How Well Does Agent Development Reflect Real-World Work?
Abstract: AI agents are increasingly developed and evaluated on benchmarks relevant to human work, yet it remains unclear how representative these benchmarking efforts are of the labor market as a whole. In this work, we systematically study the relationship between agent development efforts and the distribution of real-world human work by mapping benchmark instances to work domains and skills. We first analyze 43 benchmarks and 72,342 tasks, measuring their alignment with human employment and capital allocation across all 1,016 real-world occupations in the U.S. labor market. We reveal substantial mismatches between agent development that tends to be programming-centric, and the categories in which human labor and economic value are concentrated. Within work areas that agents currently target, we further characterize current agent utility by measuring their autonomy levels, providing practical guidance for agent interaction strategies across work scenarios. Building on these findings, we propose three measurable principles for designing benchmarks that better capture socially important and technically challenging forms of work: coverage, realism, and granular evaluation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple, important question: Are the tests we use to build and judge AI “agents” (computer programs that act step-by-step, like a person using a browser or desktop) really similar to the kinds of work people do in real jobs? The authors look at many popular agent benchmarks (collections of test tasks) and compare them to real-world jobs and skills to see where AI agent development matches human work—and where it doesn’t.
What questions did the paper ask?
To make this idea easy to understand, the paper focused on a few basic questions:
- Which job areas (like management, law, or software) do agent benchmarks mostly test, and how does that compare to where most people actually work?
- Which skills (like finding information, talking to people, or making things) do these benchmarks focus on, and are those the skills most jobs need?
- How “independent” can today’s agents be on real work tasks? In other words, how complicated a task can they reliably do on their own?
- How can we design better benchmarks that reflect socially important, realistic, and challenging work—not just what’s easy to test?
How did the researchers study this?
The authors connected the world of AI benchmarks to the world of real jobs using two “maps” of work:
- A domain map (what job area the work belongs to), like Business, Legal, Healthcare, or Computer & Math.
- A skill map (what actions the work requires), like getting information, interacting with people, thinking through problems, or producing work.
They built these maps using O*NET, a large U.S. government database that describes thousands of occupations, their tasks, and the skills involved. Then they:
- Collected 43 agent benchmarks with 72,342 tasks and matched each task to its domains and skills using a LLM plus human checks. Think of this like asking a careful assistant to read a task and assign it to the right shelves in a library of jobs and skills.
- Compared where agent tasks are concentrated to where human employment and wages are concentrated, using data from the U.S. Bureau of Labor Statistics.
- Measured how “complex” tasks are by breaking agent actions into a workflow—like turning a big school project into smaller steps—and counted how many independent steps a task needs.
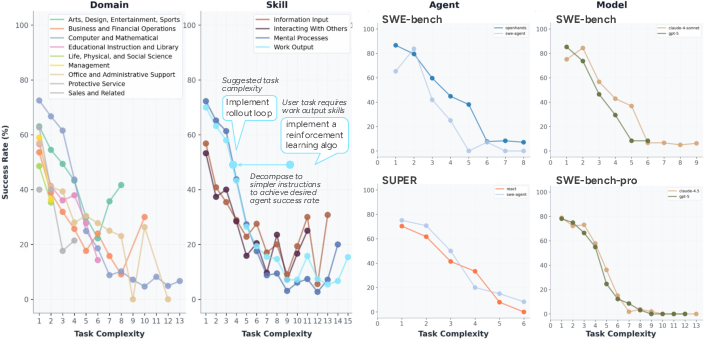
- Defined “autonomy” as the most complex tasks an agent can complete end-to-end with a good success rate. This is like asking: up to how many steps can the agent handle reliably on its own?
To keep the analysis efficient and fair, they sampled tasks in a way that preserved the variety of domains and skills in each benchmark, and they also validated the mapping quality with human reviewers.
What did they find?
Here are the main takeaways:
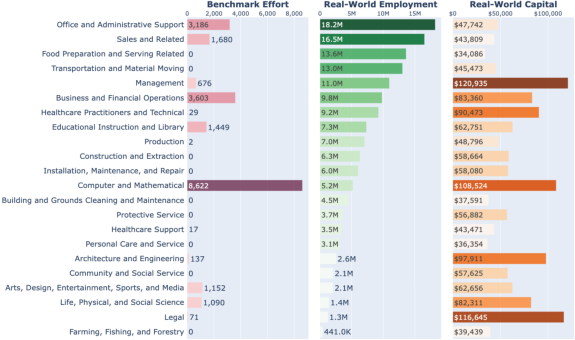
- Agent development is heavily focused on programming. Most benchmarks concentrate on the Computer & Math domain, which is only a small slice of U.S. jobs (about 7.6%). Meanwhile, highly digital, high-impact areas like Management and Legal are barely represented, even though a lot of their work happens on computers and affects big parts of the economy.
