Remote Labor Index: Measuring AI Automation of Remote Work
Abstract: AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces something called the Remote Labor Index (RLI). It’s a big test that checks how well AI “agents” (computer programs that try to complete jobs on their own) can do real, paid remote work—like the kinds of projects people do on freelancing websites. The main goal is to see if AI can truly replace or automate human workers on real-world tasks, not just do well on classroom-style quizzes.
Goals and Questions
The paper asks simple, important questions:
- Can today’s AI systems finish real freelance projects well enough that a client would accept them and pay for them?
- How much of the remote job market could AI do right now?
- How can we track AI’s progress over time on this kind of practical work, not just academic tests?
How They Did It
Think of RLI like a giant “real-life homework” set for AI, where each homework assignment is an actual job someone was paid to do online.
Here’s the setup:
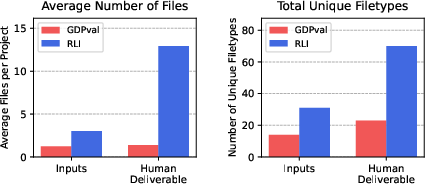
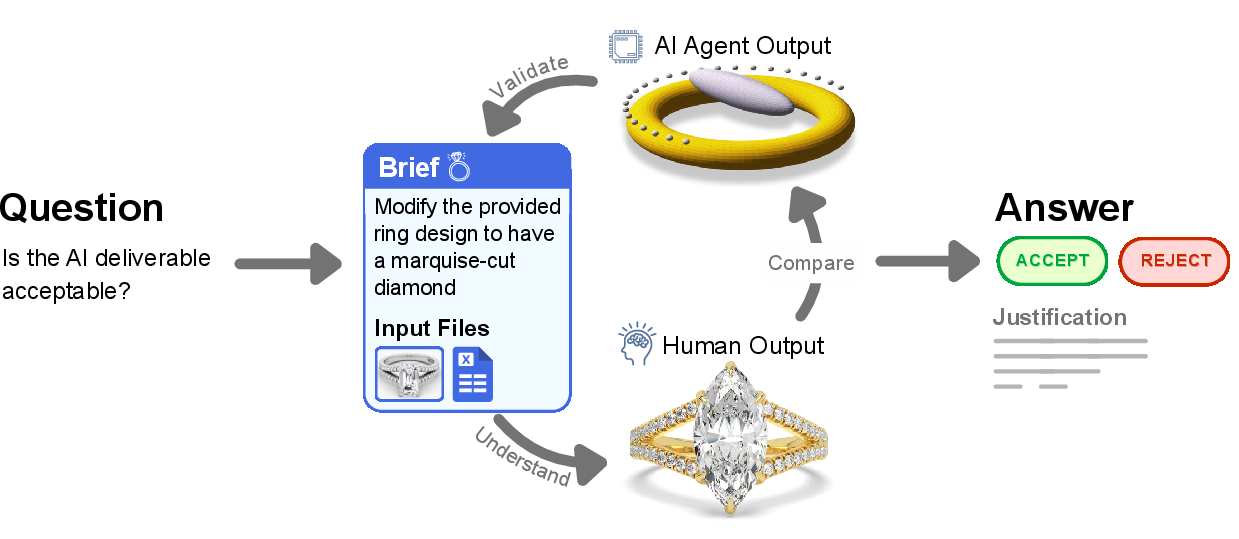
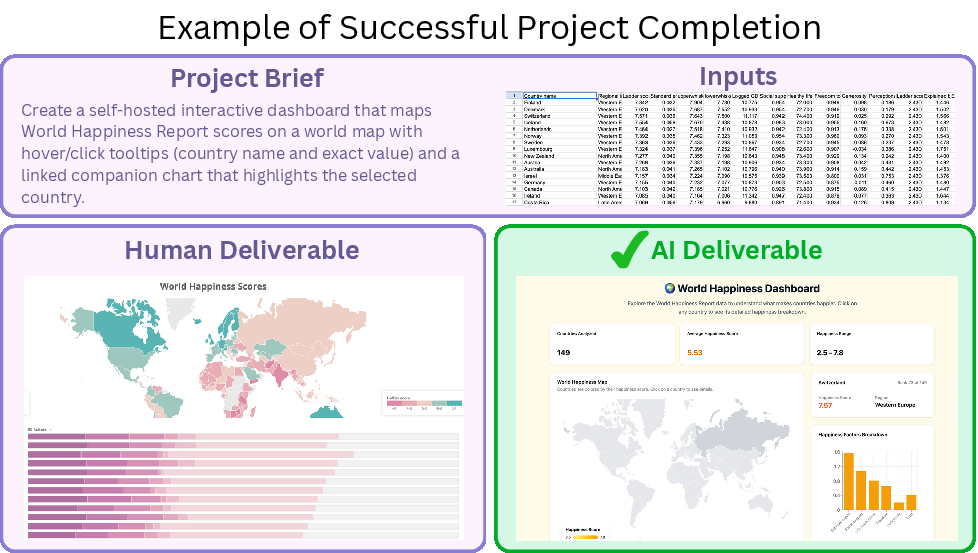
- The team collected 240 real freelance projects from platforms like Upwork. Each project includes:
