Measuring AI Ability to Complete Long Tasks
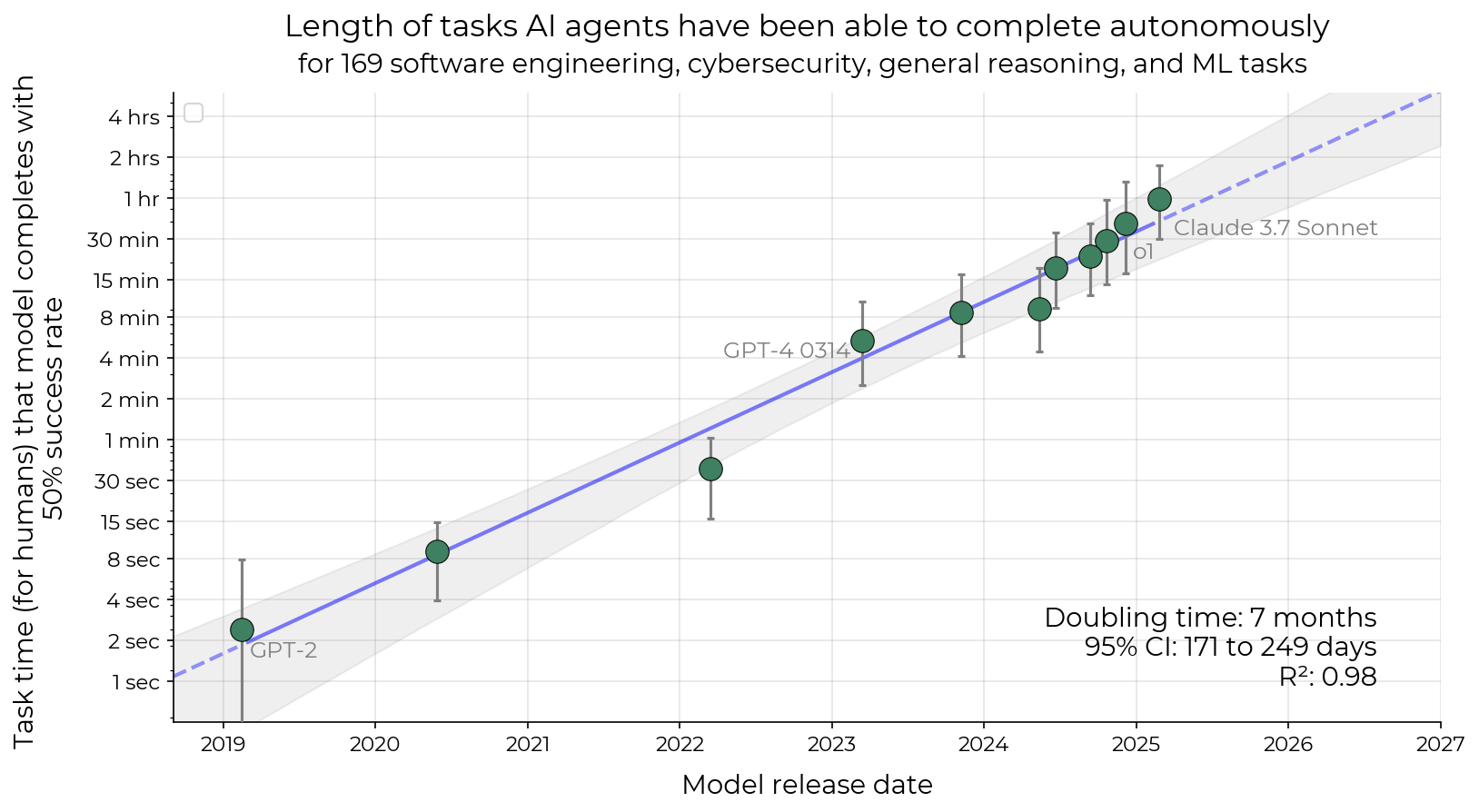
Abstract: Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to answer a simple question in an intuitive way: How much real work can today’s AI systems do on their own? The authors introduce a new, easy-to-understand yardstick called the “50% time horizon.” It’s the length of a task that an AI can finish correctly about half the time. By comparing AIs to how long skilled humans need for the same tasks, the paper turns scattered benchmark scores into a single, human-meaningful measure of capability.
