- The paper introduces Wan, a diffusion transformer-based model using spatio-temporal VAE to achieve efficient video compression and high generative quality.
- It employs a sophisticated data processing pipeline that dynamically allocates diverse, high-quality data to enhance video fidelity and motion accuracy.
- Wan outperforms state-of-the-art benchmarks in text-to-video tasks and offers multilingual video generation capabilities, promoting broader creative applications.
Overview of Wan: Open and Advanced Large-Scale Video Generative Models
The paper "Wan: Open and Advanced Large-Scale Video Generative Models" (2503.20314) presents Wan—a suite of video generative models built upon diffusion transformers. The authors focus on advancing video generative capabilities through innovations in model architecture, data processing, and evaluation metrics. Wan stands out due to its comprehensive capabilities, resource efficiency, and open-source nature, which aim to accelerate growth in the video generation community.
Model Architecture and Key Innovations
Wan's architecture employs a diffusion transformer paradigm, leveraging a spatio-temporal variational autoencoder (VAE) for effective video compression. The Wan-VAE optimizes memory usage and computational efficiency by compressing the video into a lower dimensional space of 4×8×8, a critical enhancement for scaling models to long video sequences.
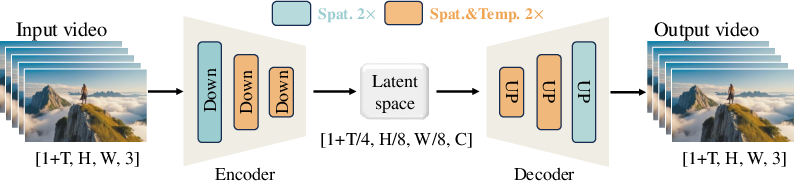
Figure 1: Our Wan-VAE Framework. Wan-VAE can compress the spatio-temporal dimension of a video by 4×8×8 times. The orange rectangles represent 2× spatio-temporal compression, and the green rectangles represent 2× spatial compression.
