- The paper introduces SciReplicate-Bench, a benchmark that evaluates LLMs’ ability to reproduce algorithms from recent NLP research using a dual-agent system.
- It presents a detailed analysis of algorithmic comprehension and code generation metrics, highlighting challenges like low execution accuracy and dependency issues.
- The study emphasizes the need for improved retrieval-augmented architectures and prompt engineering to bridge the gap between scientific descriptions and executable code.
SciReplicate-Bench: Evaluating LLMs in Agent-Driven Algorithmic Reproduction from Research Papers
The automation of scientific discovery using LLMs has advanced rapidly, yet the ability of LLMs to reproduce algorithms from peer-reviewed publications remains underexplored. Existing code generation benchmarks focus on general software engineering or simplified algorithmic tasks, lacking the complexity and rigor of real-world scientific algorithm reproduction. SciReplicate-Bench addresses this gap by introducing a benchmark specifically designed to evaluate LLMs' capacity to synthesize and implement algorithms directly from recent NLP research papers, emphasizing both algorithmic comprehension and executable code generation.
Benchmark Design and Task Structure
SciReplicate-Bench comprises 100 tasks derived from 36 recent NLP papers, each accompanied by open-source implementations. The benchmark is constructed to minimize data leakage by exclusively selecting papers published in 2024. Each task is centered on implementing a specific function or class method within a repository, requiring the model to:
- Comprehend the algorithm by synthesizing information from the paper, including LaTeX algorithm descriptions, workflow details, and hyperparameters, often distributed across multiple sections and citations.
- Implement the code within the provided repository, correctly handling intra- and cross-file dependencies, as well as external API calls.
The benchmark provides detailed annotations, including function signatures, algorithm descriptions, literature and repository context, reference implementations, reasoning graph annotations, dependency documentation, and a controlled Python execution environment with comprehensive test cases.
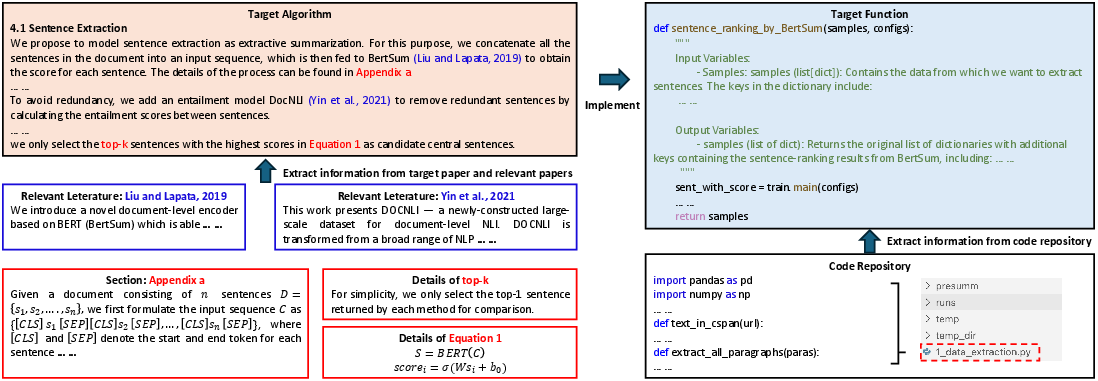
Figure 1: The two-step process of algorithm understanding and code implementation required for each benchmark task.