- A “brief” (instructions from the client),
- Input files (materials needed to do the job),
- A “human deliverable” (the finished work a freelancer made and got paid for).
- Projects covered many areas: design, marketing, architecture, data analysis, audio/video editing, and more. These jobs are the kind of computer-based work people do remotely.
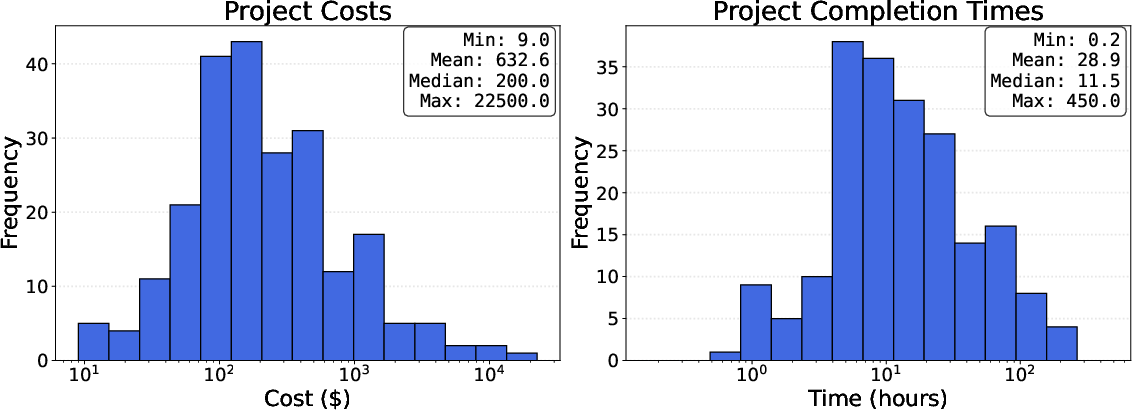
- Each project took real professionals time and money to complete. On average, projects took about 29 hours and cost around $633. So these are substantial, not trivial tasks.
How they tested the AIs:
- Different top AI agents were given the same brief and input files and asked to produce their own deliverables.
- Human evaluators compared the AI’s deliverable to the human’s deliverable and asked, “Would a reasonable client accept the AI’s work?”
- They used two main measurements:
- Automation rate: The percentage of projects the AI completed well enough to be accepted (like a pass/fail grade).
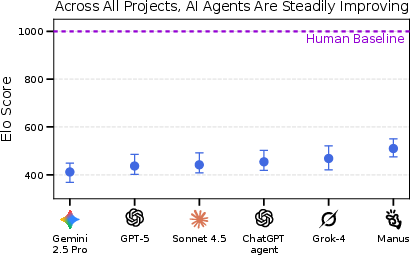
- Elo score: A relative ranking that compares different AIs against each other, similar to how players are ranked in chess or video games. It helps track improvement even when AIs don’t fully pass many tasks.
