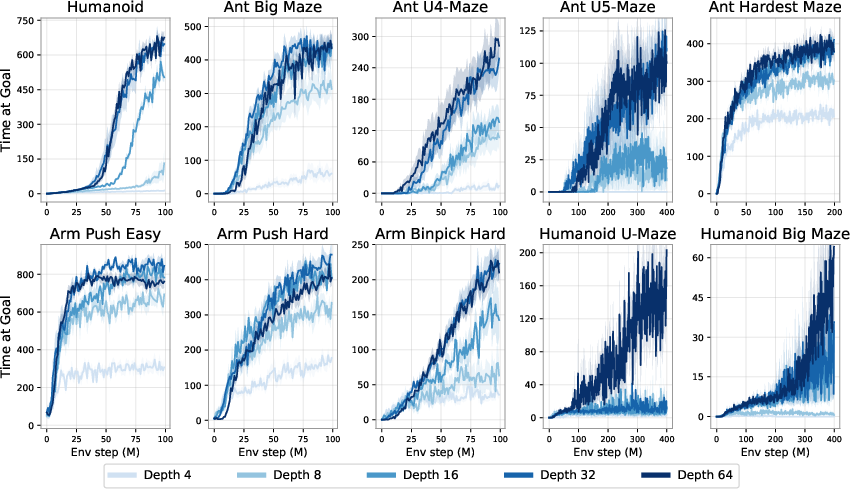
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Abstract: Scaling up self-supervised learning has driven breakthroughs in language and vision, yet comparable progress has remained elusive in reinforcement learning (RL). In this paper, we study building blocks for self-supervised RL that unlock substantial improvements in scalability, with network depth serving as a critical factor. Whereas most RL papers in recent years have relied on shallow architectures (around 2 - 5 layers), we demonstrate that increasing the depth up to 1024 layers can significantly boost performance. Our experiments are conducted in an unsupervised goal-conditioned setting, where no demonstrations or rewards are provided, so an agent must explore (from scratch) and learn how to maximize the likelihood of reaching commanded goals. Evaluated on simulated locomotion and manipulation tasks, our approach increases performance on the self-supervised contrastive RL algorithm by $2\times$ - $50\times$, outperforming other goal-conditioned baselines. Increasing the model depth not only increases success rates but also qualitatively changes the behaviors learned. The project webpage and code can be found here: https://wang-kevin3290.github.io/scaling-crl/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces deep residual MLPs (up to 1024 layers) for self-supervised goal-conditioned RL via Contrastive RL (CRL) and reports large empirical gains. The following points identify what remains missing, uncertain, or unexplored, framed to be concrete and actionable for future work:
- Real-world validation is absent: results are limited to simulated Brax/MJX tasks; sim-to-real transfer, deployment latency, and hardware constraints on onboard inference are untested.