What questions did the researchers ask?
- Can we measure AI ability in terms of “how long a typical human would spend on the same task” rather than just test scores?
- Has the length of tasks that AIs can complete been growing over time, and how fast?
- What skills are making AIs better at longer tasks (for example, better reasoning or tool use)?
- Do these measurements hold up on more realistic, messier tasks, not just neat, lab-style benchmarks?
- If the trend continues, what might that mean for future work and safety?
How did they test it?
To keep things fair and understandable, the team did three main things:
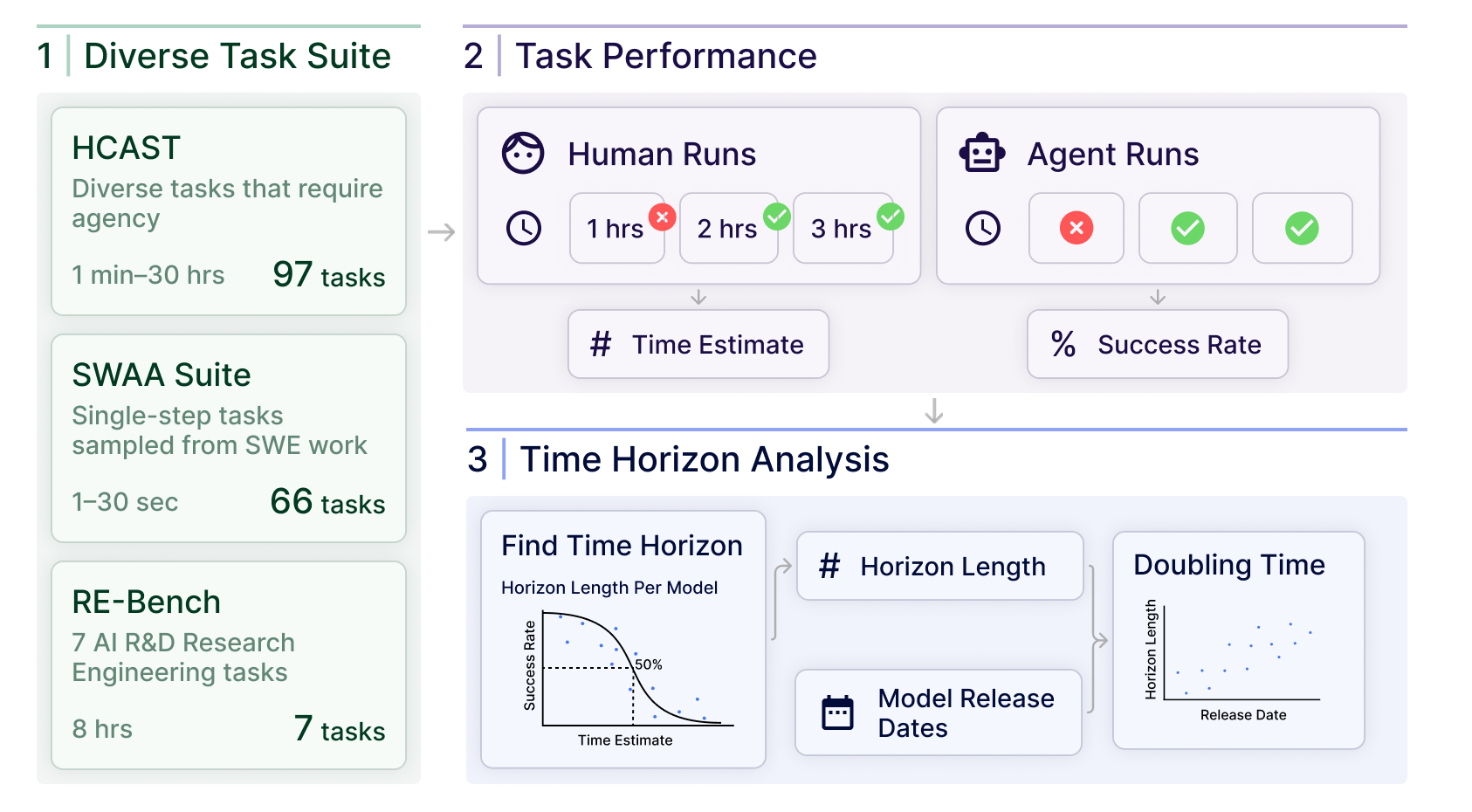
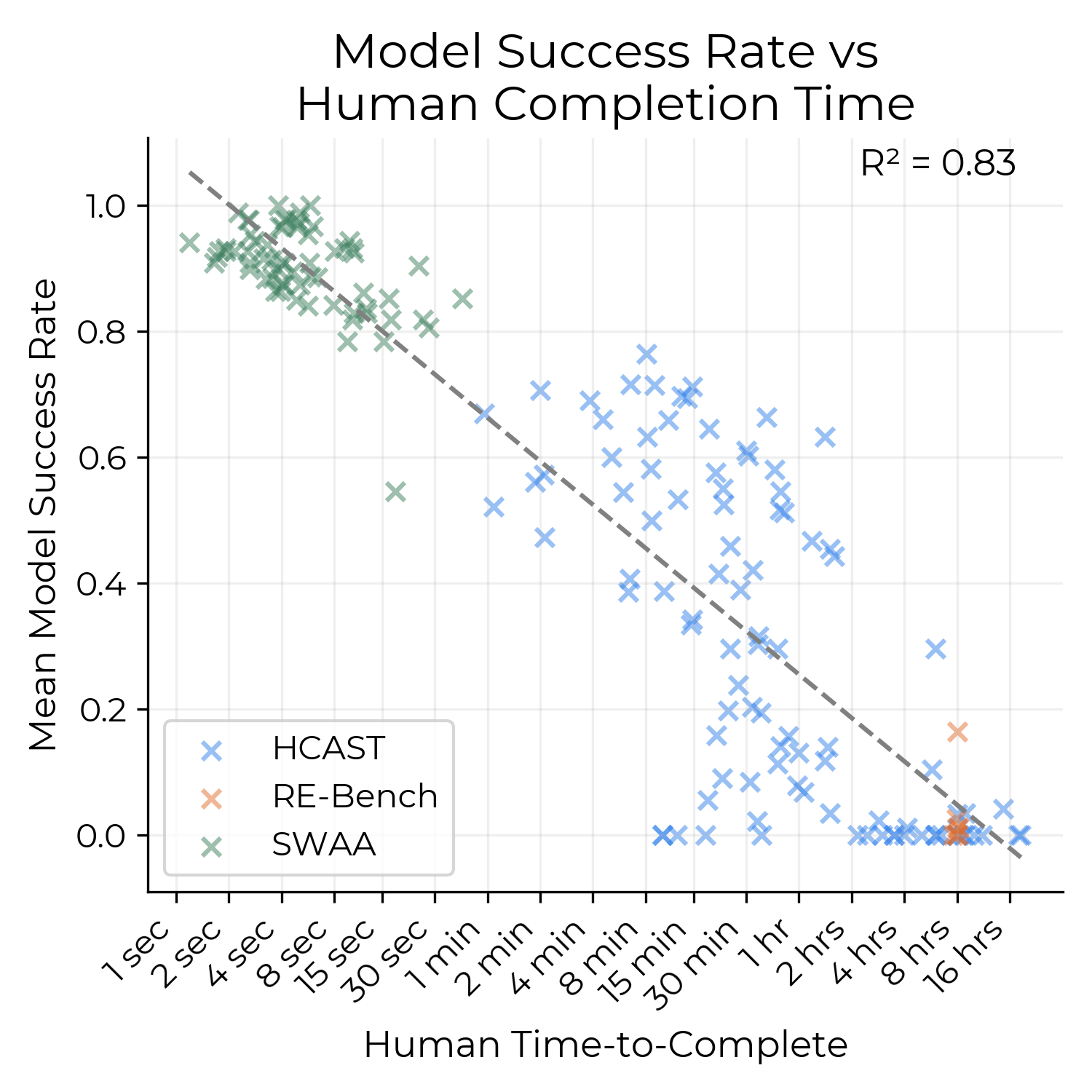
- They built a mixed set of 170 tasks with a wide range of lengths
- SWAA: 66 ultra-short “software atomic actions” (2–60 seconds), like picking the right file or completing a small snippet of code.
