- The paper introduces SVD-based mixed-precision quantization for LLM KV cache compression, achieving effective 1.25-bit precision and up to 410x compression.
- It employs singular value decomposition to transform the K cache into latent channels, allowing targeted precision allocation based on channel significance.
- Experimental results on RULER and LongBench benchmarks show maintained model accuracy and compatibility with sparsity techniques for efficient inference.
SVDq: 1.25-bit and 410x Key Cache Compression for LLM Attention
Introduction and Background
Efficient inference of LLMs heavily depends on the compression of the key-value (KV) cache, a critical component responsible for encoding past information during attention computations. Existing approaches to KV cache compression fall into three categories: sparsity, channel compression, and quantization. Each of these methods targets different aspects of the KV cache to improve efficiency and reduce memory footprint.
SVDq introduces a novel compression method based on Singular Value Decomposition (SVD) combined with mixed precision quantization specifically for the K cache. This approach leverages SVD to transform the original K cache into latent channels, exploiting the rapid decay of values in these channels for efficient quantization.
Given the prominent role of LLMs in various AI applications, the demand for efficient inference mechanisms is growing. Specifically, as the size of KV caches expands with longer sequences or batch sizes, traditional inference approaches face substantial bottlenecks in terms of memory consumption and latency. SVDq aims to alleviate these issues, allowing LLMs to be deployed on memory-constrained devices while maintaining high performance.
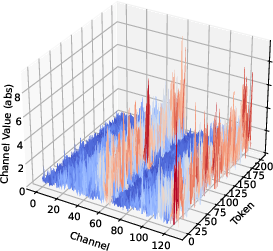
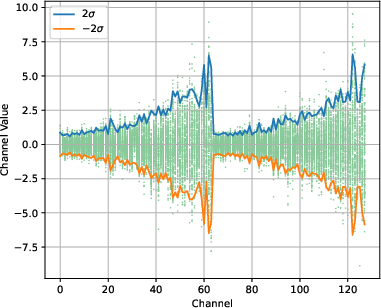
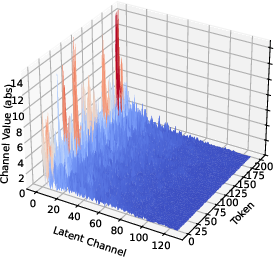
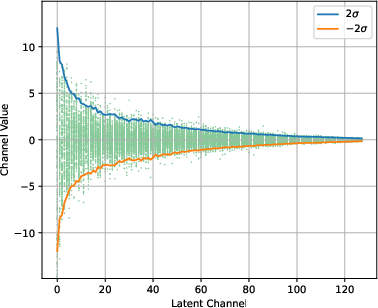
Figure 1: Original K.
SVD-Based Quantization Technique
In SVDq, the K cache is decomposed using SVD into orthonormal basis representations, adhering to the Eckart–Young–Mirsky theorem. These basis representations allow the transformation of the K cache into smaller latent channels that decay rapidly. The decay in singular values suggest that many latent channels contribute negligibly to the overall information retention, providing a basis for selectively applying precision-aware quantization.
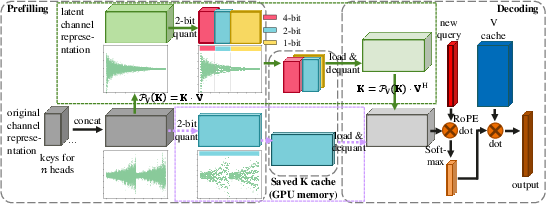
Figure 2: Diagram of SVDq method (path inside the box in green) versus direct per-channel quantization (dash path inside the box in violet).
SVDq employs a mixed-precision quantization scheme that initially assigns higher bit widths to more significant latent channels and progressively decreases the precision for less significant channels. This method avoids the pitfalls of uniform quantization in the original channel dimension, where variance is more uniformly distributed, often resulting in significant quantization errors.
Theoretical Insights
The paper provides a theoretical foundation for SVDq, showcasing that E[(PV(K))2], the variance of the projected latent channels, is proportional to the square of corresponding singular values. With this insight, SVDq's quantization scheme effectively mitigates quantization errors by allocating precision based on the significance of singular values. High precision is applied where singular values—and hence variances—are high, minimizing information loss during compression.
The theoretical analysis illustrates that SVDq achieves quantization errors substantially lower than per-channel quantization in the original key space. This results in retaining nearly lossless model performance even at lower bit widths, such as an equivalent precision of 1.25-bit when combined with sparsity techniques.
Experimental Results
Experiments on RULER and LongBench benchmarks demonstrate the efficacy of SVDq in achieving compressions up to 410x while maintaining comparable model performance. Notably, SVDq outperforms existing approaches such as ThinK and direct per-channel quantization in preserving model accuracy during inference.
SVDq proves compatible with sparsity techniques, such as those used in ShadowKV, where it achieves even higher compression ratios (up to 410x) with negligible performance degradation. This compatibility showcases its versatility in adapting to various compression strategies within the KV cache compression landscape.
Practical Implications and Future Directions
The implications of SVDq span both practical and theoretical realms. Practically, it provides a robust solution to KV cache compression, enabling deployment of performant LLMs with minimized memory footprint. Theoretically, it casts light on the profound impact of singular value distributions in designing quantization strategies.
Potential future developments include exploring SVDq's integration with other attention mechanisms beyond transformers, investigating its potential in real-time applications, and optimizing its computational aspects to reduce inference latency further.
Conclusion
SVDq represents a significant advancement in KV cache compression for LLMs by integrating SVD with mixed precision quantization. Through its innovative approach, it achieves high compression rates, particularly when combined with sparsity, while ensuring sustained model accuracy. By addressing KV cache memory constraints, SVDq facilitates efficient inference, paving the way for broader application in AI-driven technologies.