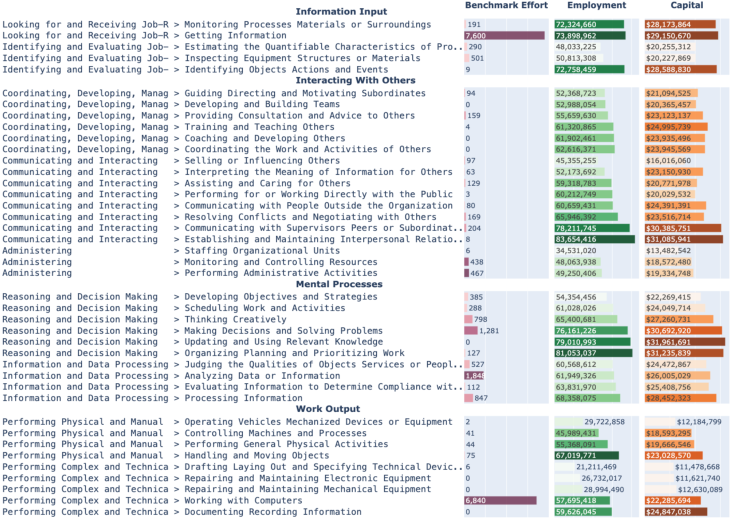
- Benchmarks overemphasize a few narrow skills. Tasks often focus on “getting information” and “working with computers,” which together correspond to a small part of what workers do. Skills that involve interacting with people—like coordinating, persuading, or resolving conflicts—are common in real jobs but show up far less in agent tests.
- Many benchmark tasks are simpler than real work. Real jobs often mix several domains and multiple skills. While some tasks in benchmarks do span multiple skills, a large chunk use just one or a few, missing the broader context and messy details of workplace tasks.
- Agent autonomy drops as tasks get more complex. Agents can often do simple, self-contained steps (like routine coding or data processing) but struggle as tasks require more steps, uncertainty, or coordination, especially in domains beyond software. Even in coding, success rates fall quickly as tasks become multi-step and interdependent.
Why this matters:
- If we keep testing agents mostly on programming or very narrow digital skills, we won’t know how well they handle the types of work most people actually do.
- Underrepresenting domains like Management and Legal means we miss chances to create agents that help with decision-making, planning, compliance, and complex coordination—areas that could have big economic and social impact.
Why does this matter?
This research suggests we should redesign how we test AI agents so their progress matches real workplace needs. That means:
- Covering more job areas, especially ones that are both digital and economically important (like Management and Legal).
- Including more people-centered skills, such as communication and coordination.
- Making tasks more realistic and multi-step, not just simplified puzzles.
- Evaluating agents with finer-grained checkpoints (intermediate steps), so we can see where they succeed or fail within a workflow, not only at the final answer.
The paper offers three clear principles for building better benchmarks:
- Coverage: Include a wider range of domains and skills, not just the easy-to-test ones.
- Realism and complexity: Reflect the messy, multi-step nature of real work.
- Granular evaluation: Measure progress at intermediate steps to understand agent limits and guide improvement.
Final thoughts
In short, today’s AI agent tests don’t fully reflect the work most people do. By mapping benchmarks to real jobs and skills, measuring task complexity, and defining agent autonomy clearly, this paper gives a roadmap for more meaningful agent development. If researchers and companies follow these guidelines, future AI agents could be more helpful in real workplaces—supporting not only programmers, but also managers, legal teams, office staff, and many other professionals—while working at the right level of autonomy for each task.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing or uncertain in the paper, organized to guide future research and benchmark design.
- External validity of labor mapping:
- Validate sensitivity to alternative occupational taxonomies (e.g., ESCO, ISCO) and non‑U.S. labor markets; quantify how conclusions change under different taxonomies and country contexts.
- Skill importance and “effective employment” assumptions:
- Assess robustness of using O*NET skill importance weights to estimate skill-level employment and capital; compare against alternative proxies (task time shares, task logs, value-added data).