- Pixel-based observation settings are not evaluated: all tasks use state inputs; it’s unclear if depth scaling yields similar gains with high-dimensional visual inputs and data augmentation.
- Scope is narrow to continuous control and single-agent tasks: discrete action spaces, multi-agent settings, partial observability, and recurrent architectures remain unexplored.
- No iso-compute/iso-parameter comparisons: improvements are reported across varying parameter counts and compute; controlled experiments under fixed FLOPs, fixed memory, or matched parameter budgets are needed to attribute gains to depth per se.
- Compute accounting is inconsistent: the paper asserts parameter count “scales linearly with width but quadratically with depth,” which is not generally true for MLPs; a rigorous, reproducible compute/parameter accounting framework is missing.
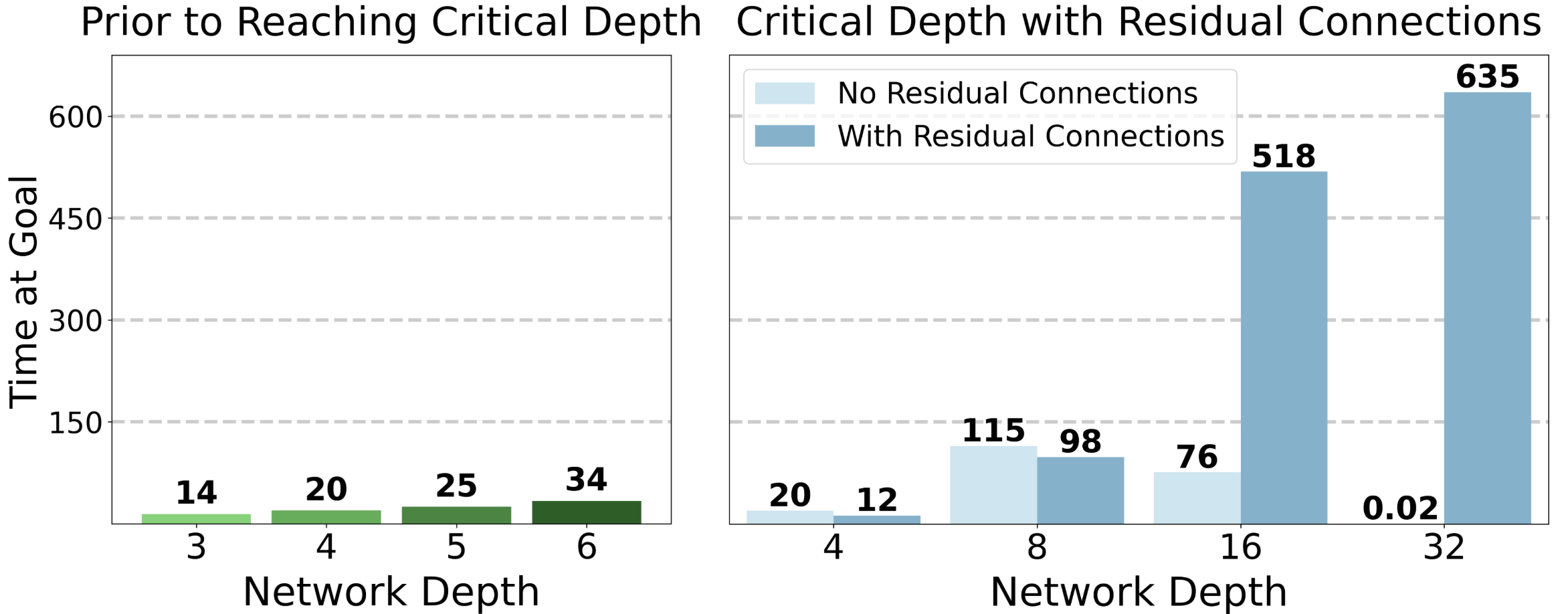
- Lack of formal scaling laws or theory: “critical depth” phenomena are observed but not explained; there is no predictive model linking environment properties (e.g., horizon, topology, observation dimension) to required depth.
- Stability at extreme depth is unresolved: actor loss explosions at 1024 layers are noted; systematic stabilization strategies (e.g., pre-/post-LN, DeepNorm, skip-init, spectral norm constraints, gradient clipping, reversible layers) are not evaluated.
- Offline CRL scaling underperforms: the method yields little benefit on OGBench; it is unclear whether data coverage, behavior mismatch, cold-start tuning, or loss design (e.g., temperature, margins) blocks scaling offline.
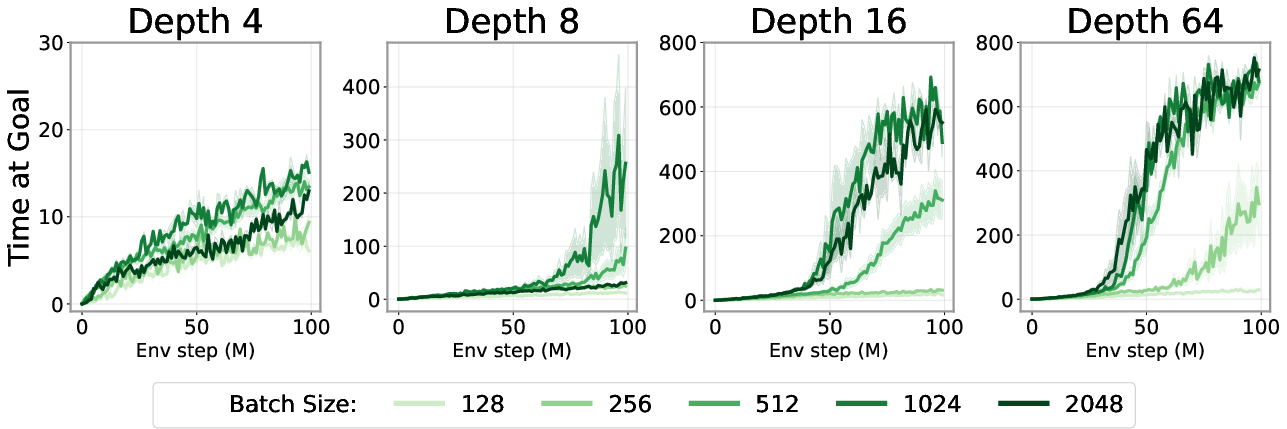
- Batch-size scaling is only partially characterized: larger batches help with deeper nets, but principled LR scaling rules, optimizer choices (momentum, weight decay), gradient-noise-scale measurements, and replay ratio interactions are not studied.
