GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Abstract: We introduce GDPval, a benchmark evaluating AI model capabilities on real-world economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GDPval, a big “reality check” test for AI. Instead of quizzing AIs with puzzles or school-style questions, GDPval asks them to do real work that professionals get paid to do—things like writing reports, making spreadsheets, designing slides, analyzing data, or reviewing contracts. The goal is to see how well AI models perform on tasks that actually matter to the economy.
What questions are the researchers trying to answer?
They focus on a few simple questions:
- Can today’s best AI models produce work that’s as good as what experienced professionals make?
- Are AIs getting better over time on real, job-like tasks?
- If humans use AI as a helper, can they finish work faster and cheaper?
- What boosts AI performance more: giving it more time to think, more context, or better instructions and tools?
- Can we build a fair, repeatable way to measure AI on real-world tasks and share it with others?
How did they test this?
Here’s how the benchmark works, in everyday terms:
- Picking the jobs: The team looked at the nine biggest parts of the U.S. economy (like real estate, manufacturing, finance, healthcare, and tech) and selected 44 common, mostly computer-based jobs within them.
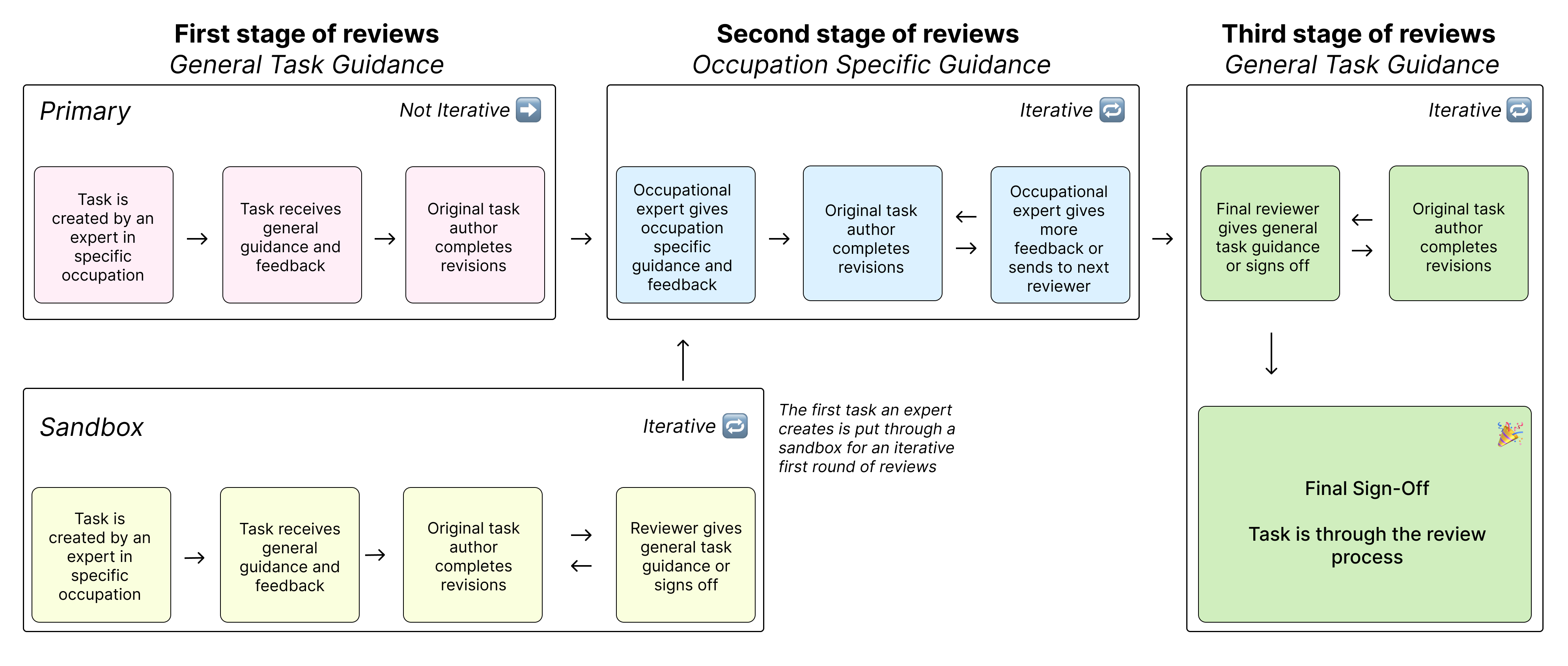
- Gathering real tasks: They hired industry experts (average 14 years of experience) to create tasks based on their actual work—like “clean this messy dataset and summarize trends” or “turn these notes into a client-ready slide deck.” Each task came with a clear request and real reference files (documents, PDFs, images, spreadsheets, etc.).
