- The paper introduces SWIFT, a novel framework applying verifier-based test-time scaling to improve WFMs for video generation.
- It employs techniques like beam search and Top-K pruning to enhance 3D and temporal consistency while maintaining a fixed compute budget.
- Experimental results show that test-time scaling enables smaller models to achieve performance comparable to larger models in real-world simulations.
Enhancing World Foundation Models through Test-Time Scaling
Introduction
This paper investigates the potential of test-time scaling to enhance the performance of World Foundation Models (WFMs), which are designed to simulate real-world dynamics through video generation. This technique aims to optimize computational resources during inference rather than expanding model size or undergoing retraining. The proposed framework, SWIFT, introduces a novel approach to test-time scaling, particularly tailored for WFMs, which deal with high-dimensional video data crucial for applications such as autonomous driving and robotics.
Test-Time Scaling in WFMs
Motivation
Test-time scaling for WFMs is motivated by two primary factors. First, training WFMs is resource-intensive due to the large-scale video inputs required, making large model training challenging. Second, inference with larger models is computationally expensive, often equivalent to or more resource-consuming than running several smaller models. As a response, test-time scaling offers an alternative by utilizing additional computation during inference, potentially matching or even surpassing the performance of larger models.
Challenges
Adapting test-time scaling for WFMs involves addressing several challenges. WFMs utilize diffusion-based decoders that are inherently slow, and traditional benchmarks do not align well with the physical realism and consistency required by WFMs. Furthermore, designing an effective test-time strategy necessitates novel solutions distinct from approaches used for LLMs, primarily due to the sequential, autoregressive nature of video generation.
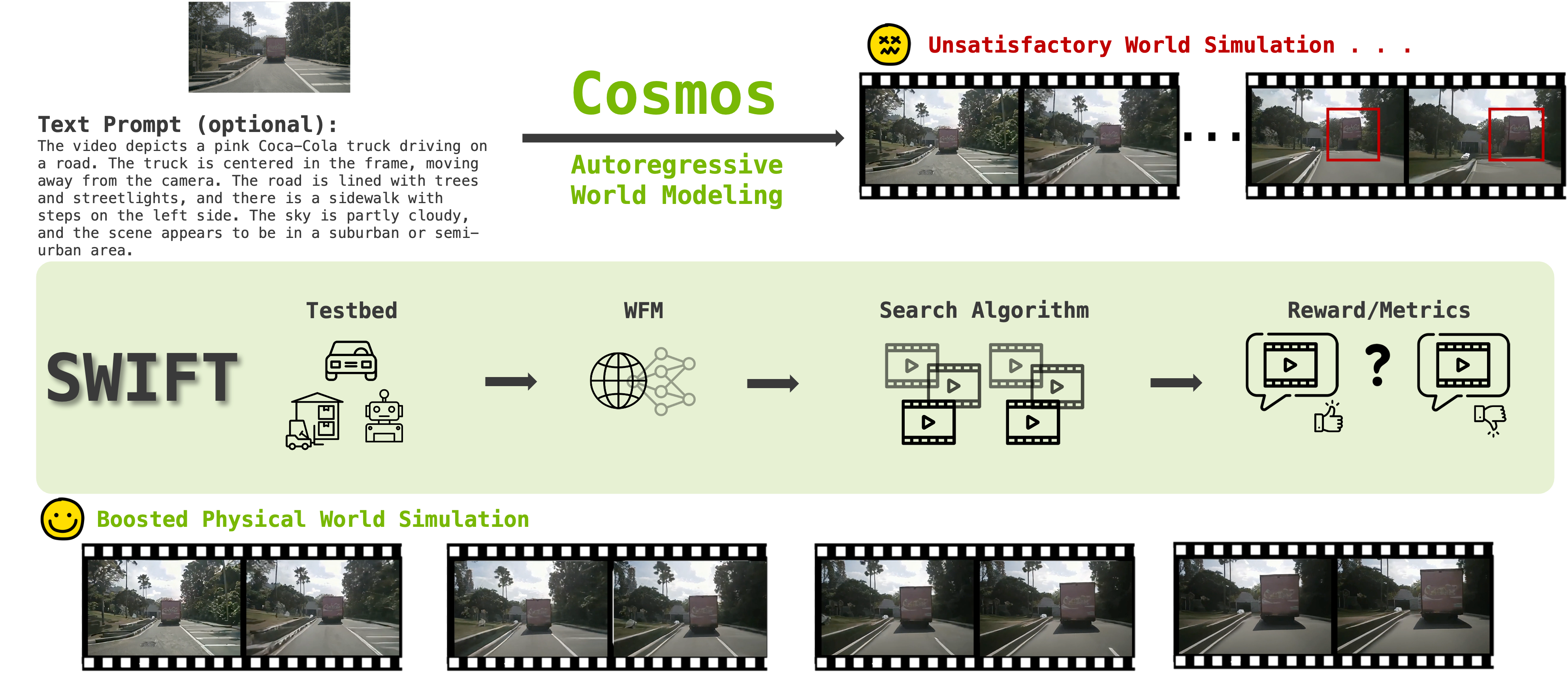
Figure 1: The SWIFT pipeline for studying test-time scaling (TTS) in world foundation models (WFMs). We use autoregressive world model COSMOS as a base, which initially produces an unrealistic world simulation (top panel). By applying our TTS method, the simulation is significantly enhanced and becomes more physically plausible (bottom panel).
SWIFT Framework
SWIFT is introduced as a comprehensive framework to evaluate and enhance WFMs through test-time scaling. The core components include a modular evaluation toolkit and process-level inference strategies such as fast tokenization, probability-based Top-K pruning, and a beam search algorithm.
The evaluation toolkit developed is designed specifically for WFMs and includes metrics such as 3D consistency, temporal consistency, spatial relationship awareness, perceptual quality, and text-to-video alignment. This toolkit enables a multi-faceted evaluation of WFM outputs, facilitating assessment across various applications.

