- The paper introduces MDAPT, a novel approach that adapts pretrained multilingual models to domain-specific tasks using a mix of general and specialized texts.
- It employs both adapter-based training and full pretraining methods to enhance performance on tasks like NER and sentence classification across multiple languages.
- Experimental results show superior performance in biomedical and financial domains, particularly in English, Spanish, and German, underscoring its practical value.
Multilingual Domain Adaptive Pretraining: Insights from MDAPT
Introduction
The paper "MDAPT: Multilingual Domain Adaptive Pretraining in a Single Model" (2109.06605) addresses the challenge of developing a LLM that is both domain-specific and multilingual in nature. This research explores the benefits of pretraining a single, multilingual model that can serve multiple languages within a domain, such as finance and biomedical sectors, effectively handling the scarcity of domain-specific corpora in various languages. The focus is on preventing the model from forgetting how to represent different languages, even as it adapts to specific domains.
Methodology
The proposed method, known as Multilingual Domain Adaptive Pretraining (MDAPT), extends traditional domain adaptive pretraining to a multilingual framework. MDAPT starts with a pretrained multilingual model like mBERT or XLM-R and further pretrains it on a mix of domain-specific and general multilingual texts. This combination aims to maintain the model's multilingual capabilities while focusing on the domain-specific adaptations.
The corpus used for pretraining includes:
- English Domain-Specific (ED): Includes domain-specific English text.
- Multilingual Domain-Specific (Mp): Contains domain-specific text in multiple languages.
- Multilingual General (MWIKI): General text from Wikipedia.
MDAPT incorporates both adapter-based training and full model pretraining approaches to improve domain-specific performance.
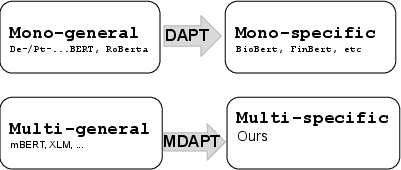
Figure 1: mDAPT extends domain adaptive pretraining to a multilingual scenario.
Experiments and Results
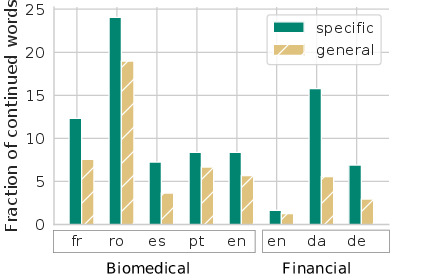
The experiments conducted evaluated the MDAPT model across seven languages and two primary domains: biomedical and financial. The downstream tasks included Named Entity Recognition (NER) and sentence classification. The findings indicated that multilingual domain adaptive pretraining can lead to competitive performance relative to monolingual domain-specific models and can outperform general multilingual models in several cases.
MDAPT models demonstrated superior performance, particularly in Spanish and English biomedical NER tasks and German financial classification tasks, showcasing the proficiency of the models in cross-lingual domain-specific representations.
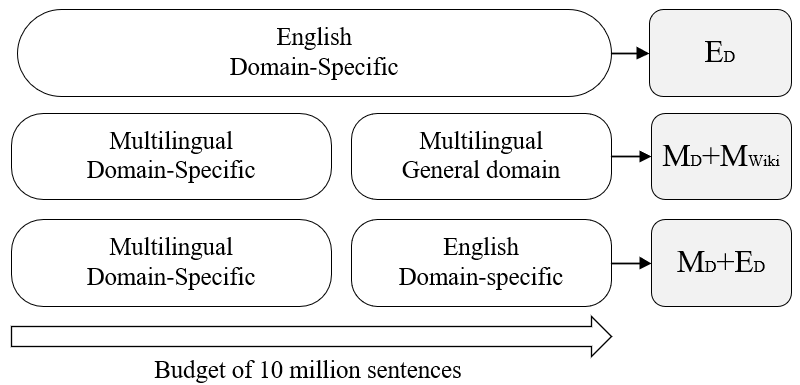
Figure 2: Composition of pretraining data.
Analysis
A critical analysis of the MDAPT approach revealed several insights:
Implications and Future Work
The implications of this study are significant for the deployment of domain-specific multilingual models, particularly in environments where resources are limited, and multiple languages need to be supported simultaneously. Future research directions could focus on further improving tokenizer performance or exploring alternative adaptive pretraining methods to bridge the remaining gap between multilingual and monolingual domain-specific model performances.
Conclusion
Overall, the "MDAPT: Multilingual Domain Adaptive Pretraining in a Single Model" paper demonstrates the feasibility and effectiveness of adapting a LLM to be both domain-specific and multilingual. The results underscore the potential benefit of employing MDAPT models in practical scenarios where resource constraints and multi-language support are critical factors.