- The paper demonstrates that incorporating domain-adaptive pretraining (DAPT) and task-adaptive pretraining (TAPT) leads to substantial performance enhancements in various classification tasks.
- Experiments across biomedical, computer science, news, and review domains reveal that combined adaptive methods outperform standard pretraining approaches, especially in low-resource settings.
- Key findings include the effective use of tailored data selection techniques, such as VAMPIRE, to optimize model accuracy and establish superior benchmarks for domain-specific NLP.
Summary of "Don't Stop Pretraining: Adapt LLMs to Domains and Tasks"
Introduction
LLMs like RoBERTa receive robust performance by pretraining on extensive and diverse corpora. Despite their success, this paper scrutinizes the importance of further adapting these models to the specific domains or tasks of interest. Introducing domain-adaptive pretraining (DAPT) and task-adaptive pretraining (TAPT), the paper demonstrates the substantial benefits offered by a continued pretraining process tailored to particular domains and tasks across low- and high-resource settings.
Methodology
The experiments conducted focus on four distinct domains (biomedical publications, computer science papers, news articles, and reviews) and encompass eight classification tasks. The paper evaluates the impact of a secondary pretraining phase aimed at leveraging in-domain data (DAPT) and task-specific unlabeled data (TAPT). Hybrid approaches combining both adaptive strategies are also examined. Required unlabeled datasets are selected strategically, harnessing the VAMPIRE model to identify task-relevant data.

Figure 1: An illustration of data distributions. Task data is comprised of an observable task distribution, usually non-randomly sampled from a wider distribution (light grey ellipsis) within an even larger target domain.
Experimental Results
Domain-Adaptive Pretraining
Results show that DAPT effectively enhances model performance across the board, especially in low-resource contexts. In the biomedical domain, BioMed-RoBERTa demonstrates improved masked LM loss, indicating enhanced language understanding following continued domain-specific pretraining.
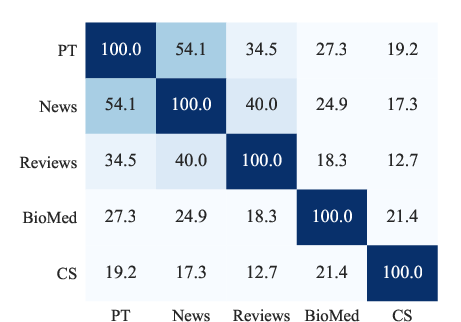
Figure 2: Vocabulary overlap (\%) between domains, showing PT denotes RoBERTa's pretraining corpus sample.
Task-Adaptive Pretraining
TAPT equally showcased performance boosts, outperforming DAPT in specific instances like RCT. It demonstrates the efficacy of task-specific corpus adaptation even further refined by human-curated datasets or data selection techniques.
Combined Adaptive Pretraining
The combined DAPT + TAPT approach yielded the best results, underlining the importance of domain and task fusion in extended pretraining. This strategy effectively balances computational demands with improvements in classification accuracy.
Domain Overlap and Transferability
The exploration of domain boundaries signifies a tangible overlap, suggesting the potential utility in cross-domain transferability for certain tasks. Still, the quintessential benefit of domain relevance perseveres, with controlled DAPT experiments firmly corroborating this stance.
Implications and Future Work
The investigation substantiates that large pre-trained LLMs do not universally grasp the complexity across all domains and tasks. Consequently, adaptive pretraining methodologies promise significant performance augmentation, advocating specialized models tailored through human-curated or algorithmically selected datasets for efficient application. Future research should explore more sophisticated data selection techniques and optimized curricula for adaptive training to bolster cross-domain versatility.
Conclusion
The paper provides substantial evidence affirming the merits of domain- and task-specific adaptive pretraining for markedly improving NLP task performance. It encourages the prioritization of targeted data adaptation strategies in future LLM frameworks to augment both domain-specific competence and task-focused efficacy. Adopting these approaches could establish new benchmarks and elevate interpretative capabilities within specialized NLP applications.