- The paper introduces a novel diffusion transformer with decoupled spatial and temporal layers to enhance text-to-video and image-to-video synthesis.
- It employs a robust, multi-stage data curation pipeline and advanced post-training optimizations, including RLHF, to refine video quality and motion naturalness.
- Benchmarks demonstrate that Seedance 1.0 achieves state-of-the-art performance with a 10× inference speedup and top rankings on T2V and I2V leaderboards.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Introduction
Seedance 1.0 represents a significant advancement in video generation models, addressing key challenges in maintaining balance among prompt following, motion plausibility, and visual quality. The model introduces innovations in multi-source data curation, architectural efficiency, post-training optimization, and inference acceleration. These elements collectively enable comprehensive learning, efficient text-to-video (T2V) and image-to-video (I2V) task execution, and superior video generation performance.
Data Curation and Processing
The approach involves curating a large-scale diverse video dataset with comprehensive video captioning. The video data processing pipeline transforms heterogeneous raw videos into refined training datasets through diversity-oriented data sourcing, multi-stage curation, and embedding generation using VAEs.
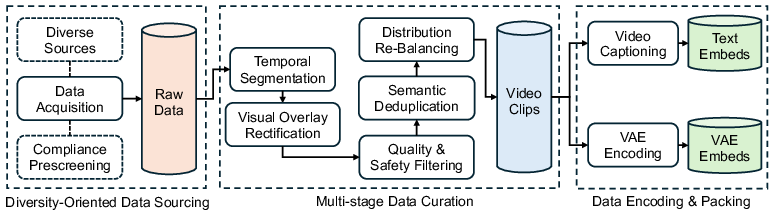
Figure 1: Our video data processing pipeline, transforming heterogeneous raw videos into a refined, feature-rich training dataset.
Overall Model Design
Seedance 1.0 features a diffusion transformer with decoupled spatial and temporal layers, enabling joint T2V and I2V learning and supporting multi-shot generation. The architecture employs window attentions and multimodal positional encoding to enhance efficiency.
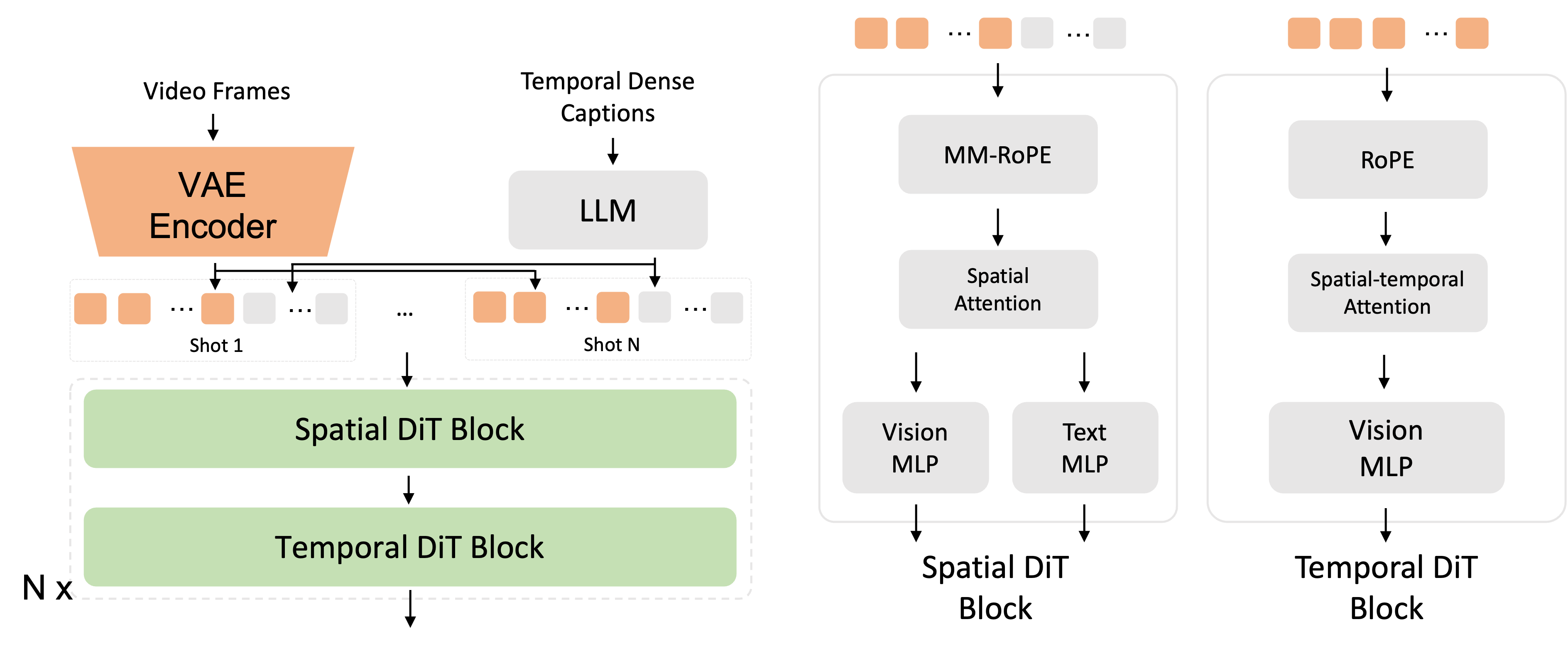
Figure 2: Our diffusion transformer architecture.