Moreover, the model integrates a cross-attention mechanism for precise text condition embedding, crucial for maintaining computational efficiency and improving instruction adherence. The utilization of a full spatio-temporal attention mechanism further optimizes the model's ability to handle complex dynamics inherent in video data.
Data Processing Pipeline
Data quality and variety are emphasized through a structured pre-training pipeline focusing on high-quality and diverse data across billions of images and videos. The rigorous cleaning process ensures optimal visual and motion quality, employing clustering and scoring systems to preserve small yet significant data segments and to enhance motion diversity.
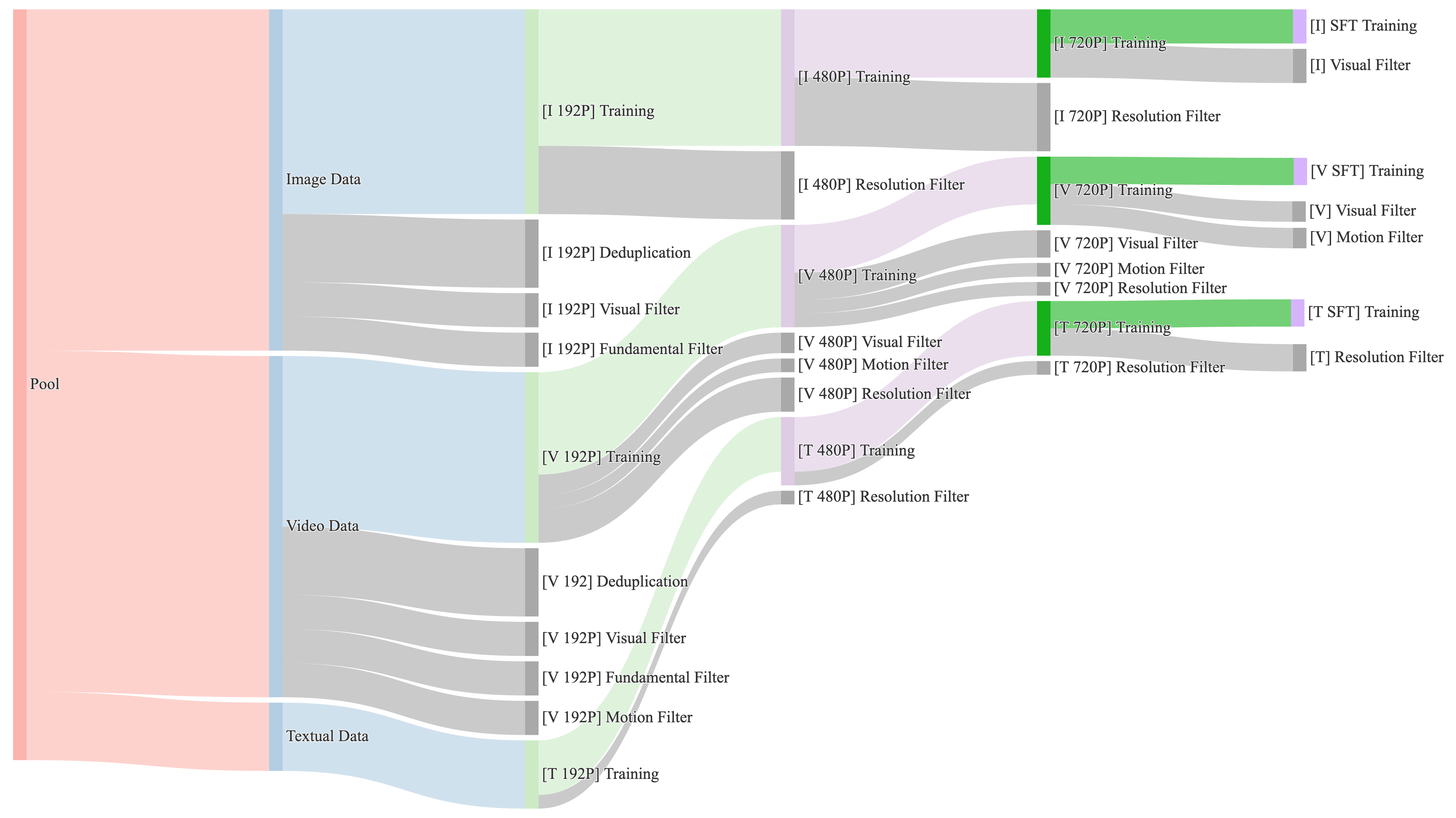
Figure 2: Data provisioning across different training phases. For each stage, we dynamically adjust the proportions of data related to motion, quality, and category based on data throughput.
During post-training, the pipeline further refines data quality by targeting specific visual and motion attributes to enhance video fidelity and production realism.
Evaluations and Results
Wan's 14B model exhibits leading performance across multiple state-of-the-art benchmarks, significantly surpassing existing open-source and commercial models in both efficiency and generative quality. Its 1.3B model offers consumer-grade efficiency with minimal VRAM requirements, outperforming larger models in text-to-video tasks.
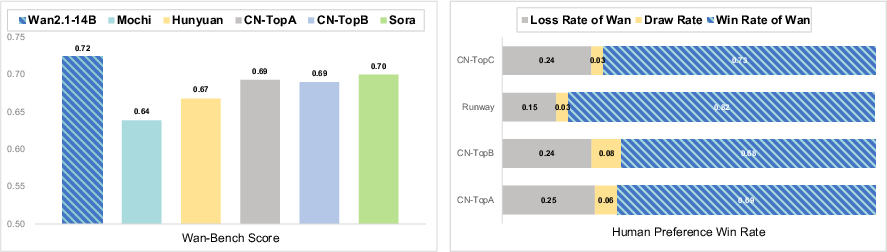
Figure 3: Comparison of Wan with state-of-the-art open-source and closed-source models. Following both benchmark and human evaluations, Wan consistently demonstrated superior results. Note that HunyuanVideo is tested using the open-source model.
Video Generation Capabilities
Wan excels in generating high-fidelity, realistic videos with complex motion dynamics, and creative transitions. It uniquely supports multilingual visual text generation, providing substantial practical utility.
