- The paper demonstrates that excessively large language models can sacrifice multi-hop reasoning, revealing a U-shaped performance curve.
- It employs a synthetic knowledge graph environment to simulate reasoning challenges, identifying an optimal capacity of about 0.008 bits per parameter.
- Experimental results indicate that while larger models excel at memorization, they risk overfitting, underscoring the need for balanced model design.
Do Larger LLMs Generalize Better? A Scaling Law for Implicit Reasoning at Pretraining Time
Introduction
The paper "Do Larger LLMs Generalize Better? A Scaling Law for Implicit Reasoning at Pretraining Time" (2504.03635) investigates the interplay between the size of LLMs (LMs) and their reasoning capabilities during pretraining. Unlike traditional assumptions of larger models achieving superior performance, the study explores how overparameterization might impede implicit reasoning in LMs.
A synthetic environment, emulating real-world knowledge graph structures, is employed for training LMs to facilitate multi-hop reasoning. The paper reveals a counterintuitive discovery: excessive model size could degrade reasoning ability due to excessive memorization, deviating from conventional scaling laws that suggest bigger models are inherently better.
Methodology
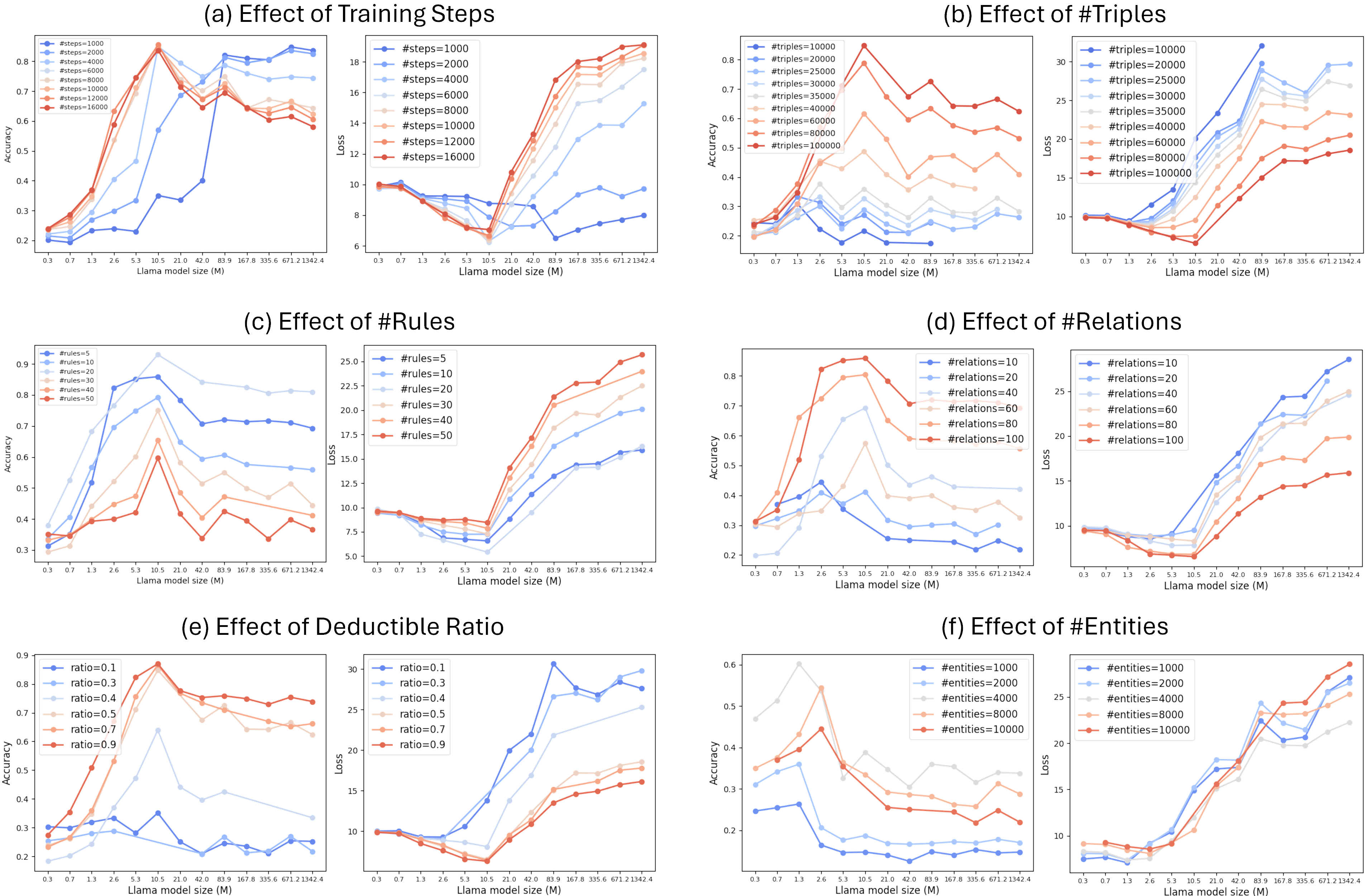
The research employs a synthetic implicit reasoning setup constructed from knowledge graphs, enabling the analysis of multi-hop reasoning without explicit chain-of-thought training. LMs are pretrained on triples representing incomplete knowledge graphs, then evaluated on completing missing edges.
Key findings include the identification of a U-shaped curve in reasoning loss as a function of model size, where not all larger models lead to improved reasoning. An optimal model size exists that balances memorization and reasoning, contradicting standard power-law scaling assumptions.