- Estimating value: Each task had an estimated time-to-complete and a dollar value based on typical wages for that job.
- Quality control: Every task went through multiple rounds of checks by other experts to make sure it was realistic, clear, and representative of the job.
- Head-to-head grading: For grading, experts were shown two anonymous deliverables side by side—one from a human expert and one from an AI—and asked, “Which one is better?” This is like a blind taste test for work quality. The main score is the “win rate,” meaning how often the AI’s work was preferred or tied.
- Automated grader (experimental): They also trained an AI “judge” to mimic expert judgments on a 220-task “gold subset” they open-sourced. This judge agreed with humans about two-thirds of the time (66%), which is close to how often human experts agree with each other (71%).
- Extra experiments: They tested whether AIs do better when you:
- Let them “think” more (increase reasoning effort),
- Give them more background files and context,
- Add “scaffolding” like checklists, quality checks, or trying multiple drafts and picking the best.
What did they find, and why does it matter?
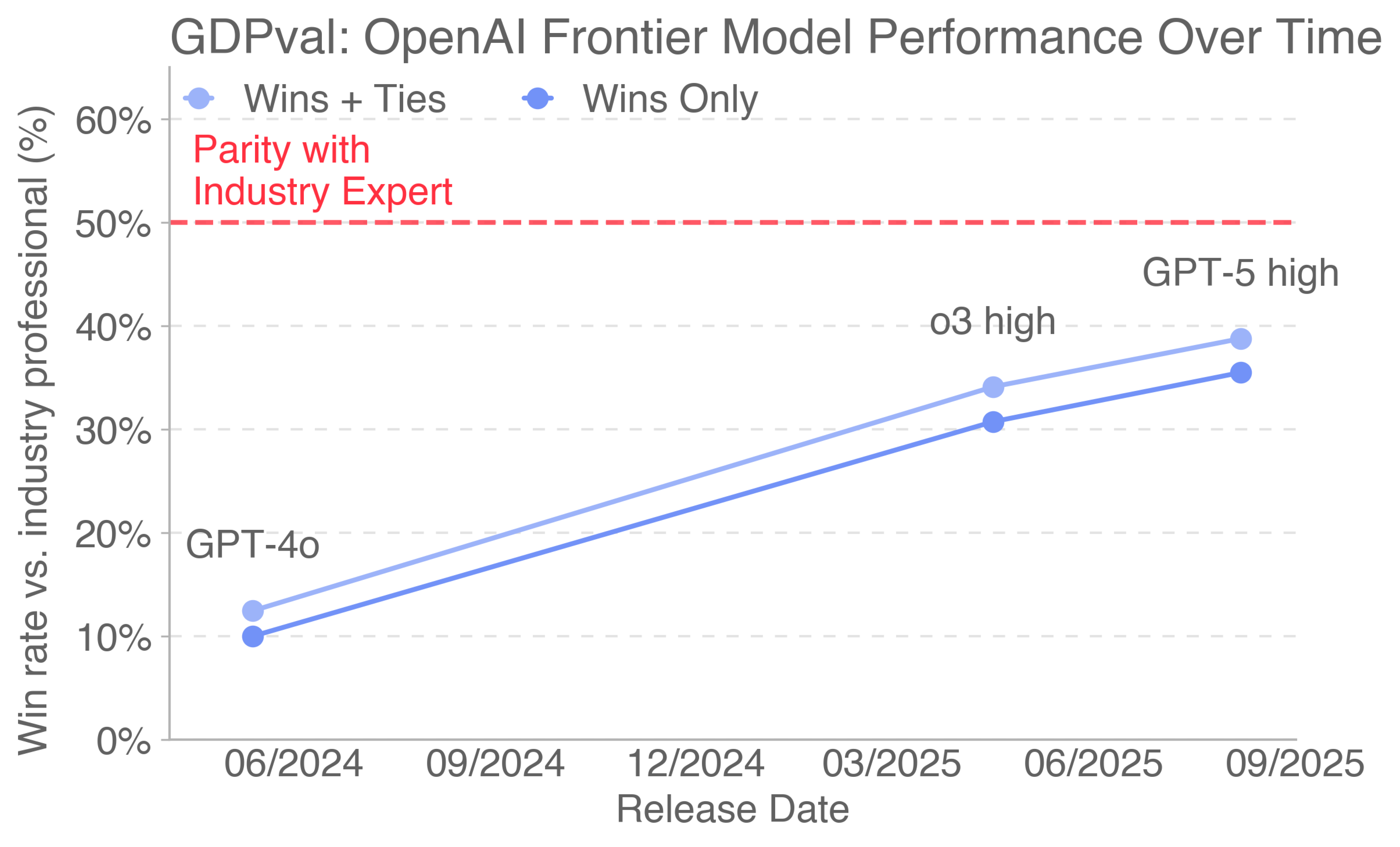
- Models are getting better, steadily: The performance of top AI models on these real tasks has been rising roughly linearly over time.