- Because these projects are complex (with many file types and formats), evaluation was done carefully by trained people using a special web platform. The judges mostly agreed with each other, showing the process was reliable.
What They Found and Why It Matters
Main results:
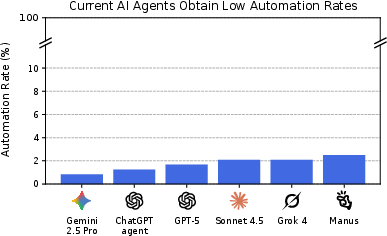
- Current AI agents can only fully automate a tiny slice of real remote work. The best model completed just 2.5% of projects well enough for a client to accept.
- Even though AIs are improving on academic tests, they mostly fail on end-to-end, real-world jobs that require high-quality, complete, and correctly formatted deliverables.
- The Elo scores show that some AIs are better than others and are making progress, but they’re still far below the human baseline.
Common AI mistakes:
- Technical problems: files were corrupted, in the wrong format, or empty.
- Incomplete work: missing parts, short videos instead of long ones (e.g., 8 seconds instead of 8 minutes), absent source assets.
- Low quality: work that looks or sounds unprofessional.
- Inconsistencies: details don’t match across files (like a house model that changes shape across different views).
Where AIs did well:
- Some creative or simpler tasks, especially:
- Audio editing and mixing,
- Image generation (ads, logos),
- Writing and web scraping,
- Simple data visualizations coded for the web.
Why this is important:
- It gives a reality check: AI is not yet ready to replace most remote workers on complete projects.
- RLI provides a fair, real-world way to measure and track AI’s progress over time, using work that has actual economic value.
Implications and Impact
- For workers and businesses: Most remote jobs are safe from full automation for now. AIs can help with parts of tasks but struggle with full professional-quality projects.
- For policymakers and researchers: RLI is a solid baseline to monitor AI’s impact on the job market. As AI improves, the index can show where and when real automation starts to happen.
- For AI developers: The biggest gaps are in reliability, completeness, and quality control—especially with complex, multi-file projects and audiovisual tasks. Improving these will matter more than just getting better at answering text questions.
A note on limitations
RLI doesn’t include every type of remote work—for example, jobs that require live client interaction or teamwork. So even if an AI eventually gets 100% on RLI, there would still be areas of remote work it might not handle well.
In short: This study shows that today’s AIs can’t yet do most real freelance projects end-to-end, but it provides a clear, practical way to measure progress toward that goal.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that the paper leaves unresolved and that future researchers could act on:
- Dataset representativeness: Only 23 of Upwork’s 64 categories are covered and many categories were excluded via pre-filtering. Quantify how the final sample deviates from the true distribution of remote work (by category, complexity, deliverable type) and expand coverage to underrepresented domains.
- Sampling and selection bias: Projects were sourced from freelancers who opted in and from commissioned long-tail items. Assess and correct for bias versus a randomly sampled, representative set of market projects; report stratified comparisons by freelancer profile, earnings, and project size.
- Single human deliverable baseline: Each project uses one freelancer’s deliverable as the gold standard. Measure variability and fairness by collecting multiple human deliverables per project (novice vs expert) and calibrate acceptance criteria to client outcomes rather than a single artifact.
- “Reasonable client” criterion and holistic review: The acceptance standard is subjective and rubric-free. Develop domain-specific rubrics and objective acceptance tests (e.g., automated functional tests for code, perceptual/audio metrics, visual QA checklists) and compare outcomes to real client panels.
- Evaluator expertise and time constraints: Details of evaluator specialization, training, and domain coverage are limited; time caps may bias decisions toward rejecting complex deliverables. Quantify how inter-annotator agreement and decisions vary with domain expertise and evaluation time; set domain-dependent time budgets.