The empirical scaling law devised predicts optimal LM sizes capable of reasoning over approximately 0.008 bits of information per parameter, highlighting a stark contrast with the ability to memorize up to 2 bits per parameter reported by previous research.
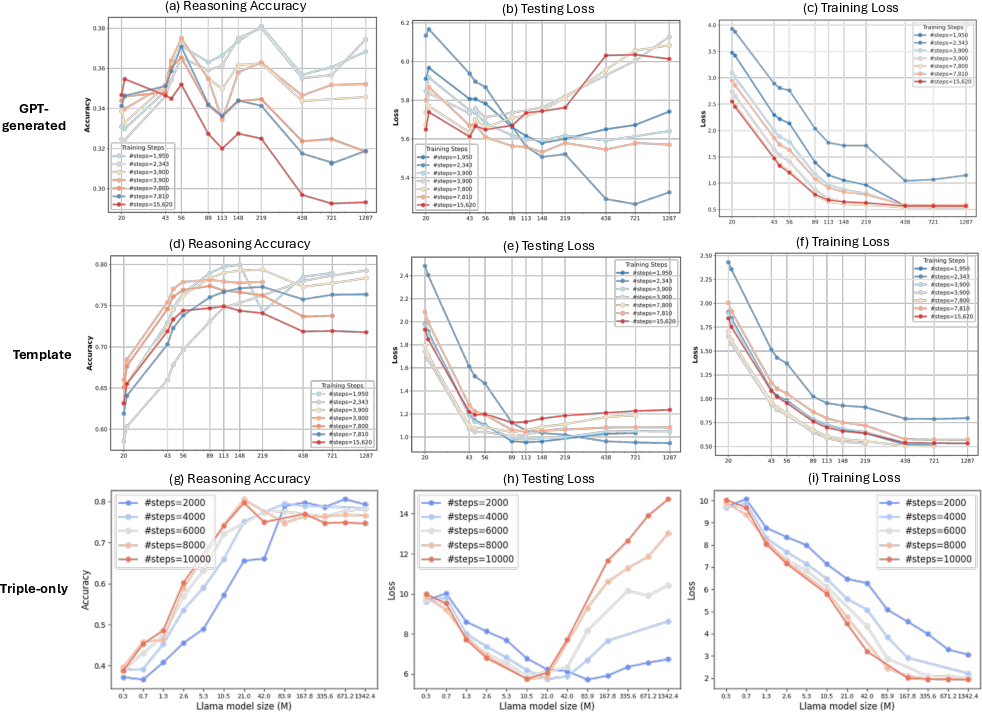
Figure 1: The multiple-choice accuracy/loss on unseen triples of different-sized LMs trained on a real-world knowledge graph FB15K-237.
Experimental Results
The study evaluates LMs on the FB15K-237 dataset, observing that as model size increases beyond a certain threshold, the reasoning performance deteriorates, despite continuous improvements in training loss. This suggests overfitting when models become excessively large relative to the task complexity.
For synthetic knowledge graphs, experiments vary key parameters such as the number of triples, entities, relations, and logical rules to delineate their impacts on optimal model size:
The scaling law derived is corroborated by these controlled experimental results, with the entropy of graph searches serving as a robust predictor for determining the optimal model size, evaluated against the FB15K-237 dataset.
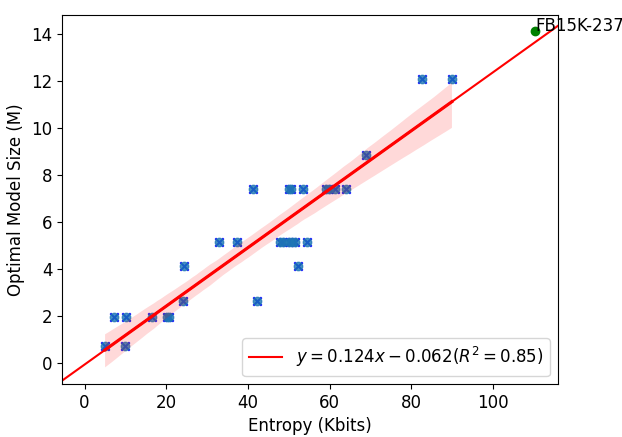
Figure 3: Optimal model size with lowest possible testing loss vs. graph search entropy.
Implications and Future Directions
The research's implications are profound for optimizing pretraining in LLMs, particularly in understanding the subtleties between memorization and reasoning capabilities. The finding of optimal model size suggests avenues for refining model architectures and pretraining routines, potentially guiding future AI deployments in resource-efficient ways.
Furthermore, the empirical scaling law offers a practical tool for predicting model requirements, utilizing graph-based entropy evaluations. This could assist in tailoring model training to specific knowledge graph complexities encountered in real-world applications.
Despite its insights, the study acknowledges limitations, notably the translation from synthetic to real-world data frameworks. Future work could focus on extending methodologies to diverse and larger corpuses, employing the proposed reasoning scaling law in broader AI contexts.
Conclusion
This paper identifies critical nuances in the scaling laws for LLMs concerning implicit reasoning capabilities pretraining. By establishing a detailed empirical scaling law tied to graph complexity, the research challenges traditional scaling assumptions, advocating for a nuanced approach to LM design and training.
The findings enrich our understanding of LM pretraining dynamics, with potential implications for enhancing the mechanistic reasoning of AI systems while highlighting the complexity inherent in optimizing AI models within computational and informational constraints.