- HCAST: 97 diverse tasks (about 1 minute to ~30 hours) in software, ML, cybersecurity, and general reasoning.
- RE-Bench: 7 tough research engineering tasks designed to take about 8 hours each.
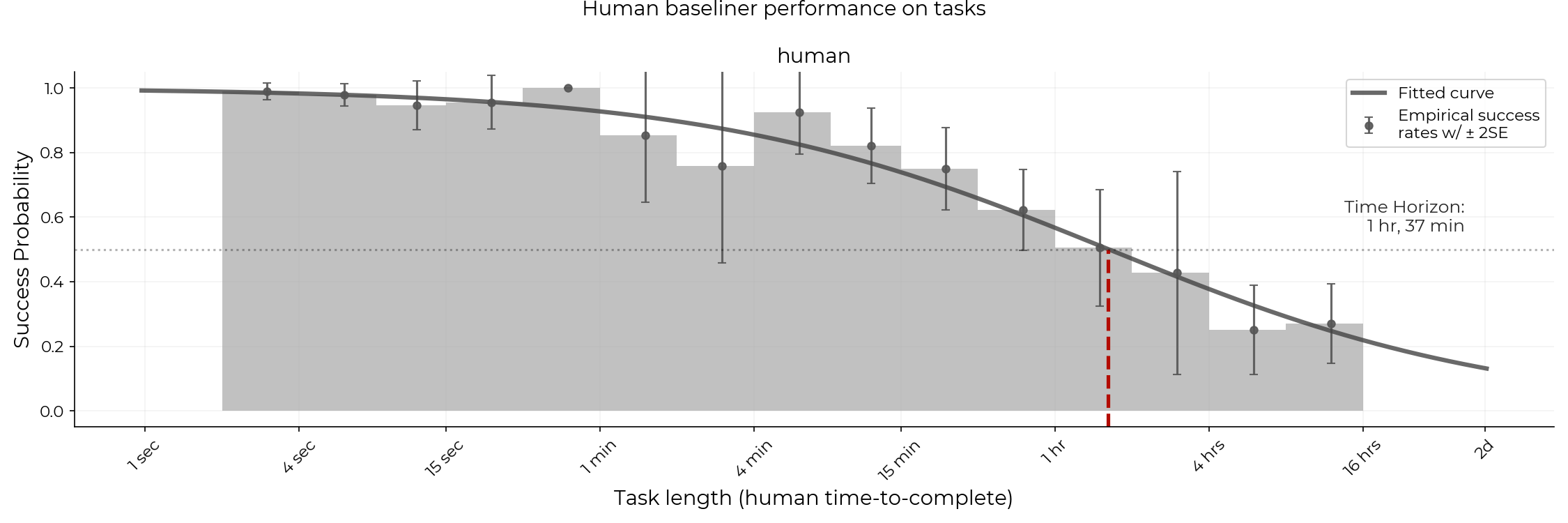
- They measured how long skilled humans took
- Professionals with relevant experience did the tasks while being timed.
- This gave a “human time-to-complete” for each task (for example, “this task usually takes around 10 minutes for a pro”).
- In total, humans spent over 2,500 hours establishing these baselines.
- They had AI agents attempt the same tasks and converted results into a “time horizon”
- The AIs used standard tools (like a command line and Python) and the same environment humans used.
- For each model, the researchers looked at how success rate dropped as tasks got longer.
- They fit an S-shaped curve (think of it like a smooth “chance of success vs. task length” line) and found the task length where the model succeeds about 50% of the time. That’s the model’s “50% time horizon.”
- They also calculated an “80% time horizon” to see how long a task can be when the model is reliable most of the time, not just half.