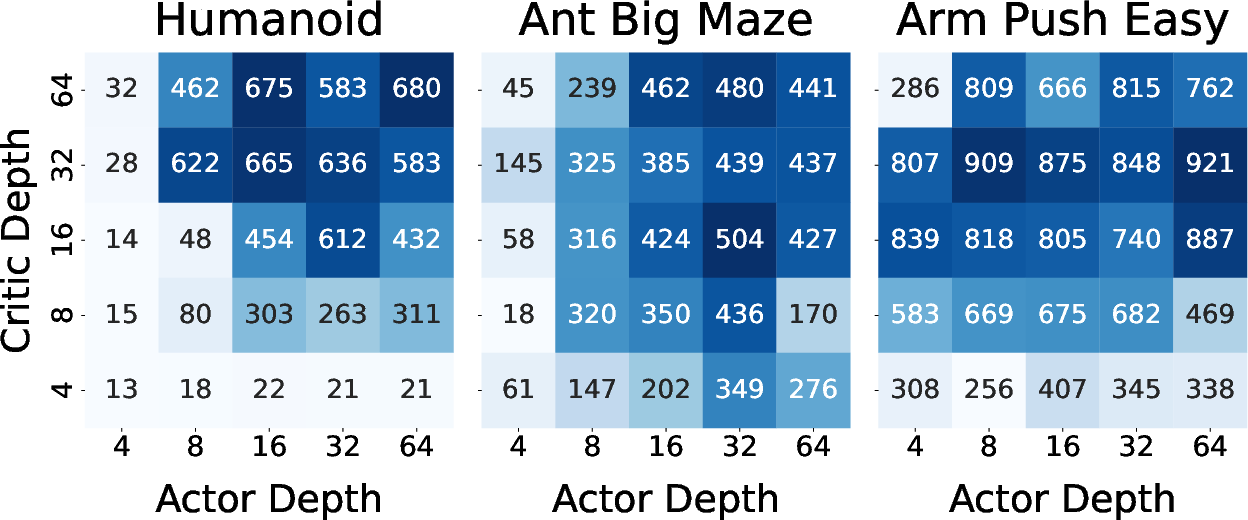
- Actor vs. critic scaling guidance is missing: environment-dependent effects are observed; there are no diagnostics or heuristics to decide how to allocate depth between actor and critic given task properties.
- Exploration coverage is not quantified: “synergy” between exploration and expressivity is argued via the collector experiment, but formal coverage metrics (e.g., state visitation entropy, occupancy, novelty) are absent.
- Contrastive training hyperparameters are under-specified: the number of negatives K, temperature/margin, hard-negative mining, and sampling policies are not systematically varied or analyzed for deep CRL.
- Goal sampling and curricula are not explored: how different goal distributions, adaptive curricula, or subgoal selection affect scaling and emergence is unknown.
- Architectural generality is untested: only residual MLPs are used; depth scaling with transformers, Mixture-of-Experts, reversible layers, gated MLPs, or quasimetric encoders (beyond appendix mentions) remains open.
- Normalization and block design choices are not ablated: residual block size, pre- vs. post-LN, activation functions (e.g., GELU vs. Swish), skip-initialization, and position of residual adds could materially impact very deep training.
- Replay buffer design is not analyzed: prioritized replay, replay ratios, temporal sampling windows for positives, and dataset deduplication with deep CRL are unexamined.
- Evaluation metric may bias behavior: “number of timesteps near the goal” over 1000 steps could be gamed by staying at the goal; episode-level success rates, success-on-first-arrival, path optimality, and sample efficiency metrics should be added.
- Statistical robustness is unclear: number of seeds, variance, confidence intervals, and sensitivity to hyperparameters are not reported; claims of “critical depth” need statistical backing across seeds/runs.
- Representational analysis is qualitative: Q-visualizations and PCA plots suggest richer topology, but quantitative measures (e.g., topology-preserving metrics, mutual information, cluster separability, CKA/CKN similarity) are needed to link depth to representation quality.
- Generalization via stitching is tested narrowly: only Ant U-Maze with constrained train pairs; broader, systematic evaluation across tasks, environment variations, and long-range compositionality is missing.
- Interaction with extrinsic rewards remains unexplored: CRL is self-supervised; combining depth-scaled CRL with shaped rewards or hybrid RL (e.g., contrastive pretraining + TD finetuning) could bridge early sample-efficiency gaps observed vs. SAC.
- Early sample efficiency is inferior to SAC in Humanoid mazes: mechanisms to improve CRL’s cold-start (e.g., behavioral priors, exploration bonuses, subgoal discovery) are not investigated.
- Width scaling limits are not thoroughly mapped: width is explored up to 2048; deeper analyses of width–depth trade-offs under fixed compute, and Pareto fronts across tasks, are needed.
- Safety and robustness are unaddressed: sensitivity to perturbations, domain shift, actuator noise, and adversarial or out-of-distribution goals remain open.
- Hyperparameter sensitivity for deep nets is not specified: learning rate schedules, weight decay, initialization schemes, and regularization (dropout, stochastic depth) could be critical at 1000+ layers.
- Planning vs. function approximation: depth may emulate planning in mazes; comparisons to model-based RL, hierarchical RL (options/subgoals), or search-based approaches would clarify what depth is substituting for.
- Goal-space design choices are not analyzed: the mapping f: S → G may induce aliasing; alternative goal parameterizations (relative positions, learned embeddings) could affect scaling and emergence.
- Embedding-norm control is absent: the actor maximizes L2 distance in embedding space; without norm constraints or temperatures, degenerate behavior and loss explosions can occur; margin-based or normalized objectives should be explored.
- Distillation/pruning/compression are proposed but not tested: practical recipes to compress deep CRL policies/critics for deployment (and their impact on performance and emergence) are open.
- Cross-task transfer is untested: whether deep CRL learns reusable goal-conditioned representations that transfer across environments or tasks is unknown.
Collections
Sign up for free to add this paper to one or more collections.