- Approaching expert quality: On the shared gold subset, the best model (Claude Opus 4.1) had its deliverables preferred or tied about 47.6% of the time against human experts—close to parity in a blind comparison. Different models had different strengths:
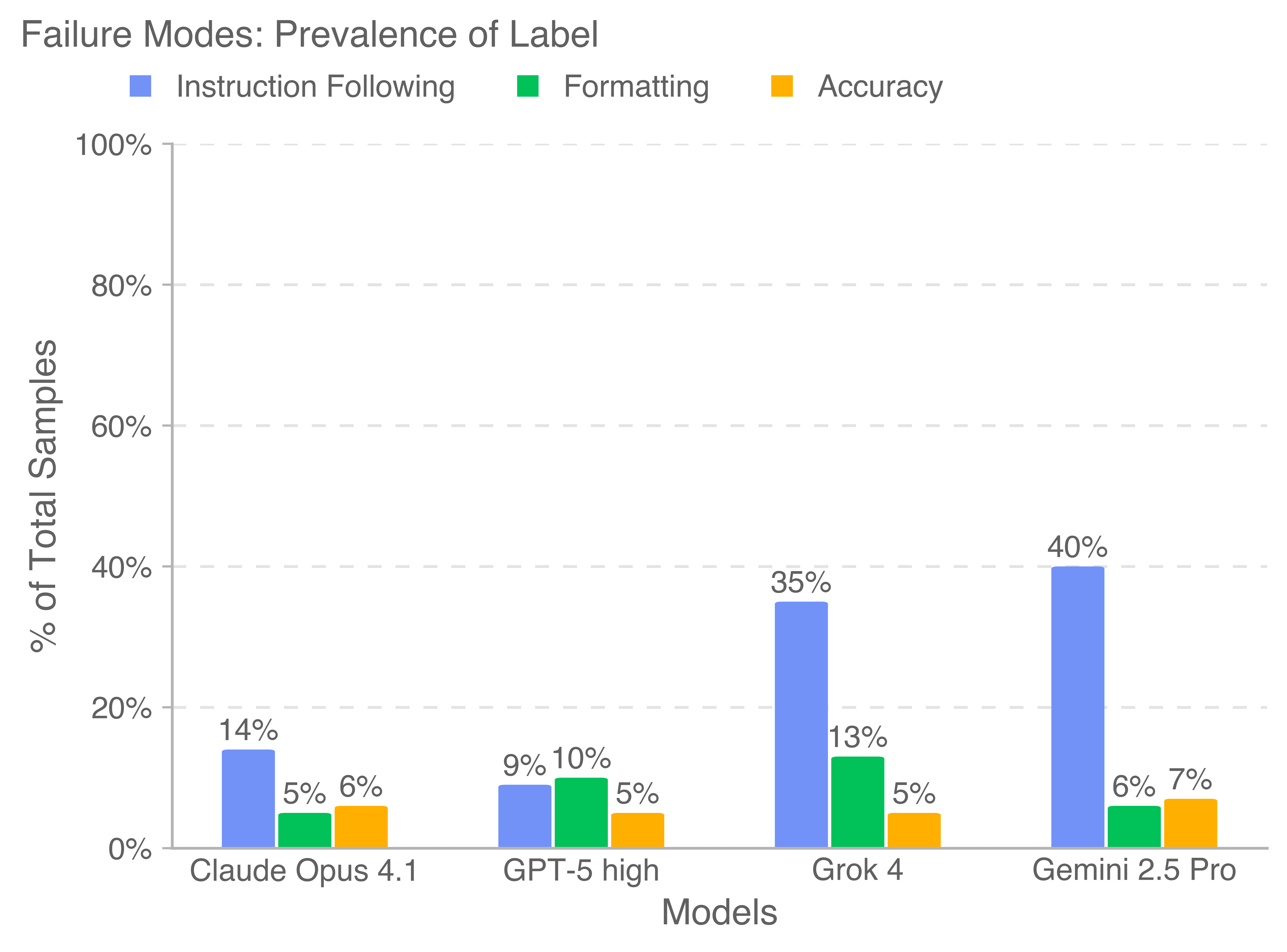
- Claude often produced nicer-looking documents (better formatting and layouts).
- GPT-5 tended to be more accurate and better at following instructions.
