- The paper's main contribution shows that test-time scaling significantly enhances crosslingual reasoning performance in multilingual benchmarks.
- It reveals that models with 3B+ parameters gain notable improvements, especially in STEM domains, when scaling inference compute is applied.
- The study also explores language-mixing and forcing, highlighting the need for better strategies in handling low-resource languages.
Crosslingual Reasoning through Test-Time Scaling
Introduction
The paper "Crosslingual Reasoning through Test-Time Scaling" investigates the crosslingual capabilities of reasoning LLMs (RLMs) primarily fine-tuned for English tasks, expanding the exploration to multilingual settings. It provides insights into how test-time inference scaling affects multilingual reasoning, offering practical strategies and highlighting the limitations of these models.
Crosslingual Test-Time Scaling
The paper examines the effectiveness of crosslingual test-time scaling, focusing on models like s1, which are fine-tuned on English reasoning data but evaluated on a multilingual benchmark (MGSM). The analysis shows that scaling inference compute enhances multilingual reasoning performance, surpassing even larger models that do not employ scaling.
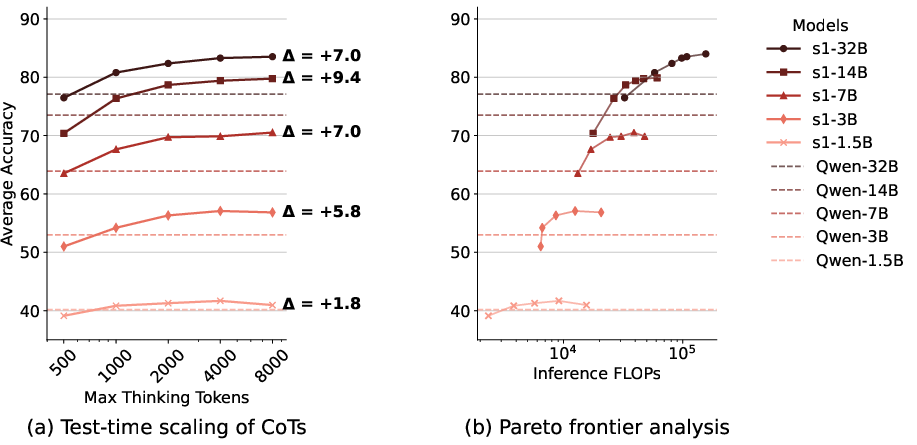
Figure 1: Crosslingual test-time scaling of s1 and Qwen models on the MGSM benchmark (excluding English) across different model sizes.
The researchers found that models with parameter sizes of 3B and above benefited significantly from test-time scaling, demonstrating superior performance on multilingual math reasoning tasks.
Language-Mixing Behaviors
The paper explores how English-centric RLMs exhibit language mixing in their reasoning outputs. It identifies a "quote-and-think" pattern where models quote non-English phrases and then process these within English reasoning, highlighting multilingual parsing capabilities.
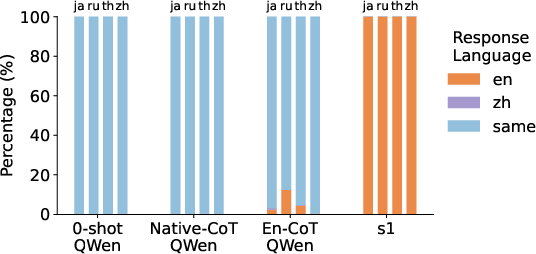
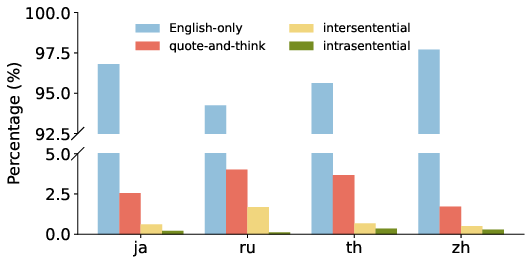
Figure 2: Proportion of dominant languages in models' entire responses when queried with multilingual math questions.
This behavior reflects the influence of English finetuning on multilingual model outputs, showing that models can maintain non-English phrase understanding while predominantly reasoning in English.
Language Forcing
The study investigates "language forcing," where models are compelled to reason in the language of the input query. Different strategies, such as prefix prompts and system instructions, are tested to control reasoning language.
The experiments reveal that while it is possible to enforce language compliance, reasoning in high-resource languages tends to yield better performance than low-resource ones. The results also underline challenges in maintaining task performance while forcing a specific language for reasoning.
Cross-Domain Generalization
The research evaluates cross-domain generalization, comparing the models' performance on STEM versus non-STEM domains. Test-time scaling proves beneficial for STEM domains but shows limited advantages for cultural reasoning tasks, indicating domain-specific generalization limits.
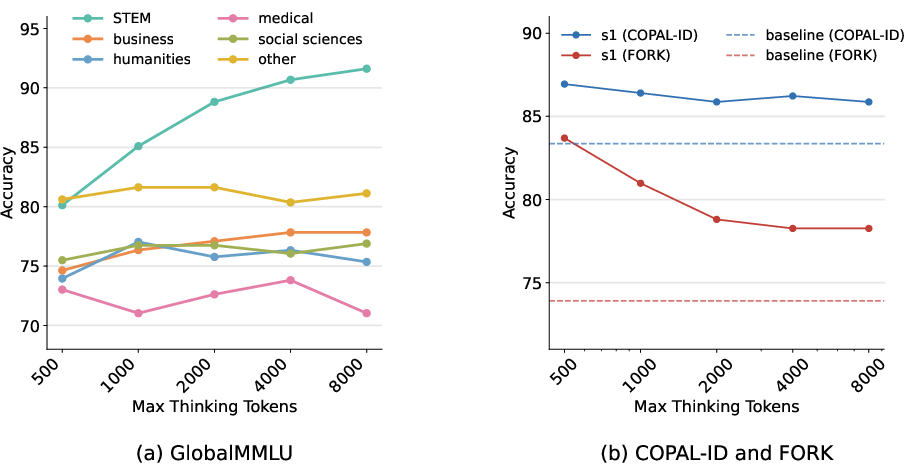
Figure 3: Effects of thinking time for s1 models on different domains of Global-MMLU benchmark and cultural commonsense benchmarks.
Conclusion
The paper concludes that while English-centric RLMs supplemented with test-time scaling excel in multilingual reasoning, especially in high-resource languages, there is a need for more robust handling of low-resource languages and non-STEM domains. Future directions include exploring data-efficient multilingual training data and developing equitable tokenization strategies to enhance reasoning across diverse languages.