- Capital proxy limitations:
- Replace/augment “capital” as salary × employment with sector-level value added, profitability, or productivity impact; test whether benchmark alignment changes.
- Digital vs. physical work estimates:
- Replace LLM-based DIGITAL/PHYSICAL labeling with multi-annotator human labels and/or empirical logs; report inter-annotator agreement and sensitivity of digitization ratios.
- LLM-based task-to-taxonomy mapping reliability:
- Expand beyond the small manual check (n=90) to a larger, stratified gold standard across domains; compute precision/recall per domain/skill and calibrate confidence scores for downstream use.
- Mapping ambiguity and multi-label inflation:
- Quantify and correct for over-assignment of domains/skills by LLMs (extraneous paths); develop de-duplication or sparsity-inducing constraints to avoid inflated coverage.
- Coverage metric design:
- Move from “unique path coverage” to weighted coverage that accounts for employment and capital distribution; provide confidence intervals and significance tests for coverage gaps.
- Sampling bias in coverage-aware subsampling:
- Evaluate whether the Δ=0.1 stopping criterion omits rare but economically important categories; conduct sensitivity analyses across Δ settings and sampling orders.
- Benchmark selection bias:
- Audit inclusion/exclusion criteria and overlap between benchmarks; quantify how certain popular, synthetic-heavy benchmarks (e.g., coding) skew aggregate conclusions.
- Representativeness vs. relevance:
- Verify whether mapped tasks reflect actual on-the-job action sequences (use execution traces/user logs) rather than just instruction text; measure divergence between instruction-level and trace-level mappings.
- Skill taxonomy adequacy:
- Test whether the chosen Work Activities/DWA taxonomy captures interpersonal and coordination-intensive skills with enough granularity; propose and validate extensions for “Interacting with Others.”
- Underrepresented domains design blueprint:
- Develop concrete task specifications, environments, and verifiable success metrics for Management, Legal, and other highly digitized but under-covered domains (e.g., contract drafting, compliance audits).
- Procedural complexity under-modeling:
- Incorporate coordinative and dynamic complexity (dependencies, uncertainty) into the complexity measure via dependency graphs, branching factors, and environment stochasticity; compare against current step-count proxy.
- Workflow induction validity:
- Perform large-scale human validation of induced workflows; ablate different induction models, segmentation thresholds, and hierarchies; report how autonomy estimates vary with the inducer.
- Success labeling for autonomy:
- Specify and standardize how step success/failure is determined across heterogeneous environments; quantify label noise and propagate uncertainty into autonomy curves.
- Autonomy threshold selection:
- Justify and standardize the success-rate threshold ; run sensitivity analyses across and provide confidence intervals or Bayesian credible intervals for autonomy estimates.
- Cross-benchmark comparability:
- Normalize differences in action spaces, reward shaping, and success definitions across benchmarks to avoid biased autonomy comparisons; propose a minimal logging schema and cross-benchmark evaluation protocol.
- Trajectory availability and reproducibility:
- Address limited access to agent trajectories; recommend mandatory release of traces and metadata (agent framework, LM version, prompts) to enable reproducible autonomy profiling.
- Agent framework and LM confounding:
- Run controlled experiments where multiple frameworks and LMs are evaluated on the same, standardized task sets to disentangle framework vs. backbone effects across complexity regimes.
- Interpersonal interaction and multi-party tasks:
- Create benchmarks and metrics for “Interacting with Others,” including multi‑party collaboration, negotiation, and coordination; define objective, auditable outcome metrics beyond text quality.
- Long-horizon verification:
- Develop scalable verification for ambiguous objectives and long-horizon dependencies in management/legal tasks (e.g., reference auditing, requirement traceability, policy compliance).
- Socioeconomic impact linkage:
- Test whether improved benchmark coverage/realism predicts productivity gains in field settings; run longitudinal or A/B deployment studies linking autonomy curves to task outcomes and oversight costs.
- Oversight and augmentation costs:
- Quantify human oversight time/effort at different autonomy levels; integrate oversight cost curves with autonomy curves to recommend automation vs. augmentation breakpoints.
- Temporal dynamics:
- Track how labor digitization and skill importance shift over time and re-run alignment analysis longitudinally; test whether benchmark portfolios keep pace with labor market changes.
- Uncertainty quantification:
- Propagate mapping, digitization, and success-label uncertainties through to final alignment metrics and autonomy curves; report error bars and perform robustness checks.
