- The paper introduces xKV, a cross-layer SVD method that compresses KV caches, achieving up to 6.8× higher compression and a 2.7% accuracy improvement over prior techniques.
- xKV employs horizontal concatenation to extract shared singular vectors across layers, enabling plug-and-play integration with pre-trained models without additional fine-tuning.
- Experimental results on benchmarks like RULER and DeepSeek-Coder-V2 validate xKV's effectiveness for efficient LLM deployment in resource-constrained environments.
xKV: Cross-Layer SVD for KV-Cache Compression
Introduction
The proliferation of LLMs necessitates efficient solutions to their inherent computational and memory challenges, exacerbated by long-context inference demands. One particular bottleneck is the management of Key-Value (KV) caches, which grow substantially with increased context lengths. Prior techniques focused on intra-layer redundancies, failing to exploit potential cross-layer similarities effectively. The study introduces xKV, a cross-layer Singular Value Decomposition (SVD) method designed to compress KV caches by identifying shared singular vectors across multiple layers, reducing memory requirements, and maintaining high accuracy.
Methodology
xKV applies SVD collective compression by revisiting cross-layer redundancies in KV caches and does not hinge on inter-token cosine similarities, previously assumed critical by methods such as MiniCache. Instead, xKV identifies high coordination among dominant singular vectors across layers, leveraging this structural property to achieve significant memory optimization without expensive pretraining.
The core strategy involves horizontal concatenation followed by a cross-layer SVD to extract shared principal components of grouped layers' caches, reshaping them into a compact representation. This approach facilitates deploying xKV without architectural changes or fine-tuning, ideal for existing pre-trained models.
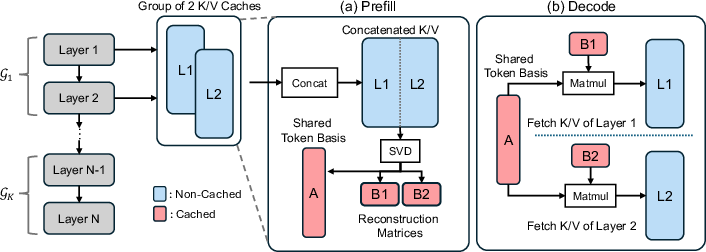
Figure 1: Illustration of the xKV for compressing KV-Cache.
Experimental Setup and Results
RULER Benchmark
xKV was evaluated using the RULER benchmark with prominent models like Llama-3.1 and Qwen2.5, demonstrating up to 6.8× higher compression rates compared to state-of-the-art techniques, with a 2.7% accuracy improvement. The versatility of xKV extends to models employing Multi-Head Latent Attention, achieving notable compression without performance drops. When tested across various compression rates, xKV consistently outperformed baselines, notably maintaining performance at extreme compression settings.
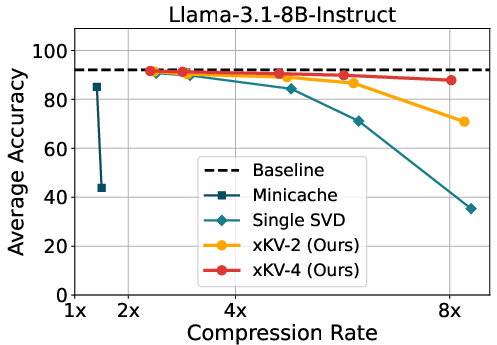
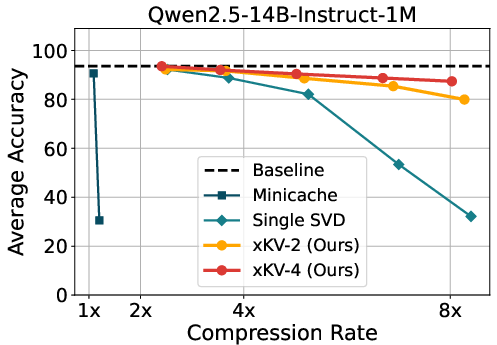
Figure 2: Accuracy comparison of MiniCache, applying SVD on single layer's KV-Cache and xKV on Llama-3.1-8B-Instruct and Qwen2.5-14B-Instruct-1M.
Compatibility with Emerging Architectures
Evaluating xKV within the DeepSeek-Coder-V2 framework, which already employs efficient KV cache practices, further demonstrated its robustness. Here, xKV achieved substantial compression efficiency without degrading code completion tasks on RepoBench-P and LCC datasets.
