- The paper introduces AfroXLMR-Social by adapting AfroXLMR with domain adaptive pre-training (DAPT) and task adaptive pre-training (TAPT) for social media text.
- It demonstrates significant Macro F1 improvements in sentiment (1%-30%), emotion (0.55%-15.11%), and hate speech tasks using a curated AfriSocial corpus.
- The study underscores the importance of localized, culturally specific data in enhancing NLP applications for underrepresented African languages.
AfroXLMR-Social: Adapting Pre-trained LLMs for African Languages Social Media Text
Introduction
The paper "AfroXLMR-Social: Adapting Pre-trained LLMs for African Languages Social Media Text" (2503.18247) investigates the adaptation of pre-trained LLMs (PLMs) for African languages within the social media domain. While PLMs like BERT and XLM-RoBERTa have achieved substantial success across a variety of NLP tasks, their initial training corpora often lack sufficient domain-specific content pertinent to African languages. This paper addresses this gap by introducing AfroXLMR-Social through domain adaptive pre-training (DAPT) and task adaptive pre-training (TAPT), leveraging a curated social media and news corpus named AfriSocial.
Methodology
This study employs continual pre-training strategies on the AfroXLMR model, which is originally based on XLM-RoBERTa and tailored for African languages. The adaptation process involves:
- Domain Adaptive Pre-training (DAPT): This phase involves using the AfriSocial corpus—comprising social media text and news articles—to enhance the domain relevance of the model. Here, a general-purpose LLM is continually pre-trained on domain-specific unlabeled text to improve performance in social contexts.
- Task Adaptive Pre-training (TAPT): In this phase, the model undergoes further training on task-specific data without labels. TAPT is aimed at improving task performance by pre-training the model on the same type of data it will later be fine-tuned on.
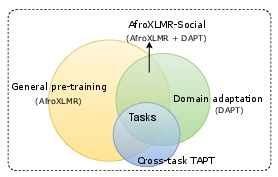
Figure 1: Continual pre-training illustration. A general-purpose pretrained model, such as AfroXLMR, is first adapted to a social domain, resulting in AfroXLMR-Social.
The evaluation focuses on three subjective NLP tasks: sentiment analysis, emotion analysis, and hate speech classification, covering 19 African languages. Each task benefits differently from the adaptation techniques applied, with combined DAPT and TAPT approaches showing noticeably improved accuracy.
Results and Analysis
AfroXLMR-Social's performance on the evaluation tasks demonstrates the effectiveness of tailoring pre-trained models via domain-specific continual pre-training. The study reports significant improvements in Macro F1 scores:
- Sentiment Analysis (AfriSenti): DAPT yields F1 score improvements between 1% to 30%. TAPT further refines these gains with cross-task adaptability enhancing sentiment analysis accuracy.
- Emotion Analysis (AfriEmo): Utilizing DAPT coupled with TAPT on sentiment data improves emotion analysis by 0.55% to 15.11% in Macro F1 score. It shows that task relevance is crucial for performance enhancement.
- Hate Speech Detection (AfriHate): Fine-tuning leveraging DAPT and TAPT results in better classification precision, essentially due to improved contextual understanding from domain and task adaptation.
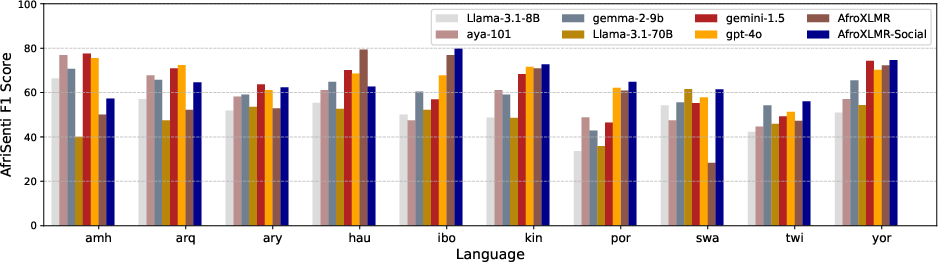
Figure 2: AfriSenti Macro F1 results from AfroXLMR-Social and LLMs.
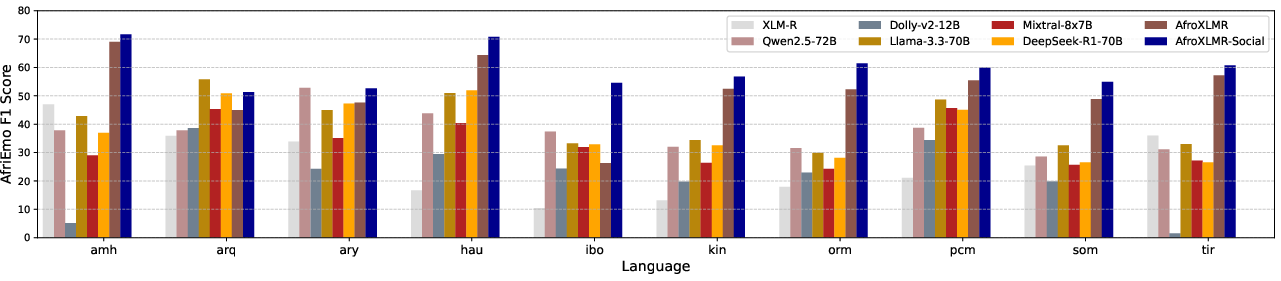
Figure 3: AfriEmo Macro F1 results from AfroXLMR-Social and LLMs.
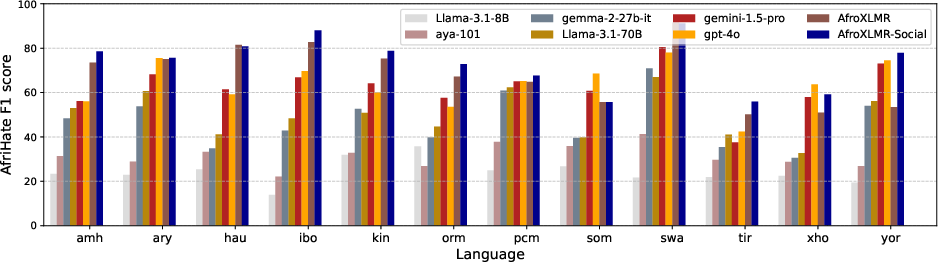
Figure 4: AfriHate Macro F1 results from AfroXLMR-Social and LLMs.
Implications and Future Directions
The AfroXLMR-Social framework highlights the necessity of domain-specific adaptation in PLMs, especially for languages with limited resources. Practically, this approach facilitates the development of more accurate and culturally sensitive NLP applications for African languages, which are often underrepresented in mainstream NLP resources.
Looking forward, these findings suggest several avenues for further research:
- Broader Domain Exploration: Beyond social media, other domains could further benefit from similar adaptive pre-training methodologies, introducing more linguistic diversity into PLMs.
- Extensive Cross-task Evaluation: Future studies could probe deeper into cross-task adaptability impacts across various domains and tasks, refining the balance between computational expense and performance gain.
- Large-scale LLM Integration: The integration of such adaptation techniques with large-scale LLMs could potentially close performance gaps between LLMs and domain-specific fine-tuned models.
Conclusion
AfroXLMR-Social successfully demonstrates the value of domain and task adaptive pre-training for enhancing PLM efficacy in African languages. This research underscores the critical role of localized, domain-specific data in achieving robust performance across linguistically diverse and culturally specific contexts. The open distribution of AfriSocial corpus and AfroXLMR-Social models marks a significant contribution to the NLP community, optimizing LLMs for a broader spectrum of languages and dialects.