- The paper introduces SkyReels-V2, a generative model that produces infinite-length, high-resolution videos with consistent cinematic quality and detailed shot grammar.
- It employs a multi-stage pretraining pipeline and a novel structured captioning strategy to enhance temporal coherence and prompt adherence.
- The framework integrates rigorous data curation and motion-specific reinforcement learning to mitigate visual distortions and error accumulation in extended video synthesis.
SkyReels-V2: A Framework for Infinite-Length, Cinematic-Quality Video Generation
Introduction and Motivation
SkyReels-V2 introduces an open-source generative model designed to produce virtually unlimited-length, high-resolution, and cinematically consistent video. This work responds to persistent limitations of prior video generation methods, particularly regarding prompt adherence (especially to shot-scenario descriptions), motion dynamics, temporal consistency, and extended sequence scalability. Existing systems often optimize either visual fidelity or temporal coherence, but fail to harmonize both, especially for film-style outputs that demand complex shot grammar, entity consistency, and dynamic motion. SkyReels-V2 proposes architectural, data, and training innovations to advance this frontier.

Figure 1: SkyReels-V2 produces cinematic, distortion-free, and visually consistent high-resolution videos of virtually unlimited length, excelling at maintaining the main subject’s integrity across all frames.
Methodology
Data Processing and Curation Pipeline
A robust data pipeline underpins model performance, incorporating large-scale diverse video sources (commercial films, TVs, web-mined content), systematic filtering for quality and genre balance, subtitle/logo removal, shot segmentation, and intensive human-in-the-loop validation. Subtitle and logo overlays, prevalent in media content, are addressed through spatial detection and cropping, using OCR and logo detectors to isolate and maximize usable frame area.
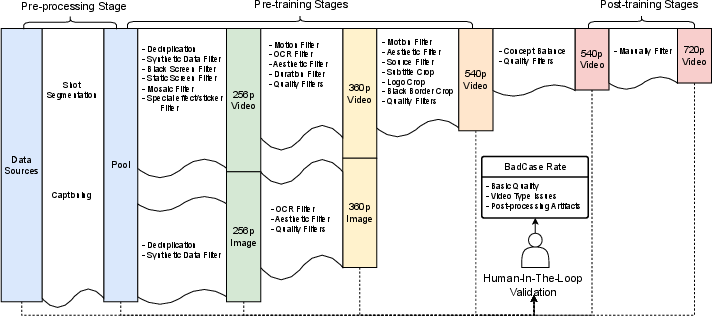
Figure 3: Schematic of the multi-stage data processing pipeline, emphasizing automated filtering and human validation for quality assurance.
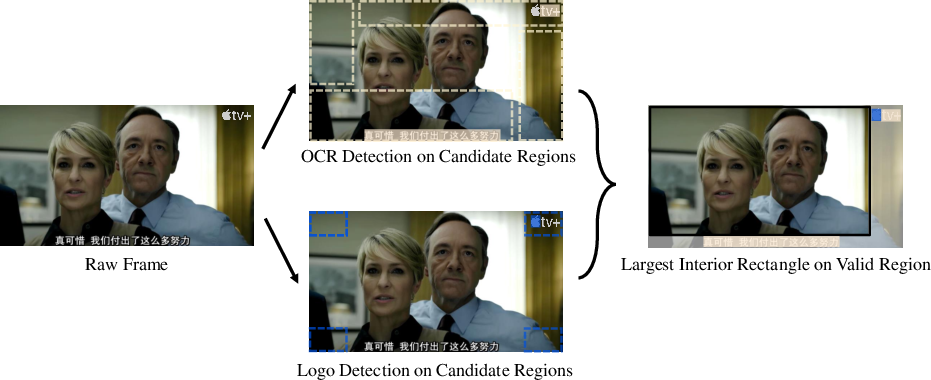
Figure 2: Subtitle and logo cropping pipeline—candidate regions are detected, then maximal interior rectangles beyond detected overlays are found and cropped.
Concept balance during the post-training data curation reduces bias toward prevalent subject categories, ensuring improved generalization and facilitating effective supervised fine-tuning.
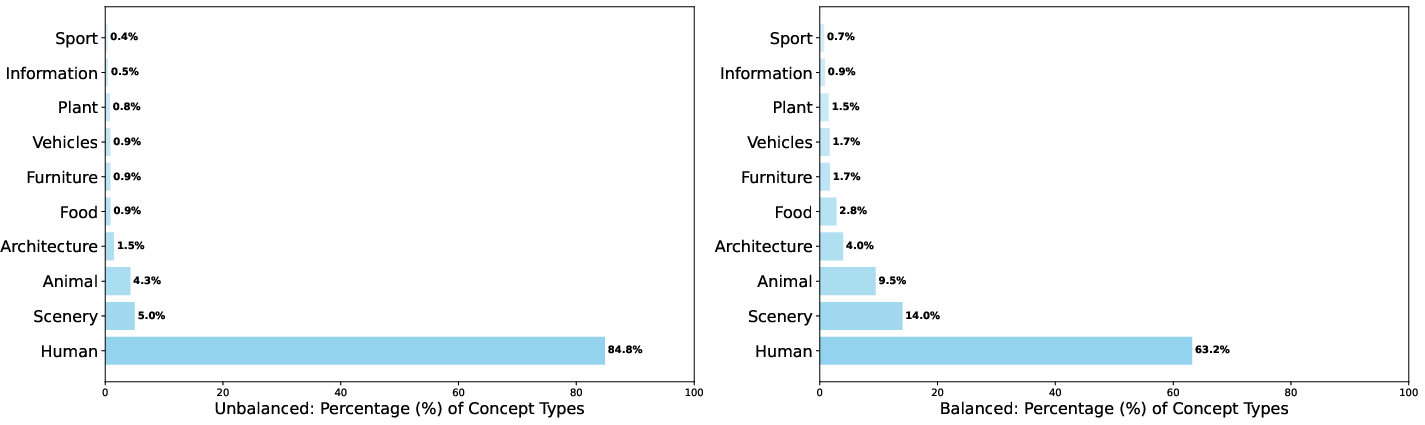
Figure 4: Distribution comparison between unbalanced (left) and concept-balanced (right) training data, demonstrating enhanced category uniformity.
Structural Video Captioning
One central advancement is the shift to a structured video captioning approach, fusing hierarchical MLLM-based descriptions with specialized shot-type, expression, and camera motion experts. This yields rich, interpretable representations critical for both model conditioning and downstream prompt adherence.