Enhancements in Post-Training
Post-training optimizations focus on supervised fine-tuning using fine-grained feedback-driven learning algorithms and video-specific RLHF. These improve model performance across aspects like motion naturalness and structural coherence.
Inference Efficiency
The proposed multi-stage distillation framework achieves approximately a 10× speedup in inference, with no performance degradation. This is enabled through function evaluation optimization and system-level enhancements.
Model Architecture and Training
Variational Autoencoder (VAE)
The VAE framework allows spatial-temporal compression of images and videos. The compression ratio is optimized by setting downsample ratios and channel dimensions, enhancing training and inference efficiency.
Diffusion Transformer
Leveraging visual tokens encoded by VAE and textual embeddings from a fine-tuned decoder-only LLM, the diffusion transformer processes these concatenated tokens. MMDiT architecture facilitates cross-modality integration, enhancing generation capabilities across diverse styles and scenarios.
Cascade and Progressive Training
Cascade framework enables high-resolution video generation, starting from 480p upscaled to 720p or 1080p, maintaining visual detail. Progressive training using joint text-image-video adaptation enhances learning efficiency and videographic smoothness.
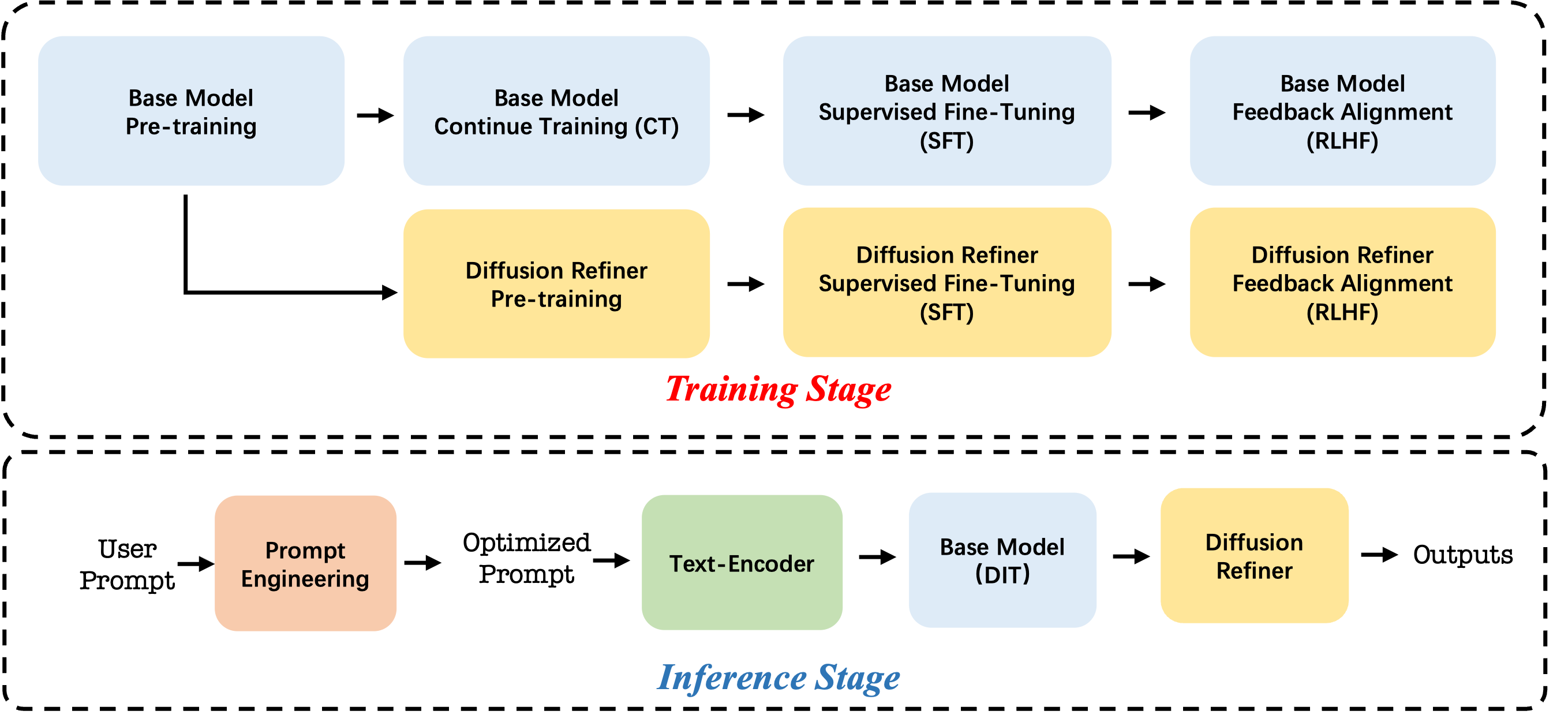
Figure 3: Overview of training and inference pipeline.