- Some models struggled by not fully following directions or by formatting badly.
- Real-world tasks are hard and long: These aren’t quick prompts. The average human expert needs about 7 hours per task; some tasks take weeks. Many require handling multiple file types (PDFs, slides, spreadsheets, images, audio, etc.).
- Human + AI can save time and money: When experts use AI as an assistant—try the AI, review its work, and fix or redo if needed—there’s potential for meaningful time and cost savings compared to doing everything manually.
- More thinking and better setup help: Letting the AI spend more effort reasoning, giving it more context, and building better “scaffolding” (like self-checks and best-of-N sampling) reliably improved results. Simple prompt changes, like reminding the model to check formatting and render previews of files, reduced errors and improved human preference scores.
- Open resources for the community: The team released 220 high-quality tasks (the gold subset) and a public, automated grading service at evals.openai.com to help others study real-world AI capability.
Why could this be important?
- Earlier, clearer signals: Traditional economic measures (like GDP growth or company adoption) take years to show changes. GDPval provides a “front-row view” of AI’s practical skills now, so companies, researchers, and policymakers can track progress sooner.
- Practical guidance for work: Knowing where AIs are already strong or weak helps managers decide which tasks to automate, where to keep humans in the loop, and how to design workflows that save time without losing quality.
- Better training for AI: The benchmark highlights common failure modes—especially instruction-following and formatting—showing model builders where improvements matter most.
- Building a common standard: A public, realistic benchmark helps everyone compare models fairly, see progress, and avoid overhyping or underestimating what AI can do in real jobs.
A quick note on limits
- It’s a first step: GDPval currently covers 44 occupations and focuses on computer-based “knowledge work.” Hands-on, physical jobs and highly interactive, back-and-forth tasks aren’t included yet.
- One-shot tasks: Most tasks provide full context up front, while real jobs often require clarifying questions or collaboration. Future versions aim to add more interactivity.
- Automated grader is not perfect: It’s helpful and fast, but still not as reliable as human experts.
Bottom line
GDPval is like a “job-reality benchmark” for AI. It shows that top AI models are getting steadily better at producing valuable work products and are starting to approach expert quality in many cases—especially when given time to think, good context, and helpful scaffolding. Used wisely with human oversight, these models can help professionals work faster and cheaper. By open-sourcing a chunk of tasks and a grader, the authors hope to speed up research and give the world a clearer, earlier picture of how AI is changing real work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- External validity across sectors and geographies: The benchmark targets 9 U.S. GDP-leading sectors and 44 occupations; it does not test occupations outside these sectors, non-U.S. contexts, lower-income labor markets, non-English tasks, or public-sector/third-sector contexts where workflows and constraints differ substantially.
- Manual/physical and hybrid work exclusion: The current focus on predominantly digital, computer-based knowledge work excludes manual, field, and hybrid tasks (e.g., on-site inspections, lab bench work, healthcare interactions) where AI assistance may have different constraints and value.
- Interaction and workflow realism: Tasks are one-shot and precisely specified, omitting multi-turn clarification, stakeholder negotiation, and evolving requirements typical of real-world workflows; the degree to which model parity holds under interactive, multi-party, long-horizon processes remains untested.
- Tacit knowledge and proprietary systems: Tasks avoid tacit knowledge, PII, proprietary enterprise systems, and toolchains; performance and feasibility when models must navigate organizational context, authorization, compliance, and internal software remains unknown.
- Representativeness of task coverage within occupations: While claimed to cover “majority of O*NET Work Activities,” the mapping from expert-created tasks to O*NET activities is not audited for completeness per occupation; researchers lack a per-occupation coverage report showing which activities are underrepresented or missing.
- Digital task classification validity: Occupation “digitalness” was determined by GPT-4o classification of O*NET tasks with a 60% threshold; the accuracy of this classification, sensitivity to the threshold, and robustness versus human-coded baselines are not quantified.
- Human baseline quality calibration: The human deliverable baseline quality and variability are not characterized (e.g., inter-expert differences, rubric alignment, quality assurance); future work should benchmark human baselines against standardized professional rubrics and multiple expert exemplars.
- Pairwise grading reliability and granularity: Inter-rater agreement is reported (71%) but not analyzed by occupation, modality, or difficulty; confidence intervals and task-level reliability statistics are missing, limiting conclusions about consistency and fairness across domains.
- Style identifiability confounds: Graders may infer model identity from stylistic cues (e.g., em dashes, self-referential phrasing); the magnitude of bias introduced by identifiability is not measured, and methods to eliminate or counterbalance it are not evaluated.