- Reproducibility and access: Only 10 public projects are released; 230 remain private. Explore secure evaluation-as-a-service, anonymized/obfuscated releases, or synthetic-but-economically-grounded proxies to enable independent replication without privacy leaks.
- Tooling and environment constraints: Many projects require specialized software (CAD, DAWs, 3D suites) or GPUs; agent access and compute budgets are not fully specified. Systematically ablate the impact of tool availability and hardware (CPU/GPU) on automation rates; evaluate with resource-rich vs resource-limited setups.
- Agent run budgets and iterative workflows: Real freelance work involves revisions and multi-session iteration. Measure acceptance under multi-pass, revision-allowed protocols (e.g., n-step improvement loops, client feedback simulations) versus single-shot outputs; report “cost-to-completion” from near-miss outputs.
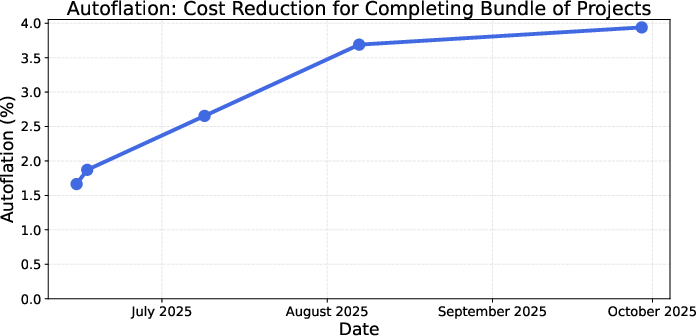
- Cost modeling limitations: Autoflation treats unsolved tasks as infinite cost and ignores inference/ops costs, human oversight, and inflation. Incorporate compute costs, human-in-the-loop oversight costs, inflation adjustments, and regional wage variation; perform sensitivity analyses on pricing assumptions.
- Excluded work types: Client-interactive, team-based, and backend development tasks are omitted. Prototype evaluation protocols for multi-party coordination, communication-heavy tasks, and services whose success requires latency or external feedback (e.g., tutoring, project management).
- Category-level performance: Results are aggregated only at the benchmark level. Publish per-domain automation rates, Elo scores, and error profiles to identify tractable sub-areas and prioritize targeted capability development.
- Predictive validity across benchmarks: The correlation between RLI and existing agent/computer-use benchmarks (OSWorld, WebArena, SWE, etc.) is unknown. Quantify cross-benchmark correlations and build composite predictors of RLI performance to guide research investment.
- Longitudinal tracking methodology: Elo suggests relative progress, but a standardized time-series protocol isn’t specified. Establish a fixed, contamination-resilient panel of projects and a regular release cadence to track frontier models over time.
- Human baseline calibration: Human Elo is fixed at 1000 without measuring variance across multiple humans. Collect multiple human baselines per project to estimate human performance distributions and set more informative normalization.
- Near-miss grading: Binary automation rate may mask deliverables that require minimal fixes. Introduce graded acceptance (e.g., accepted with minor revisions) and estimate expected revision time and cost, enabling a “distance-to-acceptance” metric.
- Internet and API access: The extent and limits of agents’ web/API access are unclear. Explicitly test tasks requiring external data and real-time APIs with controlled access policies; quantify how open vs restricted internet access affects outcomes.
- Multilingual and cultural scope: Briefs and deliverables appear primarily English-centric. Add multilingual projects and culturally diverse deliverables; measure automation across languages and client norms.
- Data contamination auditing: A blocklist is mentioned, but no empirical audit of training-data overlap. Conduct overlap checks, membership inference tests, and randomized obfuscation to quantify contamination risk and its effect on measured performance.
- Failure mode quantification: Failures are clustered qualitatively (corruption, incompleteness, quality, inconsistency). Instrument tasks to isolate and measure specific cognitive skills (verification, audiovisual consistency, memory, long-horizon planning) and link failures to capability deficits.
- Multi-agent orchestration: Only single-agent scaffolds are evaluated. Test specialized, tool-using multi-agent systems and orchestrators; compare to single-agent baselines on coordination-heavy projects.