Figure 2: Videos of world foundation model without (top) and with (bottom) TTS, where TTS improves 3D consistency (left) and temporal consistency (right) in the generated videos.
Empirical Findings and Methodology
Test-Time Scaling Strategy
At the core of the SWIFT framework is the adaptation of verifier-based test-time scaling strategies from LLMs to WFMs. The study demonstrates that simply increasing the number of sampled continuations improves video quality across multiple evaluation metrics, illustrating a robust test-time scaling law applicable to WFMs.
Verifier and Action Design
The framework employs rule-based rewards for verification, proven to be more stable, robust, and extensible compared to preference-based rewards. An efficient search algorithm, including beam search with probability adjustments, is employed to maintain exploration depth without excessive computational demands.
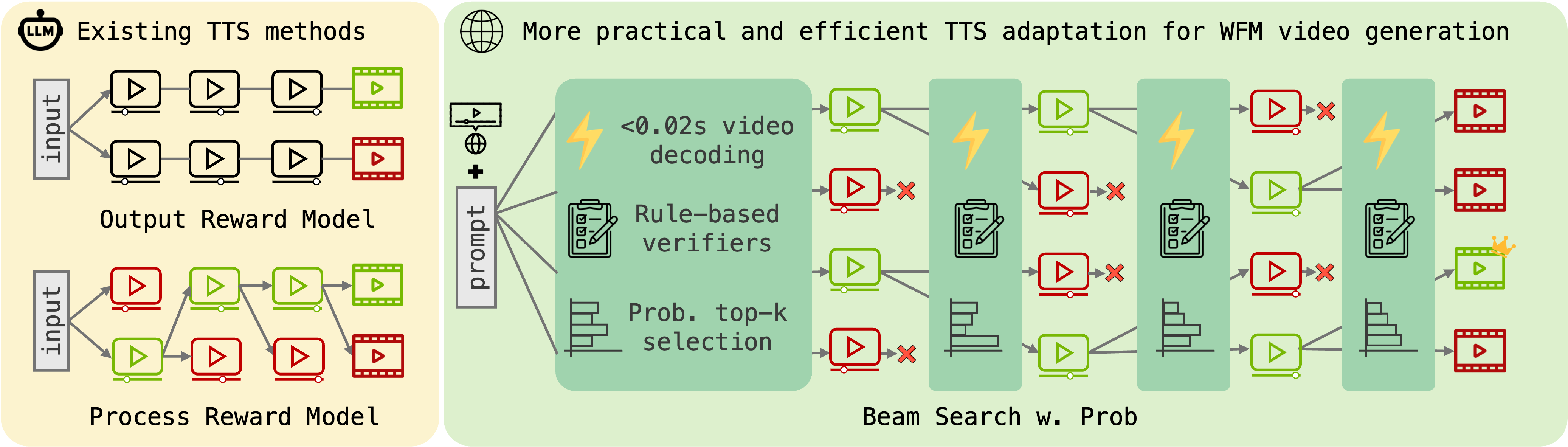
Figure 3: Compared to ORM and PRM, our proposed beam search with probability is more efficient and practical for WFMs with three key efficiency designs.
Experimental Results
The empirical study using the COSMOS model confirms that test-time scaling can achieve performance on par with larger models while maintaining a fixed compute budget, highlighting computational efficiency. Notably, SWIFT enables smaller models to match or exceed the performance of much larger models under equivalent inference-time computational constraints.

Figure 4: COSMOS-4B without (top) and with ORM (middle) and our (bottom) test-time scaling.

Figure 5: COSMOS-5B without (top) and with ORM (middle) and our (bottom) test-time scaling.
Conclusion
The introduction of SWIFT offers a scalable and practical solution for enhancing the inference capabilities of WFMs through test-time scaling. The framework provides a more efficient alternative to traditional model scaling, reducing reliance on extensive retraining and large-scale model deployment. This work not only advances the understanding of scaling laws within the WFM domain but also presents a feasible path for deploying WFMs in computationally constrained environments, such as real-time autonomous systems. Future work should further explore scaling strategies for even larger models and investigate additional application domains beyond autonomous driving to expand the impact of these findings.