- Autograder transparency and generalization: The automated grader’s training data, model architecture, and safeguards against “LLMs favor their own generations” bias are not detailed; its generalization across occupations, modalities, and new task distributions is unknown.
- Metric sufficiency and sensitivity: Win/tie rates capture preference but not effect sizes, error types, or business-critical correctness; the benchmark lacks standardized rubrics per occupation and calibrated sub-scores (e.g., accuracy, compliance, aesthetics, stakeholder appropriateness).
- Predictive validity for economic outcomes: The link between GDPval win rates and actual productivity, cost savings, task automation rates, or firm performance is not established; longitudinal studies relating benchmark scores to adoption and measured ROI are needed.
- Cost and speed estimation realism: Human completion and review times are self-reported/observed in grading contexts, not production; API costs and latencies are vendor-specific and environment-dependent. The sensitivity of savings to resampling strategies, oversight thresholds, and model/tool configurations is not quantified.
- Missing cost data for non-OpenAI models: Cost analyses exclude Claude, Gemini, and Grok due to unavailable estimates; without standardized, reproducible cost/latency logging across vendors and tools, comparative economic conclusions remain incomplete.
- Tooling parity and environment standardization: Different models had different tools/features enabled (e.g., code interpreter, web search, file creation features, preinstalled libraries); the impact of tool parity on performance is not isolated, and a standardized sandbox across vendors is lacking.
- Best-of-N and judge bias: Prompt-tuning experiments use best-of-N sampling with a GPT-5 judge; the effect of using model-specific judges on outcomes (home-field advantage) is not measured, nor are cross-judging protocols tested for fairness.
- Modalities and file-type comparability: Performance differences by deliverable type (e.g., PDFs, PPTs, XLSX) are reported but confounded by occupation mix and aesthetic weighting; controlled experiments that hold occupation/task constant while varying modality are missing.
- Failure modes root-cause analysis: Instruction-following failures and formatting errors are cataloged but not linked to specific model capabilities (e.g., planning, tool-use, file IO, schema adherence); ablation studies isolating root causes and targeted training interventions are not presented.
- Long-horizon and dependency complexity: Tasks average 7 hours of expert work but are evaluated via one-shot model outputs; effects of long-horizon dependencies, subtask decomposition quality, and iterative revision dynamics are not tested.
- Benchmark growth and saturation risks: The “no upper limit” win-rate framing lacks statistical modeling for ceiling effects, task drift, and benchmark inflation; protocols to refresh tasks, guard against overfitting, and maintain difficulty calibration over time are unspecified.
- Time-trend claims without statistical rigor: “Roughly linear” performance improvements over time are shown but lack formal trend analyses, significance testing, and controls for benchmark changes or sampling variance.
- Under-contextualization effects: The appendix mentions performance degradation under reduced context but does not quantify the sensitivity curve or propose standardized context-availability regimes for comparative testing.
- Safety and compliance assessment: Some tasks include NSFW/political content, but systematic evaluation of safety, compliance, data handling, and policy adherence under realistic constraints is absent.
- Cross-occupation fairness and bias: The benchmark does not analyze whether certain occupations or demographics of tasks (e.g., culturally sensitive content) yield systematic model or grader biases; fairness audits and subgroup analyses are missing.
- Reproducibility of deliverables and grading: The open-source gold subset includes prompts and references but not full human/model deliverables nor grading rationales for all tasks; independent replication of headline results is limited.
- Reviewer learning effects: Review times rely on first-time grading observations; the effect of grader learning/familiarity on speed, accuracy, and consistency over repeated exposure is not studied.
- Acceptance thresholds and business criteria: The “try n times then fix” scenario assumes a simplistic acceptance threshold; real workflows involve risk tolerances, compliance checks, and stakeholder approvals not modeled in the cost/speed analysis.
- Error cost modeling: Economic analysis does not incorporate the cost of model-induced errors (e.g., compliance violations, rework, reputational damage), which could materially change ROI estimates.
- Occupational wage proxy limitations: Task dollar value uses median wages, likely underestimating senior expert costs and ignoring benefits, overhead, and market heterogeneity; more realistic firm-level cost models are needed.
- Language and cultural nuance: Tasks appear English-centric; the impact of multilingual, cross-cultural communication and localization requirements on performance remains unexplored.
- Dataset curation and selection bias: Experts with strong resumes created tasks; the extent to which this skews task style, difficulty, and expectations relative to typical industry distributions is not evaluated.
- Benchmark governance and conflict-of-interest: With OpenAI authors and infrastructure, vendor-neutral governance, independent auditing, and transparent evaluation protocols are needed to mitigate perceived or actual conflicts and ensure trust.