Reward and Feedback Mechanisms
Human Feedback Alignment (RLHF)
Comprehensive reward models enhance fundamental model capabilities, emphasizing image-text alignment, motion quality, and aesthetics. Multi-dimensional rewards from foundational, motion, and aesthetic reward models allow tailored RLHF optimization.
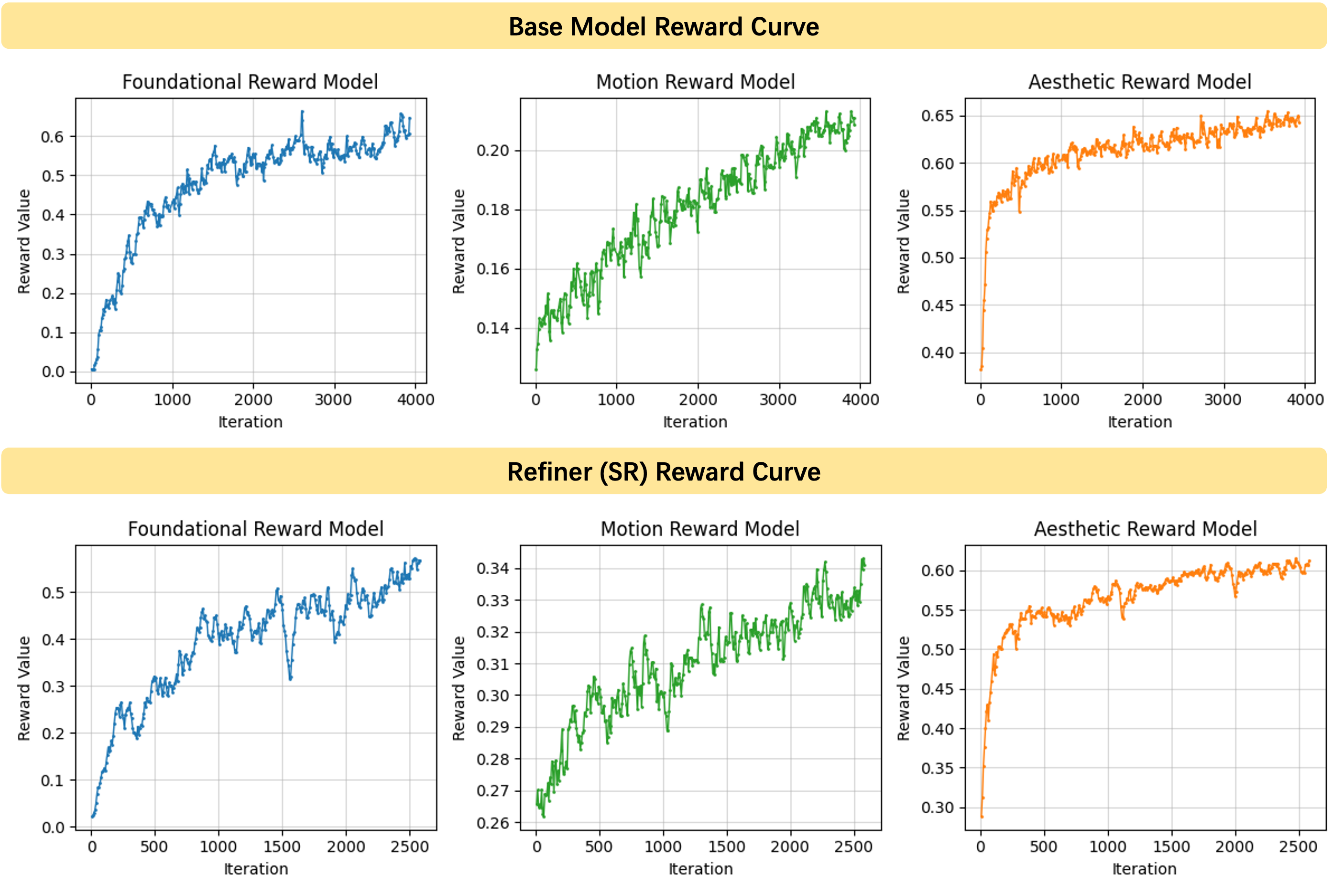
Figure 4: The reward curves show that the values across diverse reward models all exhibit a stable and consistent upward trend during the base model and Refiner RLHF process.