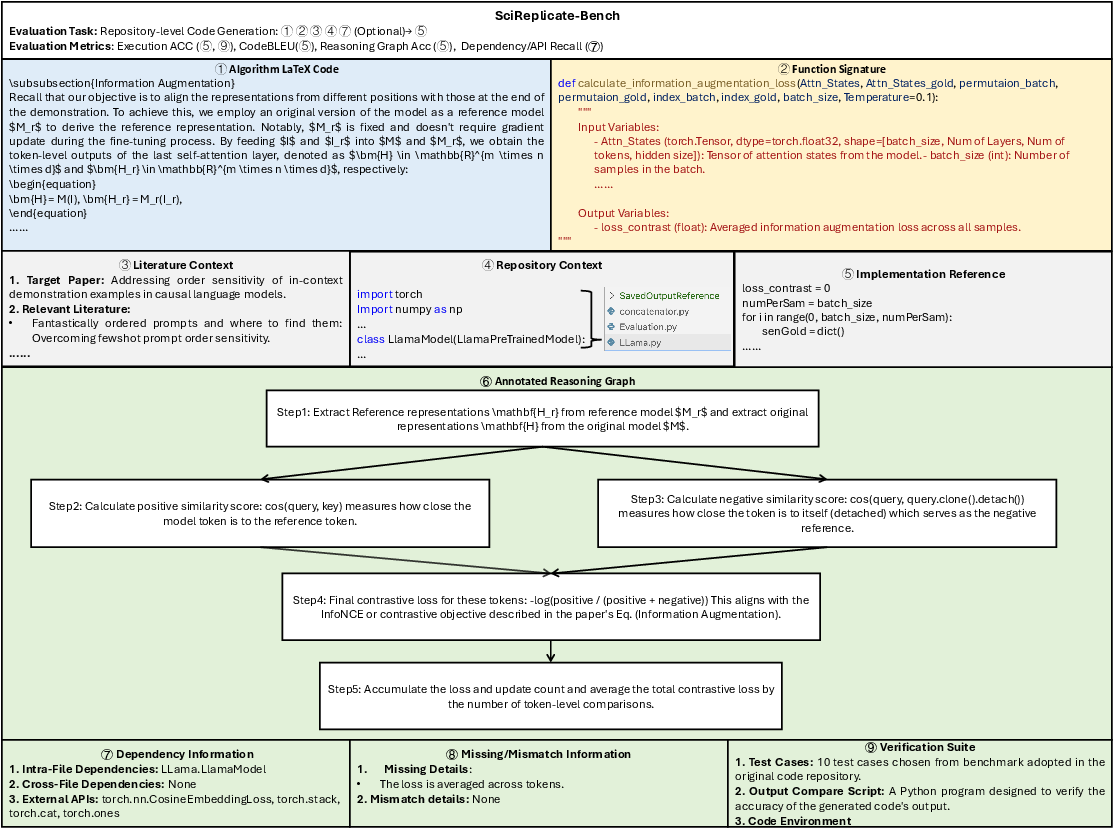
Figure 2: Overview of the SciReplicate-Bench dataset structure, including input components, evaluation artifacts, and analysis resources.
Task categories span representation/embedding methods, loss functions, information extraction, model architecture, and inference/search algorithms, as illustrated in the benchmark's taxonomy.
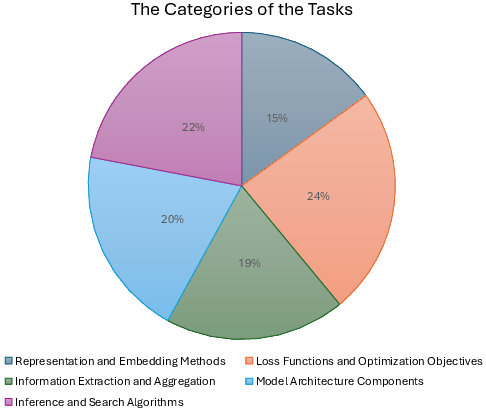
Figure 3: Distribution of task categories within SciReplicate-Bench.
Sci-Reproducer: Dual-Agent Framework
To operationalize the benchmark, the authors propose Sci-Reproducer, a dual-agent system comprising:
- Paper Agent: Retrieves and synthesizes relevant information from the literature context using a RAG-style approach, incrementally building an understanding of the target algorithm. The agent employs ReAct to interleave reasoning and action, selectively extracting information from the main paper and cited works. The output is a structured literature report that fills in missing or ambiguous algorithmic details.
- Code Agent: Ingests the algorithm description, literature report, and repository context, then searches for relevant code elements, dependencies, and external APIs. The agent can also browse the web and invoke a compiler for iterative debugging, ensuring syntactic and semantic correctness of the generated code.