- Occupation-specific rubrics and success criteria: Many occupations have standardized deliverable checklists (e.g., legal, accounting, engineering); integrating these into grading rubrics could yield more actionable, objective evaluations—currently absent.
- Multi-agent and collaboration scenarios: The benchmark does not test AI collaborating with multiple humans or other AI agents across roles; orchestration, handoff quality, and version control dynamics are unmeasured.
- Data privacy and enterprise integration: Realistic enterprise scenarios require secure data access, permissions, and audit trails; performance and feasibility with privacy-preserving retrieval and enterprise connectors are not assessed.
- Benchmark maintenance and task updating: There is no plan described for updating tasks as tools, regulations, and industry practices evolve, nor for tracking concept drift and maintaining longitudinal comparability.
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings, methods, and innovations. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development). Within each group, items are organized by sector and stakeholder (industry, academia, policy, and daily life), and include assumptions or dependencies where relevant.
Immediate Applications
These items can be put into practice with existing models, the GDPval gold subset, and the public automated grader at evals.openai.com.
Industry
- Sector-wide model procurement and fit-for-purpose selection
- Use case: Evaluate and select frontier models for specific deliverable types and occupations using the GDPval gold subset and blinded, pairwise human grading.
- Sectors: Professional services, finance, information, manufacturing, real estate, government, retail, wholesale, healthcare administration.
- Tools/products/workflows: Internal “acceptance testing” harnesses; model scorecards by occupation/task type; evals.openai.com for quick proxy grading; dashboards tracking win-rate by deliverable file type.
- Assumptions/dependencies: Access to frontier models; organizational willingness to run evaluations; representativeness of GDPval tasks for your workflows; data privacy controls.
- Human-in-the-loop AI production for complex deliverables
- Use case: Operationalize the “try n times, then fix it yourself” workflow to reduce cost/time on multi-hour tasks, with expert review gating AI outputs.
- Sectors: Professional services (legal, accounting, project management), finance (analyst decks), information (editing, producers), manufacturing (purchasing/operations documentation).
- Tools/products/workflows: Best-of-N sampling with a model-based judge; checklists for instruction-following; routing based on an automated grader threshold; reviewer SLAs.
- Assumptions/dependencies: Review capacity and training; adherence to compliance and security guidelines; model tool-use (code interpreter, file creation/analysis) enabled.
- Deliverable-quality prompt libraries and formatting QA
- Use case: Adopt the paper’s prompt-scaffolding ideas to automatically render and inspect outputs, eliminate Unicode issues, and reduce PDF/PPT artifacts.
- Sectors: Information (producers, editors), finance (investment memos), manufacturing (engineering reports), real estate (marketing brochures).
- Tools/products/workflows: Prompt packs for multi-modal deliverables; automatic layout rendering; linting/format checks for spreadsheets, slides, PDFs.
- Assumptions/dependencies: Models support file rendering/inspection; stable multi-modal toolchains; internal content style guides.
- Task triage and job redesign using GDPval task taxonomy
- Use case: Identify high-value, high-duration tasks most amenable to AI assistance; redesign roles to emphasize oversight, context collection, and final QA.
- Sectors: All nine GDP sectors covered (e.g., healthcare administration, retail operations, wholesale sales ops).
- Tools/products/workflows: O*NET-aligned task inventories; triage matrices (AI-first vs. human-first vs. hybrid); role descriptions that allocate time to AI supervision.
- Assumptions/dependencies: Accurate mapping of your work activities to O*NET-like task statements; change management support.
- Model selection by deliverable type (text accuracy vs. aesthetics)
- Use case: Prefer models that are stronger at accuracy for text-heavy tasks (e.g., GPT-5) and models that excel at layout/aesthetics for PPT/PDF/XLSX-heavy deliverables (e.g., Claude Opus 4.1).
- Sectors: Professional services, finance, information, real estate marketing.
- Tools/products/workflows: File-type specific routing; blended ensembles for mixed deliverables; style consistency checks.
- Assumptions/dependencies: Ongoing benchmarking as models evolve; acceptance of blended outputs.
- Automated pre-screening of AI outputs with the GDPval grader
- Use case: Use the public automated grader as a fast, inexpensive pre-screen to triage outputs before expert review.
- Sectors: Any sector producing digital deliverables at volume.
- Tools/products/workflows: CI-like gating for documents; threshold-based routing; feedback loops to prompt libraries.
- Assumptions/dependencies: Grader agreement currently ~66% vs. human experts (within 5% of human inter-rater agreement); not a full substitute for expert review.
- Workforce training on known failure modes
- Use case: Train staff to spot instruction-following failures, formatting errors, ignored references, and hallucinations noted in the paper’s clustering analysis.
- Sectors: All.
