work may explore training modalities and dataset configurations that bolster model reasoning and minimize context-driven errors.
Despite not serving as a conclusive evaluation standard, this benchmark represents a critical step in expanding the dialogue surrounding LLMs' role in dynamic and real-time data reasoning, setting the stage for sophisticated model designs optimized for real-world applications in finance, healthcare, and beyond.