Figure 5: Visual depiction of the structural caption, integrating subject, shot, expression, and camera movement fields.
SkyCaptioner-V1, the unified captioner, leverages distillation from domain-general and domain-specific models, achieving superior accuracy (average 76.3%, 93.7% shot-type field) compared to existing SOTA captioners across multiple fields pertinent to cinematic grammar.
Multi-Stage Pretraining and Enhancement
The base video generator is built with three-stage, progressive-resolution pretraining—moving from 256p to 540p—jointly on videos and concept-balanced images, normalizing duration and aspect ratios using a dual-axis bucketing strategy and FPS normalization to stabilize spatiotemporal heterogeneity. Flow matching is used as the generative objective to efficiently model complex temporal distributions.
Post-Training Optimization
Key advancements are realized in four post-training stages:
- Concept-balanced SFT (540p) for initialization
- Motion-specific Reinforcement Learning via Direct Preference Optimization (DPO) on human/model-annotated motion-distortion pairs
- Diffusion Forcing Training: converts the full-sequence diffusion model into a diffusion-forcing transformer, enabling variable-length, "infinite" rollouts by assigning per-frame independent noise schedules under non-decreasing constraints, with adaptive denoising at inference for long-form, temporally consistent synthesis
- High-Resolution SFT (720p) for final quality refinement
Motion preference annotation leverages a hybrid pipeline—curating and distorting real videos to explicitly simulate failure modes such as entity distortion and physics violations—to construct effective DPO training pairs.



Figure 8: Example of V2V-induced slight facial corruption in generated video—typical of progressive motion-related artifacts addressed via motion-specific RL.
Systematic evaluation is conducted on both proprietary (SkyReels-Bench) and public (V-Bench 1.0) benchmarks. SkyReels-V2 demonstrates superior instruction adherence (3.15/5), visual consistency (3.35/5), and visual quality (3.34/5) on human assessments compared to other leading open and closed-source systems, with robust motion quality scores. On V-Bench, SkyReels-V2 attains the highest total and quality scores (83.9%, 84.7%), marginally outperforming strong open-source baselines and slightly trailing on purely semantic scores due to V-Bench's lower emphasis on shot grammar.

Figure 6: Long-form video (30s+) generated from a single prompt—demonstrates temporal extension and intra-shot consistency.

Figure 7: Ultra-long video generated using sequential prompts for dynamic narrative progression while maintaining subject consistency.
Applications
SkyReels-V2 supports several advanced generative settings:
Theoretical and Practical Implications
The integration of structured shot-aware captioning with multi-stage curriculum, motion-specific RL alignment, and diffusion-forcing inference establishes a new paradigm for aligning generative models with fine-grained cinematic conditioning and scalable generative fidelity. By uniting diffusion’s high spatial quality with autoregressive scalability (via diffusion-forcing and scheduling adaptations), the framework circumvents previous trade-offs—approximating the flexibility of LLM token generation at the frame level.
Practically, open-sourcing SkyReels-V2, its captioner, and elements-to-video codebases provides a resource for both research and industry to further probe, extend, and specialize film-quality video generation, supporting downstream applications in content creation, virtual cinematography, automated storyboarding, and beyond.
Limitations and Future Directions
Deterministic error accumulation remains a limitation in truly indefinite-duration rollouts, especially under long autoregressive continuations. Handling cross-scene, character, and story consistency at feature scale will require improved modeling of long-term dependencies, possibly through hierarchical memory, scene-graph tracking, or learned retrieval. The extension to richer conditioning modalities (audio, pose, interactive editing) and the further tightening of physics-aware motion priors present promising theoretical directions.
Conclusion
SkyReels-V2 delivers an empirically validated, publicly available framework for infinite-length, cinematic-caliber video generation. By addressing data, conditioning, alignment, and model architecture holistically, it achieves unmatched prompt adherence, temporal and motion quality, and video fidelity for open-source systems. Its innovations set foundational benchmarks and open numerous avenues for research and deployment in generative video modeling (2504.13074).