- Tools/products/workflows: Reviewer playbooks; checklists; sample libraries of “good” and “bad” outputs; targeted remediation prompts.
- Assumptions/dependencies: Availability of training time; culture of systematic review; tracking of error categories.
- Real estate operations
- Use case: Generate listing materials, lease summaries, and community communications with human review, routing text vs. aesthetic-heavy tasks to the best model.
- Tools/products/workflows: Prompt packs for property brochures; spreadsheet-based comps; PDF/PPT layout QA.
- Assumptions/dependencies: Access to market data; compliance with fair housing laws; privacy for client information.
- Manufacturing operations and engineering documentation
- Use case: Draft purchasing analyses, inventory summaries, and engineering reports with automated formatting checks and best-of-N sampling.
- Tools/products/workflows: Spreadsheet linting; CAD-related file handling (where allowed); reviewer QA gates.
- Assumptions/dependencies: Licensing and IP policies for proprietary formats; alignment with safety and quality standards.
Academia
- Benchmark-driven capability research
- Use case: Use the gold subset to study reasoning-effort scaling, prompt scaffolding, and context dependence; replicate paper’s ablations.
- Tools/products/workflows: Open-source tasks; automated grader; analysis notebooks; failure-mode taxonomies.
- Assumptions/dependencies: Ethical use approvals; compute budget; reproducibility protocols.
- Course modules and lab assignments
- Use case: Incorporate GDPval tasks into courses on HCI, AI for productivity, and multi-modal systems; teach students prompt design and output QA.
- Tools/products/workflows: Classroom-friendly subsets; standardized rubrics; human-vs-model comparison exercises.
- Assumptions/dependencies: Appropriate content filtering (NSFW/political tasks where necessary); institutional guidelines.
- Research on evaluation methodologies and graders
- Use case: Develop improved automated graders for multi-modal, subjective deliverables; study inter-rater reliability and grader bias.
- Tools/products/workflows: New model architectures for grading; hybrid human+AI panels; reliability audits.
- Assumptions/dependencies: Access to diverse expert graders; statistical power for agreement estimates.
Policy
- Occupational task automation heatmaps
- Use case: Use GDPval’s occupation/task mapping to inform reskilling priorities and workforce development targeting.
- Tools/products/workflows: Sectoral dashboards; alignment with O*NET task content; grants targeting high-duration/high-savings tasks.
- Assumptions/dependencies: Benchmark coverage is digital knowledge work–heavy; not comprehensive of physical/tacit tasks.
- Public-sector procurement standards
- Use case: Require GDPval-like evaluation in AI procurement to compare models on realistic tasks; mandate human oversight for sensitive outputs.
- Tools/products/workflows: Standardized evaluation protocols; compliance checklists; measurable win-rate/accuracy thresholds.
- Assumptions/dependencies: Budget for evaluations; agency capacity to run pairwise comparisons; privacy/security frameworks.
- Evidence for productivity and adoption policies
- Use case: Use speed/cost estimates and “try n times then fix” policies to assess expected economic benefits and lags.
- Tools/products/workflows: Cost-benefit calculators; pilot programs; longitudinal tracking of win-rates and time-to-quality.
- Assumptions/dependencies: Transparent reporting; careful generalization beyond the gold subset.
Daily Life
- Freelancers and small businesses: deliverable acceleration
- Use case: Apply best-of-N sampling, deliverable QA prompts, and model routing (accuracy vs. aesthetics) to client documents, decks, and spreadsheets.
- Tools/products/workflows: Prompt templates; checklists; simple grading proxies.
- Assumptions/dependencies: Tool access; data confidentiality; client acceptance of AI-assisted workflows.
- Personal productivity for complex multi-file tasks
- Use case: Use models for long-form outputs (reports, plans) with the paper’s QA prompt to reduce formatting errors; review before delivery.
- Tools/products/workflows: Document render-and-check prompts; file-type-specific linting.
- Assumptions/dependencies: Model tool support; time for review; privacy of reference files.
Long-Term Applications
These items require further research, scaling, more interactive tasks, stronger graders, or organizational/regulatory development.
Industry
- Sector-specific copilots for 44+ occupations
- Use case: Build robust, multi-modal agents that deliver complete, high-quality work products (PPT/PDF/XLSX/CAD) with interactive context gathering and continuous QA.
- Sectors: All nine GDP sectors and beyond; expansion into physical/tacit tasks via integrations.
- Tools/products/workflows: Enterprise-grade agent platforms; integration with ERP/CRM/DMS; standardized acceptance tests derived from GDPval.
- Assumptions/dependencies: Advances in instruction-following and multi-modal tool use; stronger reliability guarantees; secure data integrations.