- Benchmark scale and statistical power: With 240 projects, per-category confidence may be low. Provide confidence intervals per metric/category; perform power analyses and expand samples in domains with wide variance.
- Client acceptance realism: Evaluators simulate clients; real market acceptance and payment are not measured. Run field trials with actual Upwork clients commissioning AI outputs; compare evaluator judgments to real acceptance, revision cycles, and payments.
- File-format coverage bias: The evaluation platform’s supported formats may shape agent outputs and penalize otherwise valid deliverables. Quantify the impact of format constraints and broaden renderer support or allow external viewers in sandboxed environments.
- Run-to-run variance and best-of-n: Agent outputs are stochastic; single runs may underrepresent capability. Report variance over multiple seeds/runs per project and evaluate best-of-n and ensemble selection strategies.
- Economic impact mapping: The paper introduces “autoflation” but does not link RLI metrics to labor-market outcomes. Develop models translating RLI changes into wage effects, employment shifts, and sector-level price indices; validate against real market data.
Practical Applications
Immediate Applications
Below are specific, deployable applications that leverage the paper’s dataset, methods, metrics, and findings.
Industry
- RLI-based model/vendor selection for AI-enabled products (software, design, marketing, data/BI)
- Use the RLI automation rate and Elo to compare agent frameworks before integrating them into products or internal tools; gate new model rollouts with an RLI-derived acceptance threshold.
- Potential tools/workflows: “RLI Scorecard” dashboards for procurement; regression tests that include RLI-like projects in CI for agent features.
- Assumptions/dependencies: Access to the public RLI subset or similar internal projects; ability to reproduce RLI-style evaluation (human-in-the-loop); budget for manual evaluation.
- Targeted augmentation workflows in areas with demonstrated AI strength (creative audio/image, report writing, data retrieval/visualization)
- Deploy AI as a first draft generator for ad/logo variants, audio cleanup/mixing, templated reports, interactive charts; maintain human QA to meet professional standards.
- Potential tools/workflows: “First-pass generator” pipelines; rapid iteration galleries for creatives; templated report writer with retrieval + compliance checks.
- Assumptions/dependencies: Clear acceptance criteria and brand/style guides; human review capacity; IP checks for generated assets.
- Deliverable “pre-flight” quality gates to mitigate observed failure modes (cross-industry)
- Systematically catch issues the paper identifies: corrupted/empty files, missing components, wrong formats, inconsistent multi-asset outputs, low professional polish.
- Potential tools/workflows: File integrity/format validators; “asset manifest + checksum” exporters; render tests (open-and-view suite) before client delivery; multi-asset consistency checkers (style/visual embedding checks); completeness checklists tied to project briefs.
- Assumptions/dependencies: Access to renderers/viewers for target formats; standardized manifests; acceptance policies tied to a “reasonable client” perspective.
- Pricing, budgeting, and ROI tracking using “Autoflation” as an operational KPI (PMO/CFO offices)
- Track effective cost declines for fixed bundles of digital work when AI is cheaper than human completion on specific project types.
- Potential tools/workflows: Autoflation dashboards for category-level planning (e.g., audio post vs. presentation design); cost-of-work indices embedded in procurement systems.
- Assumptions/dependencies: Reliable auditing of “successful” AI completions to avoid false savings; time series data updates; data governance around project cost disclosures.
- Marketplace features for digital labor platforms (e.g., Upwork, Fiverr)
- Introduce task-level “AI viability” badges, human-only tags, and client-facing expectations where AI augmentation is acceptable; offer RLI-like evaluation as a paid QA service for clients.
- Potential tools/workflows: Category risk indicators; escrow tied to RLI-style acceptance testing; freelancer training modules on failure modes.
- Assumptions/dependencies: Platform policy changes; evaluator workforce and training; permissions for evaluation of submitted deliverables.
- Product QA and compliance in regulated sectors (healthcare comms, finance reports, public sector materials)
- Use the paper’s holistic evaluation approach to validate that agent outputs meet professional standards beyond simple rubric checks.