- Ethical and safety considerations:
- Identify risks unique to underrepresented high-impact domains (e.g., legal liability, managerial decision-making); design benchmarks with embedded safety checks and red-teaming protocols.
- Public artifacts and tools:
- Release the full mapping dataset, code, prompts, and taxonomy expansions used (including proprietary-LM substitutions) to enable independent replication and extension.
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and datasets introduced in the paper (LLM-based mapping to O*NET domains/skills, coverage-aware sampling, workflow induction for task complexity, and autonomy curves).
- Benchmark portfolio audit and gap analysis
- Sectors: software, academia (ML labs), benchmarking consortia
- What: Map existing agent benchmarks to O*NET domains/skills to quantify over/under-representation, reveal bias toward computer/mathematical work, and identify high-impact under-covered areas (e.g., management, legal).
- Tools/products/workflows: “WorkMap” dashboard that ingests benchmark task text, runs LLM mapping, and reports domain/skill coverage heatmaps; automated reports per benchmark suite.
- Assumptions/dependencies: Access to benchmark task instructions; LLM mapping accuracy; U.S.-centric O*NET taxonomy.
- Enterprise AI investment alignment and roadmap
- Sectors: enterprise operations, finance, legal, professional services
- What: Align internal AI projects with labor/economic value by mapping planned use cases to digitized, high-capital domains (e.g., legal operations, management reporting) highlighted as underrepresented.
- Tools/products/workflows: Portfolio planning workshop using coverage metrics; prioritization matrix by domain digitization and capital; quarterly rebalancing.
- Assumptions/dependencies: Reliable digitization estimates per domain; executive sponsorship; change management.
- Agent deployment runbooks using autonomy curves
- Sectors: software, back-office/CRM, knowledge work
- What: Use autonomy curves (success rate vs. task complexity) to set automation levels, decide when to use human-in-the-loop oversight, and define escalation criteria.
- Tools/products/workflows: “Autonomy Profiler” that analyzes agent logs, induces workflows, estimates max complexity at threshold ; runbook templates specifying approval gates and monitoring by complexity tier.
- Assumptions/dependencies: Access to agent trajectories; consistent success labeling; chosen threshold aligned with risk tolerance.
- Task decomposition assistants for reliable delegation
- Sectors: software engineering, data analysis, office productivity
- What: Decompose complex tasks into subtasks that fall within the agent’s validated autonomy level to improve reliability (e.g., break a coding task into implement-test steps).
- Tools/products/workflows: IDE or task manager plugins that propose decompositions based on autonomy curves and past success patterns; integration into agent frameworks (e.g., planners/orchestrators).
- Assumptions/dependencies: Quality of workflow induction; availability of historical execution data; prompt engineering for decomposition.
- Procurement and vendor evaluation checklists
- Sectors: enterprise IT, government procurement
- What: Require vendors to disclose domain/skill coverage and autonomy curves for representative tasks to inform buying decisions and SLAs.
- Tools/products/workflows: Standardized “Autonomy and Coverage Disclosure” appendix in RFPs; evaluation rubrics weighted by domain alignment and success at target .
- Assumptions/dependencies: Vendor willingness to share logs/metrics; common definitions of complexity and success.
- Workforce impact and reskilling planning
- Sectors: HR, policy, consulting
- What: Use “effective employment by skill” estimates to forecast which roles/skills are most exposed and plan reskilling to underrepresented, high-value skills (e.g., interpersonal coordination).
- Tools/products/workflows: Heatmaps of skill importance by role; reskilling pathway recommendations; training budgets tied to gaps.
- Assumptions/dependencies: O*NET relevance to local job mix; LLM-labeled digital/physical split validity.
- Benchmark design kit for researchers and product teams
- Sectors: academia, AI product teams
- What: Apply the paper’s three principles (coverage, realism/complexity, granular evaluation) to create or refine benchmarks.
- Tools/products/workflows: Templates for domain/skill sampling plans; coverage-aware sampling scripts; guidelines for collecting trajectories and inducing workflows for intermediate checks.
- Assumptions/dependencies: Annotator availability for realism; compute for LLM mapping; access to target-user tasks.
- Cost-efficient curation using coverage-aware sampling
- Sectors: data operations, evaluation teams
- What: Reduce labeling and evaluation cost for large, homogeneous benchmarks by stopping when marginal coverage gain falls below Δ.
- Tools/products/workflows: Open-source sampler integrated into evaluation pipelines; budget calculators.