They double-checked how robust this was by:
- Testing on a well-known software benchmark with human time estimates (SWE-bench Verified).
- Tagging tasks with “messiness” factors (like unclear instructions or changing environments).
- Trying some real internal coding tasks from their own projects.
What did they find, and why is it important?
Main findings:
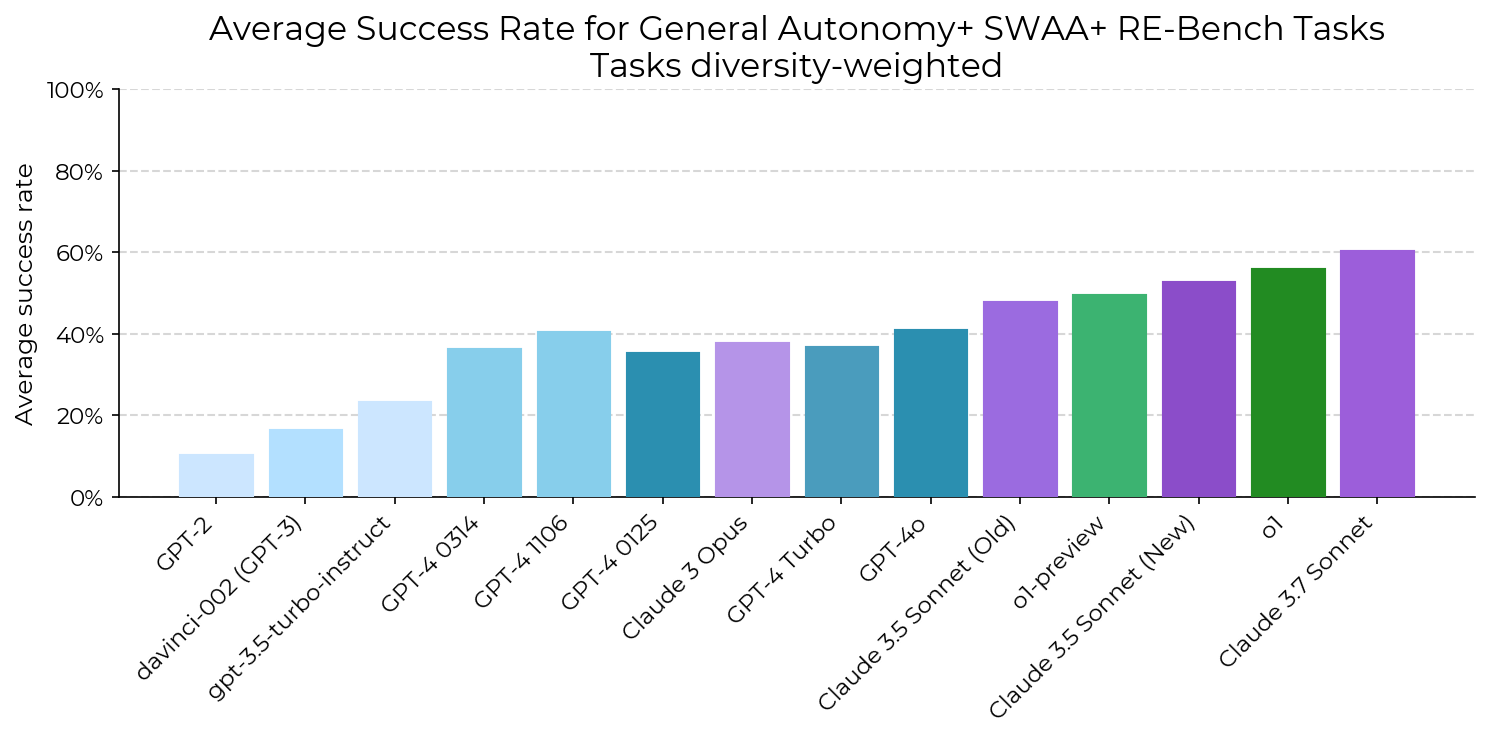
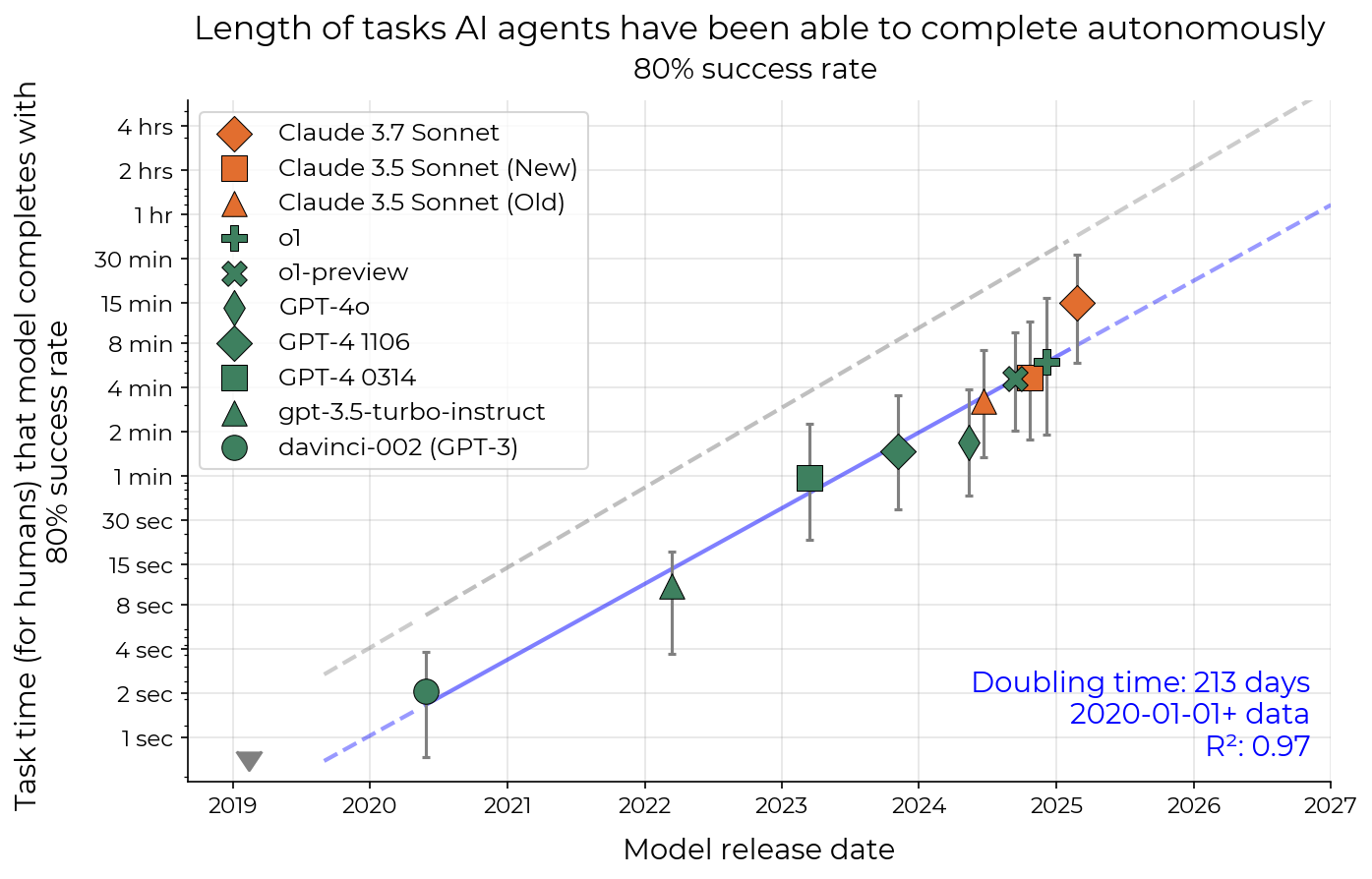
- Today’s top AI models have a 50% time horizon of around 50–60 minutes on these tasks.
- Example: Claude 3.7 Sonnet could often handle tasks that take a human about an hour, but not reliably enough to always succeed.