- Potential tools/workflows: “Reasonable client” review guidelines embedded in QA; traceable acceptance rationales; audit trails on format renderability.
- Assumptions/dependencies: Sector-specific compliance overlays; documented acceptance standards; secure review environments.
Academia
- Benchmarking research on agent scaffolds and multimodal tool use
- Use RLI (public set) to compare CLI vs computer-use agents; study error clusters; publish methods that reduce corrupted/incomplete deliverables.
- Potential tools/workflows: Open-source evaluation harness extensions; ablation libraries for action planning, verification, self-checks.
- Assumptions/dependencies: Adherence to the paper’s evaluation protocol; trained annotators; reproducible agent environments.
- Curriculum design and skills training aligned to less-automated competencies
- Integrate RLI project archetypes into coursework; teach professional quality thresholds, file hygiene, and cross-asset consistency.
- Potential tools/workflows: Capstone clinics using RLI-like briefs; “pre-flight” QA modules; studio critiques modeled on “reasonable client” standards.
- Assumptions/dependencies: Licensing for example materials; evaluator time; alignment with career services.
- Methodology adoption for evaluation science and HCI
- Adopt the holistic, deliverable-centered review paradigm for complex artifact assessment; study inter-annotator dynamics and time budgets.
- Assumptions/dependencies: Access to the evaluation platform code; IRB considerations for human evaluators.
Policy
- Evidence-based monitoring of AI’s labor impact using RLI-style indices
- Report automation rates and Autoflation by category to labor agencies; publish early-warning dashboards for specific remote-work segments.
- Potential tools/workflows: Quarterly RLI-style briefings; public dashboards with domain-level trends; inclusion in official statistical releases.
- Assumptions/dependencies: Ongoing dataset refreshes; transparency around evaluation standards; careful communication about scope (remote, project-based work).
- Targeted reskilling and workforce development
- Direct funds toward categories with rising Elo but low automation now (pre-transition), and fortify domains with persistent low automation exposure.
- Potential tools/workflows: Category heatmaps; grant scoring that references RLI category trends; micro-credential design.
- Assumptions/dependencies: Crosswalks to O*NET or national taxonomies; longitudinal updates to prevent staleness.
- Standards and guidance for AI deliverables in public procurement
- Require renderable, reviewable formats and proof of pre-flight checks; mandate RLI-like acceptance tests for AI-assisted submissions.
- Assumptions/dependencies: Agency rulemaking; procurement system updates; evaluator capacity.
Daily Life
- Freelancer strategy and client communication
- Use insights on strengths/weaknesses to niche into resilient categories or offer AI-augmented packages with explicit QA; adopt pre-flight checklists before client delivery.
- Potential tools/workflows: Personal “acceptance checklist”; portfolio updates emphasizing professional polish and consistency; service pages clarifying when AI is used.
- Assumptions/dependencies: Time to adjust offerings; client education; access to QA tools.
- Small business task triage
- Apply AI to narrow tasks with proven viability (audio/image variants, structured summaries, web scraping/visualizations) and keep human oversight for complex, multi-asset projects.
- Assumptions/dependencies: Clear task decomposition; comfort with basic evaluation; data privacy practices.
Long-Term Applications
These rely on further research, scaling, or ecosystem coordination before broad deployment.
Industry
- End-to-end autonomous remote work agents with embedded verification (software, design, architecture, marketing)
- Agents that plan, execute, verify, and self-correct across complex, multi-asset projects; integrate render tests and consistency checks natively.
- Potential tools/workflows: “Agent-of-record” project bots tied to PM systems; continuous self-critique/repair loops; artifact manifests with auditability.
- Assumptions/dependencies: Stronger multimodal reasoning; robust computer-use capabilities; reliable self-verification; legal clarity on liability and IP.
- Semi-automated acceptance testing and AI evaluators
- Train evaluators on RLI annotations to approximate the “reasonable client” standard, reducing human review load.
