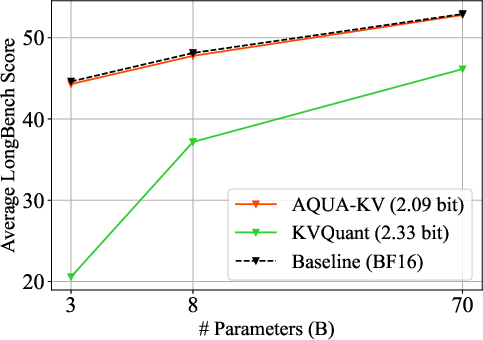
- The paper presents AQUA-KV, an adaptive quantization technique that leverages inter-layer dependencies to efficiently compress KV caches in LLMs.
- The methodology utilizes compact linear predictors and a one-shot calibration technique, achieving compression at 2-2.5 bits per value with under 1% perplexity error.
- Experimental results on LongBench benchmarks demonstrate that AQUA-KV outperforms conventional methods by maintaining task performance with a reduced memory footprint.
Key-Value Cache Compression for LLMs: AQUA-KV Approach
Introduction
Efficient deployment of LLMs like Llama 3.x necessitates the management of extensive Key-Value (KV) caches integral for attention mechanisms. These caches can quickly escalate in size, often becoming the bottleneck in both memory usage and computational efficiency, especially when dealing with long sequences. Current literature suggests quantization as a solution for KV cache compression; however, conventional methods often sacrifice accuracy for increased compression ratios.
Method Summary
The "Cache Me If You Must: Adaptive Key-Value Quantization for LLMs" paper introduces AQUA-KV, a novel adaptive quantization method for KV caches. Unlike traditional quantization methods that treat different layers independently, AQUA-KV exploits inter-layer dependencies to compress KV caches more effectively. Specifically, this method uses compact linear predictors that bridge the cached representations of subsequent layers, maintaining high accuracy while achieving substantial compression.
AQUA-KV Algorithm
AQUA-KV employs a one-shot calibration technique that adapts lightweight predictors between convolution layers based on the intrinsic dependencies between KV representations.
- Layer Interaction: Predictive linear models are trained to learn relationships between KV representations from different layers and tokens.