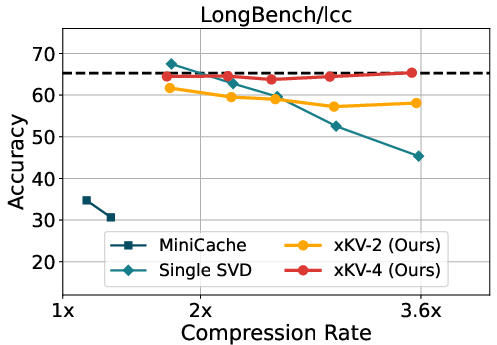
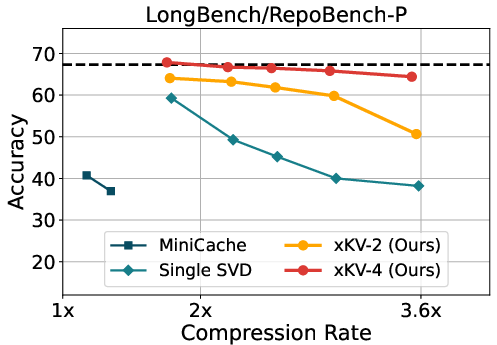
Figure 3: Evaluation results of different KV-Cache methods on DeepSeek-Coder-V2-Lite-Instruct model using RepoBench-P and LCC.
Theory and Analysis
Singular Vector Alignment
A detailed analysis utilizing Centered Kernel Alignment (CKA) revealed that, despite limited token-wise similarity across layers, the singular vectors are remarkably well-aligned. This supports the efficacy of xKV’s strategy in forming shared low-rank subspaces for multiple layers.
Eigenvalue Insights
Empirical studies further highlighted that horizontally concatenated caches necessitate lower ranks to retain principal eigenvalues, suggesting superior compression capability when considered across multiple layers.
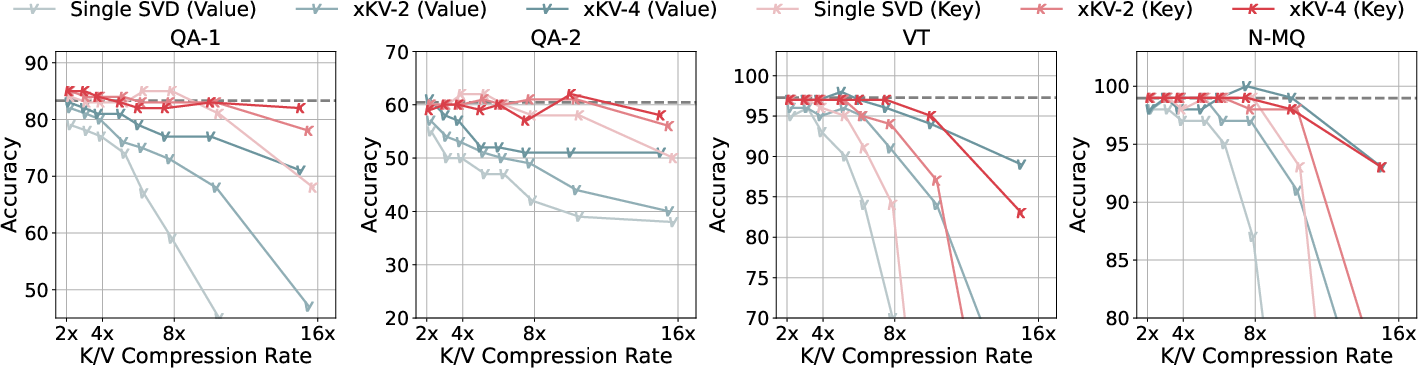
Figure 4: Accuracy comparison of applying different methods to key and value separately on Llama-3.1-8B-Instruct using RULER benchmark.
Implications and Future Work
The effectiveness of xKV suggests promising approaches for deploying LLMs in resource-constrained environments. Future directions may explore adaptive rank allocation per layer group, refine methods for context-aware compression, and integrate xKV into comprehensive systems for real-time throughput and decoding speed analyses.
Conclusion
The xKV method presents a compelling approach to KV cache compression by harnessing cross-layer redundancies with Singular Value Decomposition. Its plug-and-play nature, combined with robust empirical performance, positions it as a viable solution to the memory challenges faced in deploying large-context LLMs. As industries increasingly rely on long-context models for substantial real-time applications, xKV offers a pathway to substantial efficiency gains without compromising accuracy.