- Potential tools/workflows: Multimodal evaluation models; hybrid human-AI arbitration for edge cases.
- Assumptions/dependencies: High evaluator accuracy; calibration against human standards; governance for bias and drift.
- Autoflation-linked contracts, SLAs, and financial products
- Pricing models and insurance/hedging instruments tied to measured automation of specific digital work bundles.
- Potential tools/workflows: Category-indexed contracts; automation risk insurance for agencies/freelancers; CFO hedge strategies.
- Assumptions/dependencies: Reliable, audited indices; regulator acceptance; counterparty demand.
- AI-first marketplaces with escrowed automated QA
- Platforms where agents bid, execute, and pass automated acceptance checks before funds release; humans focus on creative direction and edge cases.
- Assumptions/dependencies: Trust in automated evaluation; dispute resolution frameworks; strong security and provenance.
Academia
- Longitudinal macro-labor studies linking RLI-style metrics to employment and wages
- Use automation rate and Autoflation to estimate sectoral shifts and productivity; test causal links with employment outcomes.
- Assumptions/dependencies: Access to labor microdata; careful identification strategies; updated indices.
- Expanded RLI variants that include client interaction and team workflows
- Simulate meetings, feedback loops, and multi-role coordination to evaluate broader classes of remote work.
- Potential tools/workflows: Multi-agent simulations; interactive briefs with revision rounds; collaboration testbeds.
- Assumptions/dependencies: Ethical data collection; realistic interaction modeling; standardized protocols.
- Certification schemes (“Remote Work Turing Test”) and standards
- Third-party certifications that a system meets defined acceptance rates across standardized project bundles.
- Assumptions/dependencies: Consensus on standards; governance by standards bodies (e.g., IEEE/ISO); periodic refresh cycles.
Policy
- Dynamic policy triggers tied to measured automation
- Use sustained increases in automation rate/Autoflation to trigger reskilling funds, wage subsidies, or tax credits in affected categories.
- Assumptions/dependencies: Statutory authority for dynamic triggers; transparent methodology; safeguards against gaming.
- Reporting and disclosure requirements for AI deployment claims
- Require firms to substantiate automation claims with benchmarked evidence (RLI-like) for investor, consumer, or labor disclosures.
- Assumptions/dependencies: Regulatory frameworks; standardized reporting templates; audit capacity.
- International comparability for cross-border services
- Harmonize RLI-like indices to inform trade in digital services, migration policy for remote work, and global training initiatives.
- Assumptions/dependencies: Shared taxonomies; multilingual and regionalized datasets; data-sharing agreements.
Daily Life
- Personal automation exposure dashboards and career planning
- Individuals receive category-level exposure scores, trendlines, and recommended upskilling paths tied to RLI-like indices.
- Potential tools/workflows: Career guidance apps; integration into job platforms; financial planning that considers automation risk.
- Assumptions/dependencies: Reliable category mappings; privacy-preserving analytics; up-to-date training resources.
- Community college and workforce system micro-credentials aligned to shifting indices
- Rapidly updated curricula that track rising/declining automation exposure in remote work categories.
- Assumptions/dependencies: Funding for continuous curriculum refresh; local employer partnerships; outcome tracking.
Notes on Core Assumptions and Dependencies
- Scope and representativeness: RLI covers remote, project-based work and excludes some categories (e.g., client interaction-heavy, back-end development, physical tasks). Applications should not overgeneralize beyond this scope.
- Data availability: Most of the benchmark is private to avoid contamination; public use relies on the released subset or similarly constructed internal corpora.
- Evaluation costs: Current methodology depends on trained human evaluators and a specialized platform; scaling requires budget or progress in automated evaluation.
- File/render support: Many applications depend on robust support for diverse file formats and reproducible rendering environments.
- Legal and IP: Use of deliverables (and AI-generated assets) requires clear permissions, provenance tracking, and compliance with licensing.
- Model and scaffold maturity: Several long-term applications require improved computer-use, multimodal verification, and self-correction capabilities.