- Assumptions/dependencies: Stable coverage estimates across permutations; task homogeneity detection.
- Product analytics for agent platforms
- Sectors: agent platforms, SaaS
- What: Instrument deployed agents to automatically report autonomy metrics by domain/skill and complexity, enabling customers to tune oversight.
- Tools/products/workflows: In-product analytics dashboards; anomaly detection when operating above validated autonomy.
- Assumptions/dependencies: Privacy-compliant logging; standardized workflow induction.
- Curriculum and training alignment for AI-in-the-workplace
- Sectors: education, corporate L&D
- What: Map course modules and training content to O*NET skills to cover underrepresented but prevalent skills (e.g., interacting with others) and teach effective delegation to agents using autonomy concepts.
- Tools/products/workflows: Syllabi planners; capstones that combine domain breadth with procedural complexity; simulation of human-in-the-loop workflows.
- Assumptions/dependencies: Faculty/coach adoption; up-to-date taxonomies; access to agent tools for practice.
- Everyday delegation heuristics for personal assistants
- Sectors: consumer productivity
- What: Give users simple rules-of-thumb: fully automate low-complexity tasks (e.g., file organization), request drafts or decompositions for medium complexity (e.g., trip planning), and require approval for high-stakes or multi-skill tasks (e.g., contract negotiation).
- Tools/products/workflows: Personal task managers that tag tasks with estimated complexity and recommend agent vs. human steps.
- Assumptions/dependencies: On-device estimation of task complexity; user consent for data use.
Long-Term Applications
These applications require further research, scaling, standardization, or sector-specific validation.
- Sector-specific benchmarks and pilots in underrepresented, digitized domains
- Sectors: legal (contracting, e-discovery), management (planning/reporting), architecture/engineering (design documentation)
- What: Build realistic, high-complexity benchmarks and pilot deployments in domains shown to be high-capital and digitized yet under-covered.
- Tools/products/workflows: “LegalOpsBench,” “MgmtBench” with human-authored tasks, embedded verification, and trajectories.
- Assumptions/dependencies: Access to proprietary workflows/data; privacy/compliance frameworks; expert-in-the-loop validation.
- Standardized autonomy grading and disclosures
- Sectors: regulators, industry standards bodies (e.g., NIST, ISO)
- What: Define a common “autonomy grade” (max validated complexity at threshold ) per domain/skill for agent systems; require disclosures in regulated contexts.
- Tools/products/workflows: Certification processes; conformance tests with public task banks; audit trails.
- Assumptions/dependencies: Agreement on complexity metrics; reproducible evaluations; governance capacity.
- Autonomy-aware orchestration in RPA and agent frameworks
- Sectors: enterprise software, RPA, DevOps
- What: Orchestrators that automatically decompose tasks, route subtasks to agents or humans based on autonomy curves, and adapt as performance shifts.
- Tools/products/workflows: Policy engines that encode escalation rules; learning systems that refine decomposition from outcomes.
- Assumptions/dependencies: Reliable, online estimation of task complexity; stable routing policies; latency/cost trade-offs.
- Training curricula for agents shaped by complexity profiles
- Sectors: AI model training, MLOps
- What: Construct training sets that target capability gaps by complexity tier and domain/skill; progressive curricula that move agents up the autonomy curve.
- Tools/products/workflows: Data generators grounded in realistic skill compositions; reinforcement curricula with intermediate checkpoints.
- Assumptions/dependencies: High-quality supervision at intermediate steps; avoidance of overfitting to benchmarks.
- Global, multi-jurisdictional work taxonomies
- Sectors: international organizations, labor economics
- What: Extend beyond U.S. O*NET to align with EU/Asia-Pacific occupational frameworks; harmonize skill/domain mappings and digitization estimates.
- Tools/products/workflows: Crosswalks between taxonomies; localization pipelines.
- Assumptions/dependencies: Data availability and quality; legal and linguistic adaptation.
- Real-time socioeconomic monitoring of AI-work alignment
- Sectors: economic policy, think tanks
- What: Dashboards tracking where AI development effort is concentrated vs. employment/capital distribution by domain/skill to guide R&D incentives and workforce policy.
- Tools/products/workflows: Periodic scans of papers/benchmarks; time-series alignment indicators; public reports.
- Assumptions/dependencies: Automated ingestion of research corpora; updated employment data; method robustness.