- Quantization Process: These predictors are then used to resolve the content of KV representations before applying lossy quantization, which compresses the residuals not captured by the predictors.
- Implementation Efficiency: The calibration of AQUA-KV is performed using a straightforward pass through typical GPU setups and supports various quantization schemes, such as the well-regarded HIGGS and Quanto methods. The paper's approach to quantization is notable for maintaining under 1% relative error in perplexity across diverse LLM tasks while operating at 2-2.5 bits per value.
Experimental Results
AQUA-KV demonstrates significant improvements over existing KV cache compression methodologies across several key metrics:
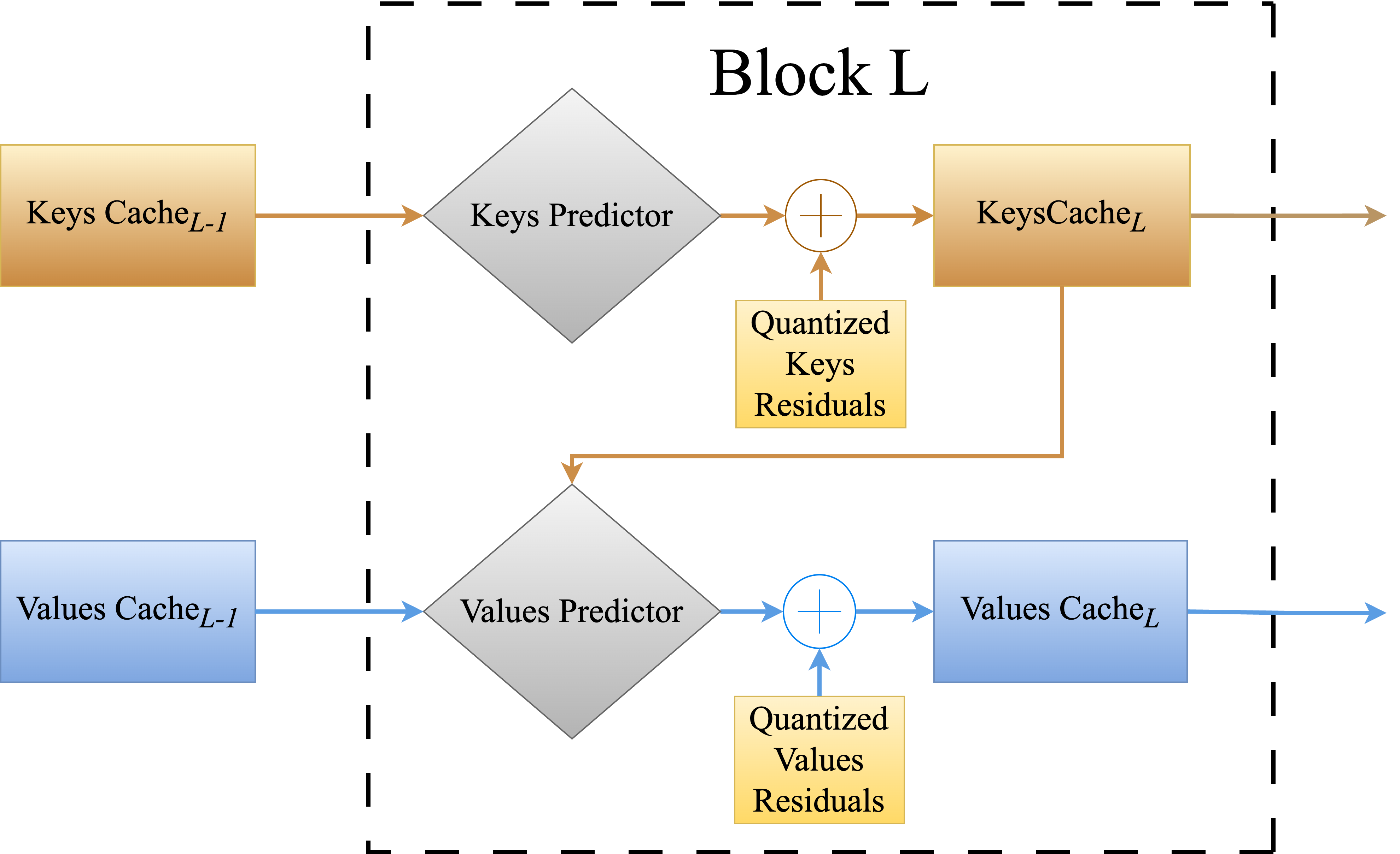
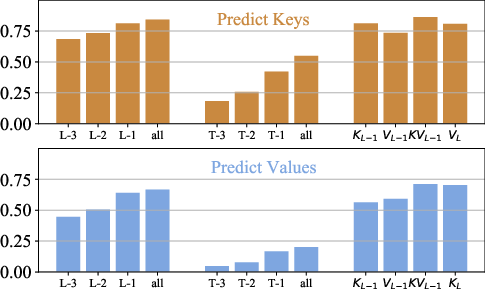
Figure 2: Mean Explained Variance Ratios by linear probes from previous blocks (L), tokens (T), and role on Llama-3.2-3B.
Discussion and Future Implications
AQUA-KV's novel strategy provides a balance between compression depth and task performance without necessitating excessive re-computation, making it suitable for deployment across varying hardware capabilities. As LLMs become more integral across natural language processing applications, maintaining a scalable and reliable inference process is critical. AQUA-KV's compatibility with existing quantization and pruning techniques provides a robust framework for future developments in LLM deployment.
Conclusion
AQUA-KV represents a pivotal advancement in KV cache management for LLMs, effectively bridging the gap between efficiency and accuracy. This approach facilitates scalable deployments and sets a new standard for adaptive quantization methods applicable to next-generation AI models.
```
Note: The text presents a technical summary and detailed insights from the paper "Cache Me If You Must: Adaptive Key-Value Quantization for LLMs." The figures referenced are for illustrative purposes, demonstrating quantitative performance improvements offered by the AQUA-KV method.