- Index integrity: Adoption of “Autoflation” and automation-rate reporting assumes audited, low–false-positive evaluations and transparent methodologies.
Glossary
- Agentic tasks: Tasks that require autonomous, goal-directed interaction with dynamic environments, often performed by AI agents. "Efforts have broadened from evaluating closed-ended academic knowledge ... to include agentic tasks that require interaction with dynamic environments."
- Automation rate: The percentage of projects where the AI deliverable is judged to complete the project at least as well as the human deliverable. "The best-performing current AI agents achieve an automation rate of ."
- Autoflation: A metric for the percentage decrease in the cost of completing a fixed project bundle when using the cheapest successful method (human or AI). "Autoflation: The percentage decrease in the cost of completing the fixed RLI project bundle when using the cheapest-possible method to complete each project (human deliverable or an AI deliverable)."
- Blocklist: A curated list of domains to be excluded to prevent contamination or leakage into the benchmark. "To further protect against contamination in these cases, we include a blocklist of domains."
- Bradley-Terry: A probabilistic model for paired comparisons used to estimate latent utility scores (e.g., for Elo-style rankings). "Following the Chatbot Arena methodology \citep{chiang2024chatbot}, we use global Bradley-Terry fitting on sampled preference edges to compute utility scores..."
- Bootstrap samples: Resampled datasets (with replacement) used to estimate variability and confidence intervals of statistics. "We use $100$ bootstrap samples to compute confidence intervals in \Cref{fig:elo-rankings}."
- Computer-use agent (CUA): An AI agent scaffold that operates through a graphical computer-use environment, as opposed to a command-line interface. "...we refer to as a command line interface (CLI) environment as opposed to a computer-use agent (CUA) environment."
- Elo: A rating system that captures relative performance via pairwise comparisons; differences correspond to odds of winning. "Elo: A score capturing the relative performance of different AI agents."
- Gold-standard deliverable: The professional human-produced output used as the reference for successful project completion. "Human deliverable: A gold-standard deliverable that successfully completes the project, produced by a professional"
- Holistic evaluation: An assessment method that judges overall project completion and quality rather than relying solely on granular rubrics. "Consequently, we employ a holistic evaluation approach (visualized in Figure \ref{fig:evaluation_pipeline})..."
- Human baseline: The reference level of performance set by human deliverables; used to anchor scores (e.g., Elo at 1000). "We canonicalize scores so that the human baseline Elo is fixed at ."
- Inter-annotator agreement: A reliability measure indicating the consistency of judgments across multiple evaluators. "The evaluation process demonstrates high reliability, with an inter-annotator agreement of for the automation rate metric."
- Likert scale: An ordinal rating scale (e.g., 3-point) used to capture evaluators’ judgments on completion and quality dimensions. "Evaluators assess the comparison along two dimensions using separate $3$-point Likert scales:"
- Long tail: The large number of infrequent or niche categories in a distribution of work types. "Digital labor marketplaces contain a substantial long tail of work."
- Majority voting: A decision rule where the final judgment is determined by the most common choice among evaluators. "We use majority voting across three independent evaluations to determine the final judgment."
- O*NET taxonomy: A standardized occupational classification used for describing jobs and skills, here contrasted with Upwork’s categories. "In preliminary analysis, we found that the O*NET taxonomy, while valuable for long-term occupations, was less tailored to the remote labor markets represented in RLI..."
- Pairwise comparison system: A method that compares two deliverables head-to-head to derive relative preferences and rankings. "To detect more granular shifts in performance, we employ an Elo-based pairwise comparison system."
- Stratified sampling: A sampling technique that ensures representation across predefined groups (e.g., models) in comparisons. "We use stratified sampling across models to ensure each model pair is compared on at least $10$ projects..."
- Upwork taxonomy: The category system used by Upwork to classify freelance work types, employed to structure RLI’s coverage. "RLI captures a wide array of project types, spanning $23$ categories of work from the Upwork taxonomy."
Collections
Sign up for free to add this paper to one or more collections.