- Organization-wide AI productivity scorecards and governance
- Use case: Continuous model performance tracking against GDPval-like tasks; automated risk/benefit registers; compensation and budgeting aligned to verified time/cost savings.
- Tools/products/workflows: “Economic capability” dashboards; audit trails; change-management programs; role redesign at scale.
- Assumptions/dependencies: Cultural buy-in; robust evaluation pipelines; clear legal/compliance frameworks.
- End-to-end automation of long-horizon workflows
- Use case: Agents that autonomously collect context, iterate with stakeholders, and finalize deliverables to expert standards, minimizing human touchpoints.
- Tools/products/workflows: Interactive task orchestration; stakeholder “agent interfaces”; continuous validation and error recovery.
- Assumptions/dependencies: Reliable interactivity; stakeholder trust; safety controls; model parity or surpassing expert-level outputs.
Academia
- Expanded, interactive, and global benchmarks
- Use case: Build larger, more diverse datasets covering tacit knowledge, proprietary tools, interactivity, and communication across cultures and languages.
- Tools/products/workflows: Multi-turn tasks; privacy-preserving evaluation frameworks; cross-country O*NET-like mappings.
- Assumptions/dependencies: Partnerships with industry and public institutions; funding; ethical review.
- Advanced automated graders exceeding human agreement
- Use case: Develop graders with higher reliability for subjective aesthetics and complex multi-modal deliverables; formalize grading validity.
- Tools/products/workflows: Multi-signal grading (layout, style, correctness); cross-validated rubrics; adversarial tests for grader bias.
- Assumptions/dependencies: Access to rich human-graded corpora; theoretical frameworks for subjective evaluation.
- Macro-level measurement of AI’s economic impact
- Use case: Link capability trajectories (win-rates over time) to productivity and adoption models; refine the “implementation lag” and intangible capital measurements.
- Tools/products/workflows: Longitudinal studies combining GDPval performance, firm outcomes, and national statistics.
- Assumptions/dependencies: Stable measurement pipelines; cooperation from firms; robust econometric methods.
Policy
- National standards for AI capability evaluation
- Use case: Codify GDPval-like benchmarks for procurement, certification, and compliance; tie public funding to demonstrable capability and oversight.
- Tools/products/workflows: Sector-specific test suites; certification schemes; minimum human-in-the-loop requirements.
- Assumptions/dependencies: Policy consensus; coordination with standards bodies; updates as models evolve.
- Labor market forecasting and targeted reskilling
- Use case: Use task-level evidence to forecast displacement/complementarity; design reskilling programs for oversight-heavy roles and agent operations.
- Tools/products/workflows: Regional skill maps; grant targeting; longitudinal reskilling outcome tracking.
- Assumptions/dependencies: Benchmark expansion into more occupations; integration with workforce data.
- Measurement updates to national accounts
- Use case: Incorporate validated AI-driven productivity gains and intangible capital into national statistics; reduce mismeasurement of AI’s impact.
- Tools/products/workflows: Data-sharing pipelines; standardized reporting of AI-assisted output; model capability indices.
- Assumptions/dependencies: Collaboration between statistical agencies, academia, and firms; privacy-preserving methodologies.
Daily Life
- Consumer-grade multi-modal personal work assistants
- Use case: Agents that manage complex projects (planning, budgeting, report generation) with automatic formatting QA, context gathering, and stakeholder coordination.
- Tools/products/workflows: Cross-device agent platforms; plug-ins for office suites; persistent memory and task tracking.
- Assumptions/dependencies: Reliability improvements; privacy/security guarantees; intuitive UX for oversight.
- New roles and micro-enterprises around AI oversight
- Use case: Emergence of “AI deliverable reviewers,” “prompt librarians,” and “agent operators” offering specialized services to individuals and small firms.
- Tools/products/workflows: Marketplaces for oversight; standardized checklists; micro-certifications based on GDPval-like tasks.
- Assumptions/dependencies: Broad acceptance of AI-assisted outputs; accessible training; portable credentials.
- Personalized career navigation and skills development
- Use case: Individuals practice GDPval-style tasks to build portfolios, understand where AI can complement their skills, and target reskilling paths.
- Tools/products/workflows: Portfolio builders; task practice hubs; skill-gap analytics.
- Assumptions/dependencies: Expanded, open datasets; fair access to tools; guidance that adapts as models improve.
Notes on feasibility: Many immediate applications depend on human oversight; secure, compliant access to multi-modal model tools; and careful model routing by deliverable type. Long-term applications hinge on stronger interaction capabilities, higher grader reliability, richer datasets, and institutional adoption of standardized evaluations.
Collections
Sign up for free to add this paper to one or more collections.