- The 80% time horizon (more reliable performance) is much shorter—about 5 times shorter. For the best model, it was around 15 minutes.
- This means AIs can sometimes complete hour-long tasks, but they’re only consistently strong on shorter tasks.
- The time horizon has been growing very quickly—doubling roughly every 7 months since 2019.
- That’s an exponential trend. If it kept going, within about 5 years AIs could complete many software tasks that take a human about a month (roughly 167 work hours).
- What’s driving the improvement?
- Better at using tools (like running code and shell commands).
- More reliable step-by-step behavior (less stuck-in-a-loop behavior, better recovery from mistakes).
- Stronger logical reasoning and code generation.
- What about real-world messiness?
- AIs did worse on messier tasks (e.g., unclear goals, less structure).
- However, the improvement trend over time looked similar for both less messy and more messy task sets in their tests.
- Checks on other benchmarks:
- On SWE-bench Verified, the trend still held (time horizons rising fast), though exact numbers differed due to how human time was estimated.
- Human baselines matter:
- Different human groups take very different amounts of time (e.g., contractors vs. maintainers), which can shift the measured “time horizon” by a big constant factor. This means who you compare to can change the exact numbers, even if the overall trend stays.
Why this matters:
- The “time horizon” metric translates AI progress into something concrete: “How long a human job can the AI tackle by itself?”
- Fast growth suggests AIs will handle longer and more complex tasks soon, especially in software. That could bring big boosts in productivity—but also raises questions about job roles and safety.
What are the limits and caveats?
- Not all tasks reflect the messiness of real jobs. Many were designed to be solvable with clear instructions and automatic scoring.
- The AIs were tested as “agents” with tools, but real projects often require context, coordination with teammates, and changing requirements.
- The 50% horizon is about “half the time” success, not consistent reliability. When you demand 80% reliability, the horizon is much shorter.
- The trend might speed up or slow down. Extrapolations are guesses, not guarantees.
What could this mean for the future?
If the current pace continues, AIs may soon complete much longer software tasks without supervision—possibly tasks that take a human weeks. That could:
- Speed up software development and research.
- Change how teams split work between humans and AI.
- Increase risks if powerful AIs act autonomously in harmful ways (the paper mentions concerns like dangerous chemical/biological capabilities), emphasizing the need for strong safety rules and careful testing.
Bottom line
This paper introduces a practical, human-centered way to track AI’s growing ability to do real work: the “time horizon.” Right now, top AIs can sometimes finish hour-long tasks on their own, but they’re reliably strong only on shorter tasks. The length of tasks they can handle has been rising fast—about doubling every 7 months. If that holds, AIs could handle many month-long software tasks within a few years. That’s exciting for productivity—and a signal to take safety and responsible deployment seriously.
Glossary
- Adversarially selected: Tasks chosen specifically to be difficult for current models; often used to stress-test model weaknesses. "Second, benchmarks are often adversarially selected for tasks that current models struggle with compared to humans,"
- Affordances: The tools, actions, and environment capabilities available to an agent during evaluation. "All agents were provided with the same affordances provided to human baseliners."
- Agent scaffold: A structured wrapper that equips a model with tools (e.g., Python, Bash) and interaction logic to operate as an agent. "Most AI models were evaluated with {modular-public}---our basic agent scaffold."
- Backtesting: Evaluating a trading strategy using historical data to assess performance. "Speed up a Python backtesting tool for trade executions by implementing custom CUDA kernels while preserving all functionality, aiming for a 30x performance improvement."
- Baseliner: A human evaluator with relevant expertise who completes tasks to establish performance and time benchmarks. "Our baseliners are skilled professionals in software engineering, machine learning, and cybersecurity,"
- Bio-anchors: A forecasting framework relating training compute to milestones anchored to biological cognition. "developed the ``bio-anchors'' framework,"
- Binarization: Converting continuous scores into binary outcomes (success/failure) using a threshold. "these are binarized via a task-specific threshold."