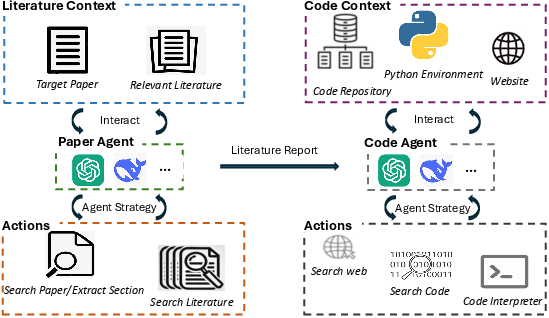
Figure 4: Overview of the Sci-Reproducer framework, showing the interaction between Paper Agent and Code Agent for algorithm reproduction.
Evaluation Metrics
The evaluation protocol is bifurcated to assess both algorithmic comprehension and code generation:
- Reasoning Graph Accuracy: A novel metric quantifying the alignment between the model's inferred reasoning steps (extracted from code comments and structure) and a reference reasoning graph. Nodes represent reasoning steps, and edges capture data flow. Node and edge matching is performed using GPT-4o, with significance scores reflecting code complexity.
- Code Generation Metrics: Execution accuracy (pass rate on all test cases), CodeBLEU (syntactic and semantic similarity to reference code), and recall of intra-file, cross-file, and API dependencies.
Experimental Results and Analysis
The benchmark evaluates seven advanced LLMs, including both non-reasoning (e.g., GPT-4o, Claude-Sonnet-3.7, Gemini-2.0-Flash, Deepseek-V3) and reasoning-augmented models (O3-mini variants). The key findings are:
- Low Execution Accuracy: Even the best-performing model (Claude-Sonnet-3.7 with Sci-Reproducer) achieves only 39% execution accuracy, underscoring the difficulty of the task and the gap between algorithmic understanding and practical implementation.
- Strong Algorithmic Comprehension: Reasoning graph accuracy scores are relatively high (average 0.716 without agent assistance), indicating that LLMs can often reconstruct the logical flow of algorithms even when code generation fails.
- Dependency and API Recall: Accurate identification and utilization of repository dependencies and external APIs are critical for successful implementation. The Code Agent substantially improves recall metrics, with the best models achieving intra-file, cross-file, and API recall of 0.776, 0.636, and 0.626, respectively.
- Overthinking in Reasoning LLMs: Reasoning-augmented LLMs exhibit "overthinking," favoring internal deliberation over tool usage, resulting in limited performance gains compared to non-reasoning models. This is evidenced by their lower frequency of invoking search and retrieval actions, as shown in the tool usage analysis.
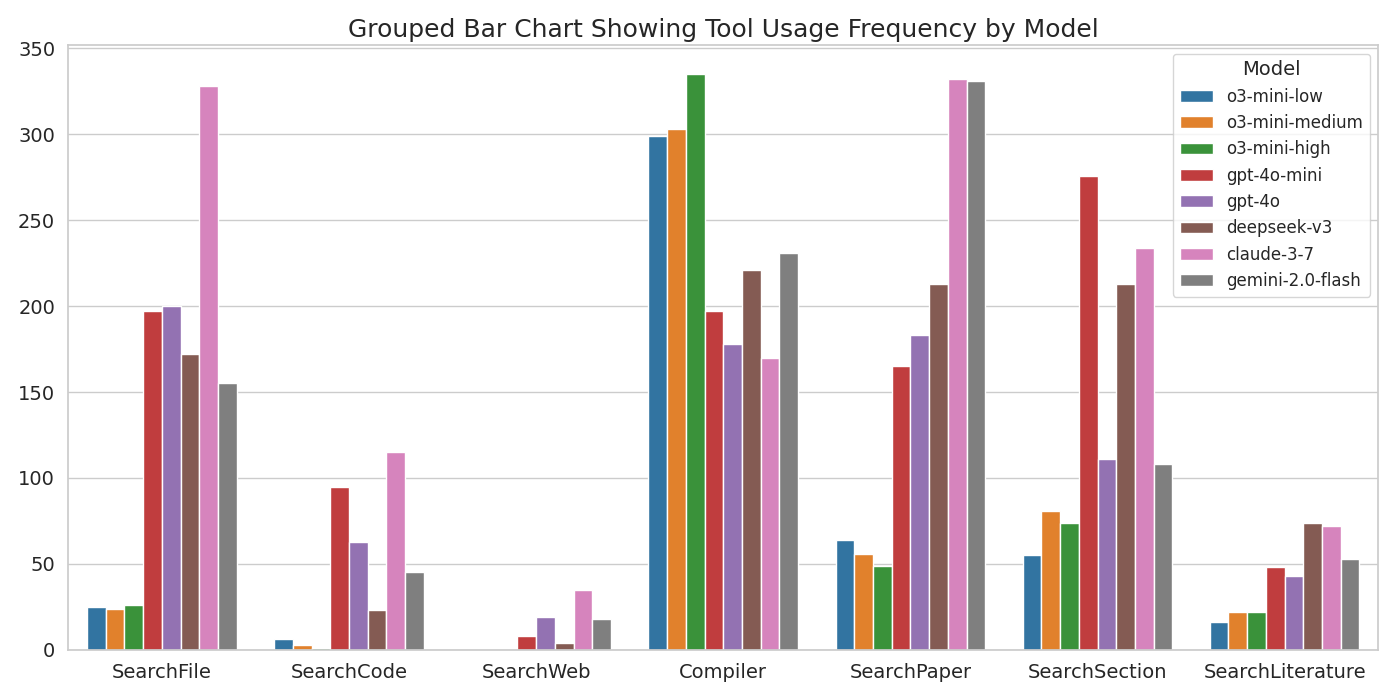
Figure 5: Frequency of tool usage by different models, highlighting the disparity between reasoning and non-reasoning LLMs in external information gathering.
Error Analysis
- Syntax Errors: The absence of the Code Agent leads to high syntax error rates (>80%), which drop to ~25% with agent assistance. Remaining errors are primarily due to incorrect handling of repository dependencies.