- Regulatory procurement and safety frameworks tied to autonomy
- Sectors: healthcare, finance, public sector
- What: Procurement rules that cap allowable autonomy levels for critical tasks, require human checkpoints at specified complexity, and mandate post-deployment monitoring.
- Tools/products/workflows: Policy templates; compliance tooling that enforces autonomy thresholds; audit APIs.
- Assumptions/dependencies: Sector-specific risk models; enforcement mechanisms; harmonization across agencies.
- Insurance and liability products for agent autonomy risk
- Sectors: insurance, legal
- What: Coverage priced by validated autonomy level and domain risk; discounts for granular evaluation and escalation controls.
- Tools/products/workflows: Actuarial models using autonomy metrics; policy endorsements tied to monitoring.
- Assumptions/dependencies: Loss data; causal links between autonomy and risk; standardized reporting.
- Benchmarks and agents for interpersonal and coordination skills
- Sectors: customer support, education, healthcare administration
- What: Create benchmarks that authentically require “interacting with others” skills (coordination, negotiation, empathy) and develop agents validated on them.
- Tools/products/workflows: Multi-party simulations with human evaluators; multimodal channels; outcome-based rubrics.
- Assumptions/dependencies: Safety and ethical safeguards; measurement of nuanced outcomes; data collection at scale.
- Compliance-grade logging and certification of autonomy profiles
- Sectors: regulated industries
- What: Standardized logging schemas and third-party certification to prove agents operated within approved autonomy levels for given tasks.
- Tools/products/workflows: Tamper-evident logs; verifiable workflow reconstructions; certification audits.
- Assumptions/dependencies: Interoperable schemas; secure infrastructure; clear liability boundaries.
- Agent-assisted management workflows
- Sectors: management/operations
- What: Autonomous agents handling portions of planning/reporting cycles (data gathering, draft synthesis), with human leadership reviewing high-complexity decisions.
- Tools/products/workflows: Quarterly business review pipelines that integrate autonomy-aware delegation; explainability views aligned to workflow steps.
- Assumptions/dependencies: High data quality; robust verification; cultural adoption.
Notes on Feasibility Assumptions and Dependencies
- LLM-based mappings and digital/physical labeling introduce error; periodic human validation is recommended.
- O*NET is U.S.-centric; portability to other labor markets requires taxonomy crosswalks and local data.
- Autonomy curves are only as reliable as the underlying trajectories and success labels; vendors should disclose logging methods and failure definitions.
- Success thresholds () and acceptable risk vary by sector; governance processes must set and revisit them.
- Privacy, security, and compliance constraints may limit access to real-world logs needed for workflow induction.
- Benchmarks with realistic complexity often require human annotation and domain expertise, increasing cost and time.
Glossary
- agent framework: The specific agent architecture or system used to execute tasks within benchmarks. "We analyze agent trajectories across benchmarks to depict their autonomy levels by domain, skills, agent framework, and backbone LMs, providing actionable guidance for selecting the appropriate autonomy level to interact with them"
- agentic: Describing systems that act in an environment via iterative perception and action cycles. "agentic, in that the system operates within an interactive environment (e.g., a web browser or desktop) and follows an observation-action loop during task execution;"
- autonomy: The degree to which an agent can perform tasks without human intervention. "Autonomy. The extent to which an agent system can complete a task by perceive its environment, make decisions, and take actions without direct human intervention."
- autonomy curves: Plots of agent success as a function of task complexity used to choose appropriate automation levels. "This example shows how autonomy curves translate abstract performance metrics into actionable decisions for human users."
- backbone LMs: The underlying LLMs that agent frameworks rely on for reasoning and action. "We analyze agent trajectories across benchmarks to depict their autonomy levels by domain, skills, agent framework, and backbone LMs"
- BLS: The U.S. Bureau of Labor Statistics, a source for employment and wage data used for aligning domains. "we obtain occupation employment and median salary data (latest update in 2024) from the U.S. Bureau of Labor Statistics (BLS)"
- capability boundary: The maximum complexity of tasks an agent can reliably complete under given performance criteria. "This definition characterizes agent autonomy as a capability boundary, capturing the most complex class of tasks the agent can complete end-to-end with acceptable reliability."
- component complexity: The part of task complexity determined by the number of distinct procedural steps. "task complexity can be decomposed into component complexity (the number of distinct steps involved), coordinative complexity (i.e., interdependence among task elements), and dynamic complexity (i.e., uncertainty or environmental change)."