- CBRN: Abbreviation for chemical, biological, radiological, or nuclear; denotes high-risk capabilities or domains. "chemical, biological, radiological or nuclear weapons (CBRN)"
- Confidence interval (CI): A statistical range expressing uncertainty around an estimate, often at 95% confidence. "The shaded region represents 95\% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts."
- CUDA kernels: GPU-executed functions written for NVIDIA’s CUDA platform to accelerate computation. "writing CUDA kernels,"
- Doubling time: The period over which a quantity (e.g., capability horizon) doubles in value. "with a doubling time of approximately seven months (Figure~\ref{fig:headline})."
- Effective horizon length: Task duration threshold linked to transformative impacts in forecasting frameworks. "``effective horizon length''"
- Excess success rates: The difference between observed and predicted success, normalized by predicted success, to quantify over/under-performance. "Excess success rates ($\frac{S_{observed}-S_{predicted}{S_{predicted}$)"
- External validity: The extent to which results generalize beyond the evaluation setting to real-world tasks. "this raises the question of external validity (Section~\ref{sec:externalvalidity})"
- Frontier AI: The most advanced, cutting-edge AI systems at or near the capability frontier. "In the last five years, frontier AI systems have undergone a dramatic transformation in capabilities,"
- Geometric mean: A multiplicative average used to aggregate time measurements less sensitively to outliers. "Task durations are calculated using the geometric mean of successful baselines,"
- Hierarchical bootstrap: A resampling method accounting for nested structure (families, tasks, runs) when estimating uncertainty. "Error bars are calculated via 10,000 samples from a three-level hierarchical bootstrap over task families, then tasks, then runs."
- Item Response Theory (IRT): A psychometric framework modeling the relationship between item difficulty and agent ability. "Our methodological approach draws inspiration from psychometric testing, particularly Item Response Theory (IRT)"
- Latent traits: Unobserved characteristics (e.g., ability) inferred from observed performance. "latent traits (such as ability)"
- Logistic regression: A statistical model estimating success probability as a logistic function of task features (e.g., time). "Specifically, we perform logistic regression using:"
- Messiness factors: Qualitative properties (e.g., underspecification, resource limits) that make tasks more like real-world work. "we label each of our tasks on 16 ``messiness'' factors"
- Ordinary Least Squares (OLS): A regression method minimizing squared errors to fit linear models. "Specifically, we perform Ordinary Least Squares regression on ."
- Psychometric testing: Methods from psychological measurement used to assess capabilities and task difficulty. "Our methodological approach draws inspiration from psychometric testing"
- RE-Bench: A benchmark of open-ended ML research engineering environments, ~8 hours each, assessing complex capabilities. "RE-Bench consists of 7 challenging open-ended ML research engineering environments, each of which are intended to take a human expert approximately 8 hours to complete."
- Retrodiction: Using recent data to infer or validate past trends. "Retrodiction from 2023--2025 data"
- SWE-bench Verified: A software engineering benchmark with human difficulty annotations and time estimates. "We use SWE-bench Verified \citep{chowdhury2024SWEbench}'s human time estimates for task completion in our work."
- SWAA: Software Atomic Actions; ultra-short tasks (<1 minute) representing atomic steps in software work. "Software atomic actions (SWAA): 66 single-step tasks representing short segments of work by software developers, ranging from 1 second to 30 seconds."
- Time horizon: Task duration at which a model achieves a specified success rate (e.g., 50%). "We propose tracking AI progress over time using the task completion time horizon: the duration of tasks that models can complete at a certain success probability, providing an intuitive measure of real-world capability compared to humans."
- Tool use capabilities: An agent’s proficiency in invoking and coordinating external tools (e.g., Bash, Python) to solve tasks. "models seem to have improved greatly in terms of tool use capabilities,"
- Vivaria: An open-source platform/environment for running LLM agent evaluations. "Baseliners work in the same environment as agents, using Vivaria,"
- Weighted Least Squares (WLS): A regression technique weighting observations (e.g., tasks) to address heteroskedasticity or importance. "and WLS vs. OLS (see Figure \ref{fig:multiverse-boxplot})."
Collections
Sign up for free to add this paper to one or more collections.