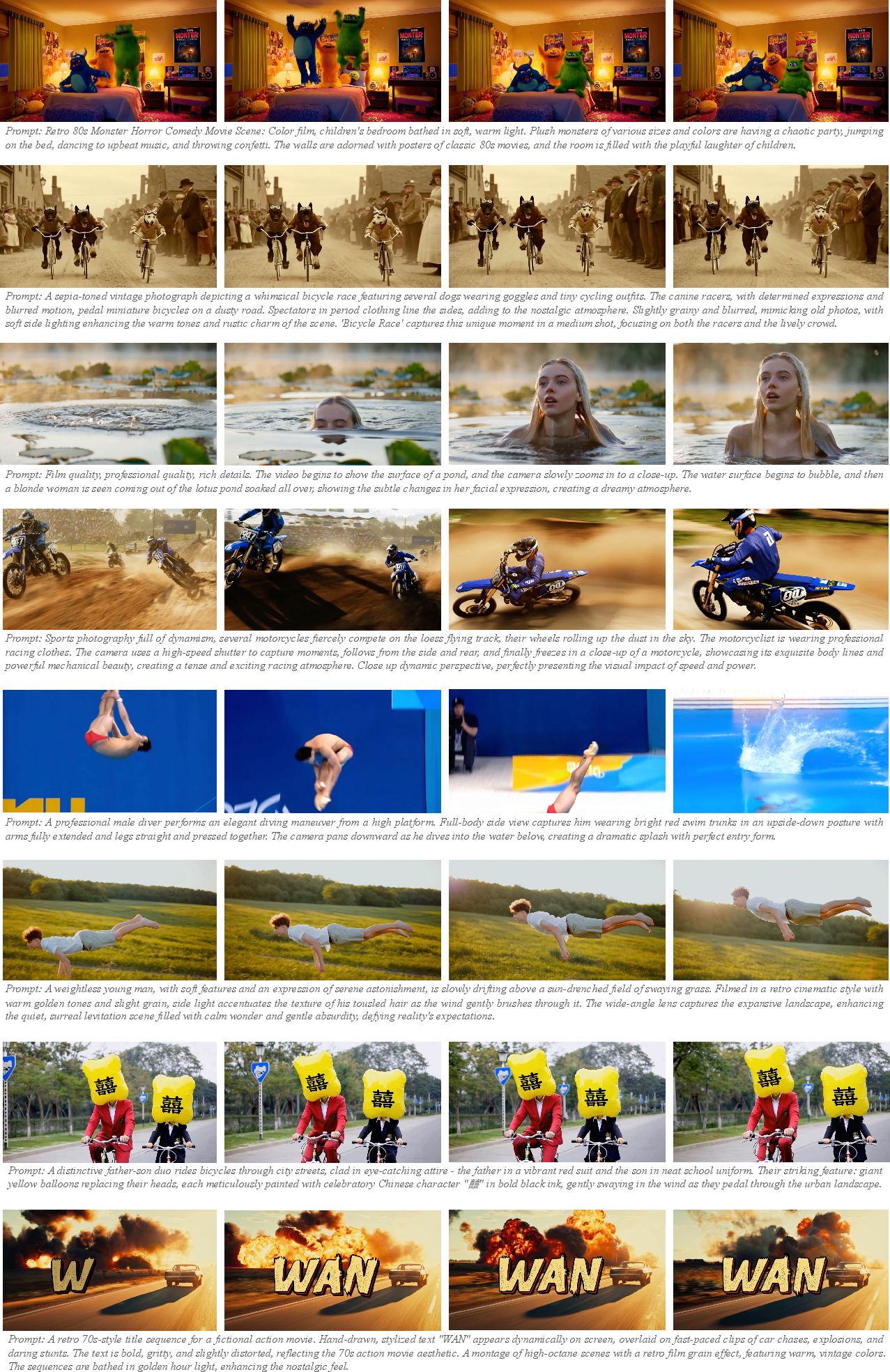
Figure 4: Results of the Wan-T2V. Our model excels at generating complex motions, creative transitions, cinematic-quality videos, and accurately produces both Chinese and English text.
The model's versatility is further showcased through its ability to perform a diverse array of tasks, including image-to-video generation, video editing, and personalized video creation.
Implications and Future Directions
Open Source Contributions
The decision to open-source Wan is aimed at fostering innovation and expanding creative boundaries within the video generation community. By providing high-quality foundation models and detailed design insights, the authors strive to empower academia and industry alike.
Theoretical and Practical Implications
Wan's robust architecture and efficient processing strategies signal significant advances in video generative models, setting new benchmarks in scalability and generative quality. The promising results highlight potential applications in real-time content creation, multimedia production, and interactive media, leading to enhanced user experiences and novel AI-driven functionalities.
Speculative Future Development
Future developments could focus on expanding Wan's generative and computational efficiencies while exploring deeper integrations with real-time systems and virtual environments. Moreover, advancements in personalized video generation and interactive multimedia may yield transformative impacts across entertainment, education, and communication sectors.
Conclusion
Wan represents a significant stride in the landscape of video generative models, blending performance and scalability with open-source accessibility. By harnessing advanced diffusion transformers and enhancing data pipelines, Wan delivers state-of-the-art results, setting a new standard for video generation technology. The model's capabilities and design offer profound implications for future AI applications, poised to redefine multimedia and interactive content creation.