Super-Resolution RLHF
The model employs RLHF directly on the accelerated refiner model, enhancing generated video quality under low-NFE conditions.
Benchmarking
Seedance 1.0 achieves leading performance on Artificial Analysis leaderboards for both T2V and I2V tasks, demonstrating superior spatiotemporal coherence, precision, and generation speed (Figure 5).
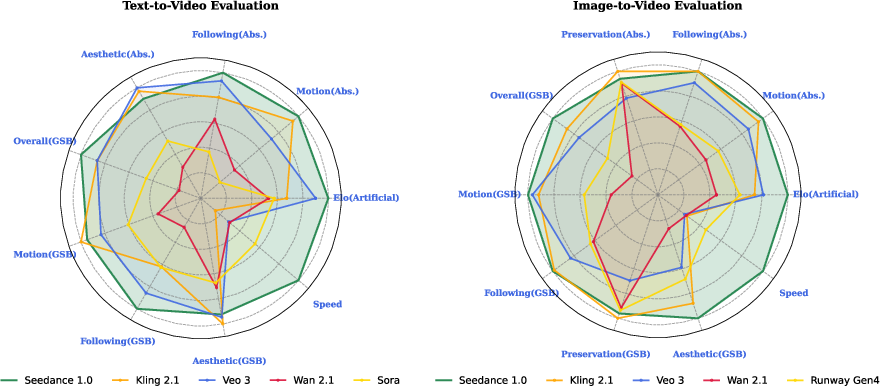
Figure 5: Overall evaluation. Left: Text-to-Video; Right: Image-to-Video. Seedance 1.0 ranks first on both the two video generation leaderboards of Artificial Analysis on Jun 10, 2025.
Internal and External Evaluations
Through SeedVideoBench-1.0, comprehensive assessments across motion quality, prompt adherence, and aesthetic fidelity in diverse contexts affirm Seedance 1.0's capability to deliver state-of-the-art video content aligned with professional cinematic standards.
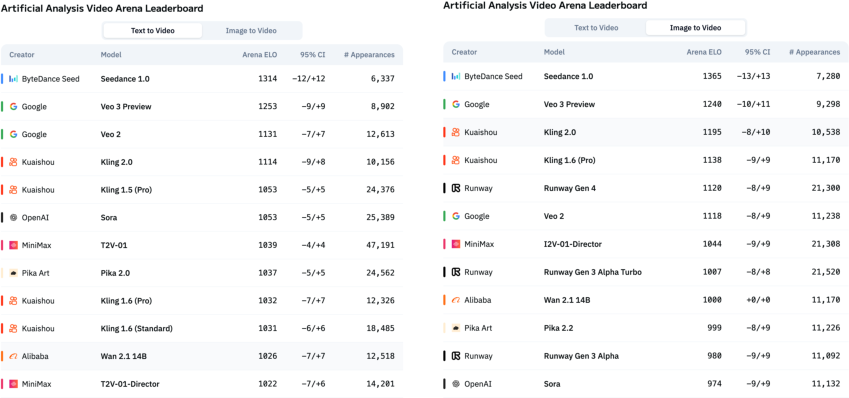
Figure 6: Results from Artificial Analysis Arena. Seedance 1.0 achieves the top position on both the text-to-video and image-to-video leaderboards.
Conclusion
Seedance 1.0 synthesizes technical innovations in data processing, model architecture, and inference to push the boundaries of video generation. It supports T2V and I2V tasks through a unified model, demonstrating high-quality outputs and fast generation speeds. Its integration into various platforms will support professional and creative workflows, unlocking new possibilities in videographic applications and AIGC domains.