- coordinative complexity: The interdependence among task elements that must be managed during execution. "task complexity can be decomposed into component complexity (the number of distinct steps involved), coordinative complexity (i.e., interdependence among task elements), and dynamic complexity (i.e., uncertainty or environmental change)."
- coverage: The proportion of unique taxonomy paths in domains or skills that are represented by benchmark tasks. "We define coverage of a set of examples on a taxonomy as the percentage of unique paths being covered in the taxonomy tree"
- coverage-aware sampling: A sampling strategy that selects tasks to preserve a benchmark’s coverage across taxonomies. "We validate the robustness of our coverage-aware sampling via permutation tests, showing stable stopping size and domain/skill coverage across resampled task orderings"
- coverage-guaranteed sampling: A procedure that continues sampling until coverage growth falls below a threshold. "we develop a coverage-guaranteed sampling strategy that continues to sample new batches of examples (of size 5) until coverage increases slower than ."
- cross-indexing: Associating tasks with both domain and skill taxonomies to obtain complementary perspectives. "By cross-indexing tasks to these two taxonomies, we can obtain complementary views to associate them with work: domains reflect job-specific contexts, while skills capture processes that generalize across jobs."
- Detailed Work Activities: Fine-grained O*NET descriptors of specific work actions used to extend the skill taxonomy. "We further expand the taxonomy with O*NET's Detailed Work Activities."
- effective capital: A skill-weighted measure of total earnings associated with tasks requiring a given skill. "Effective capital is defined as "
- effective employment: Employment aggregated across occupations weighted by the importance of a given skill. "Reported effective employment "
- granular evaluation: Assessment approaches that incorporate intermediate steps or checkpoints rather than only end-task outcomes. "we propose three measurable benchmark design principles---domain and skill coverage, task realism and complexity, and granular evaluation---"
- hierarchical workflow: A multi-level structure of goal-directed steps induced from action trajectories to represent tasks. "which segments any agent trajectory with low-level actions (e.g., click) into a hierarchical workflow with goal-directed steps at increasing levels of granularity"
- leaf-level node: The most fine-grained category in a taxonomy path used for precise task-to-skill/domain mapping. "where returns a root-to-leaf path in the skill taxonomy and extracts its leaf-level node"
- LM-driven mapping: Using a LLM to assign tasks to taxonomy paths for domains and skills. "To examine the reliability of the LM-driven mapping process, we conduct a manual validation study"
- long-horizon dependencies: Task relationships that span many steps, making objectives and verification challenging. "These domains are not only central to organizational decision-making and economic coordination, but also pose distinct technical challenges, such as ambiguous objectives and verification with long-horizon dependencies."
- modality-agnostic: Not specific to digital or physical modes of work, allowing broad skill coverage. "we find many O*NET skill categories are modality-agnostic;"
- O*NET: A U.S. government database cataloging occupations and work activities used to build domain and skill taxonomies. "we map individual benchmark examples to domains and skills using occupational taxonomies derived from the O*NET database"
- observation-action loop: The iterative process by which agents perceive the environment and act in it. "and follows an observation-action loop during task execution;"
- permutation tests: Statistical checks using random re-orderings to validate the robustness of sampling strategies. "We validate the robustness of our coverage-aware sampling via permutation tests, showing stable stopping size and domain/skill coverage across resampled task orderings"
- root-to-leaf path: A full sequence from the taxonomy root to a granular category used to represent task coverage. "where returns a root-to-leaf path in the skill taxonomy and extracts its leaf-level node"
- SOC codes: Standard Occupational Classification identifiers used to align occupations with employment and wage data. "we directly align each leaf occupation in our domain taxonomy with its corresponding employment and wage statistics via shared SOC codes."
- success rate threshold: The minimum success probability used to define an agent’s autonomy level. "Operationally, we quantify agent autonomy as the maximum task complexity that an agent can complete end-to-end above a predefined success rate threshold with statistical confidence."
- Work Activities (WA) taxonomy: An O*NET hierarchy of activities used as the basis for constructing the skill taxonomy. "We construct the skill taxonomy starting from O*NET's Work Activities (WA) taxonomy"
- workflow induction: The process of extracting structured task steps from low-level action traces. "we adopt the workflow induction procedure from \citet{wang2025ai}, which segments any agent trajectory with low-level actions (e.g., click) into a hierarchical workflow "
Collections
Sign up for free to add this paper to one or more collections.