- Logic Errors and Missing Information: Discrepancies between paper descriptions and reference implementations are prevalent. Missing details fall into four categories: hyperparameters/configurations, numerical stability techniques, implementation logic, and coding strategies. Providing missing information as external input yields significant performance improvements (e.g., Deepseek-V3 execution accuracy increases from 0.220 to 0.470).
Prompt Engineering and Agent Outputs
The framework leverages carefully designed prompts for code generation, node alignment, and agent actions. Examples of these prompts and the Paper Agent's literature report output are provided for reproducibility and further research.

Figure 6: The prompt template for code generation, guiding the model to insert structured reasoning comments.

Figure 7: The prompt for node matching in reasoning graph evaluation.

Figure 8: The prompt for the Paper Agent, instructing literature retrieval and synthesis.

Figure 9: The prompt for the Code Agent, detailing repository search and code synthesis actions.

Figure 10: Example output report from the Paper Agent, summarizing extracted algorithmic details.
Implications and Future Directions
SciReplicate-Bench exposes the limitations of current LLMs in bridging the gap between scientific algorithm comprehension and executable code synthesis. The results highlight the need for:
- Enhanced retrieval-augmented and tool-integrated agent architectures that can more effectively gather and utilize contextual information from both literature and code repositories.
- Improved prompt engineering and in-context learning strategies to address missing or ambiguous implementation details.
- Systematic handling of incomplete or inconsistent algorithm descriptions, potentially via meta-learning or leveraging implementation patterns from similar algorithms.
- More robust evaluation protocols, including expanded human validation of reasoning graph accuracy and error categorization.
The benchmark and framework provide a rigorous testbed for future research on agentic LLMs in scientific automation, with direct implications for reproducibility, peer review, and the acceleration of scientific discovery.
Conclusion
SciReplicate-Bench establishes a challenging and comprehensive benchmark for evaluating LLMs in agent-driven algorithmic reproduction from research papers. The dual-agent Sci-Reproducer framework, coupled with novel evaluation metrics, reveals that while LLMs demonstrate strong algorithmic reasoning, practical code generation remains a significant bottleneck, primarily due to missing information and insufficient tool usage. The findings motivate further research into agentic architectures, retrieval augmentation, and systematic handling of incomplete scientific descriptions to advance the automation of scientific discovery.