- The paper shows that disentangling reasoning from language processing enhances multilingual performance via activation ablation and SVD across 10 LLMs.
- It employs language-specific subspace identification to remove linguistic noise, improving task performance on MGSM, XWinograd, and M-MMLU benchmarks.
- The study highlights that targeting middle layers for intervention optimizes reasoning accuracy while maintaining language fidelity in multilingual models.
When Less Language is More: Language-Reasoning Disentanglement Makes LLMs Better Multilingual Reasoners
Introduction
The paper "When Less Language is More: Language-Reasoning Disentanglement Makes LLMs Better Multilingual Reasoners" explores the hypothesis that reasoning and language processing in LLMs can be disentangled to enhance multilingual reasoning capability. Motivated by cognitive neuroscience insights, the research posits that LLMs, much like the human brain, can separate reasoning from language-specific processes. The authors validate this hypothesis through experiments that involve ablating language-specific components during inference time, thereby analyzing the impact on multilingual reasoning performance. The study spans 10 open-source LLMs and examines performance across 11 languages.
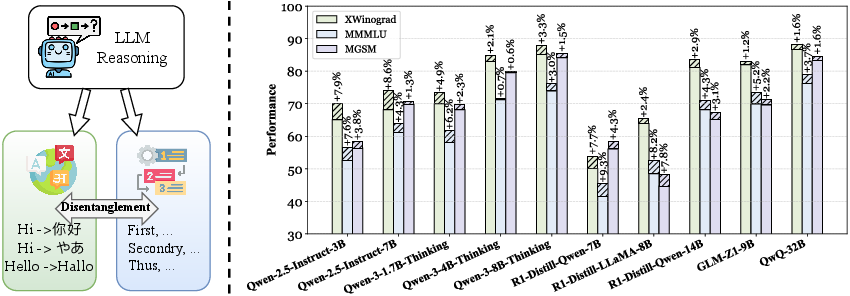
Figure 1: Overview of the hypothesis and empirical findings, showcasing the impact of disentangling reasoning from language components on multilingual model performance.
Methodology
Language-Specific Subspace Identification
The research outlines a method to identify language-specific subspaces in the LLMs’ hidden representations. This involves calculating mean representations for individual languages and employing Singular Value Decomposition (SVD) to decompose these representations into language-agnostic and language-specific subspaces. The decomposition allows for isolating components that encode linguistic variations across languages, forming the basis for subsequent interventions.
Activation Ablation
A crucial part of the method is the activation ablation process. By projecting out components along the identified language-specific subspace during inference, the approach aims to emphasize language-invariant reasoning capabilities. This is expressed mathematically as:
h^=h−λMs⊤Msh
where λ regulates the strength of language-specific component removal.
Empirical Results
The ablation method demonstrated consistent improvements in multilingual reasoning across various benchmarks, including mathematical problem solving (MGSM), commonsense inference (XWinograd), and knowledge-intensive tasks (M-MMLU). Notably, these improvements were evident across all tested models, despite differences in architecture and training paradigms.
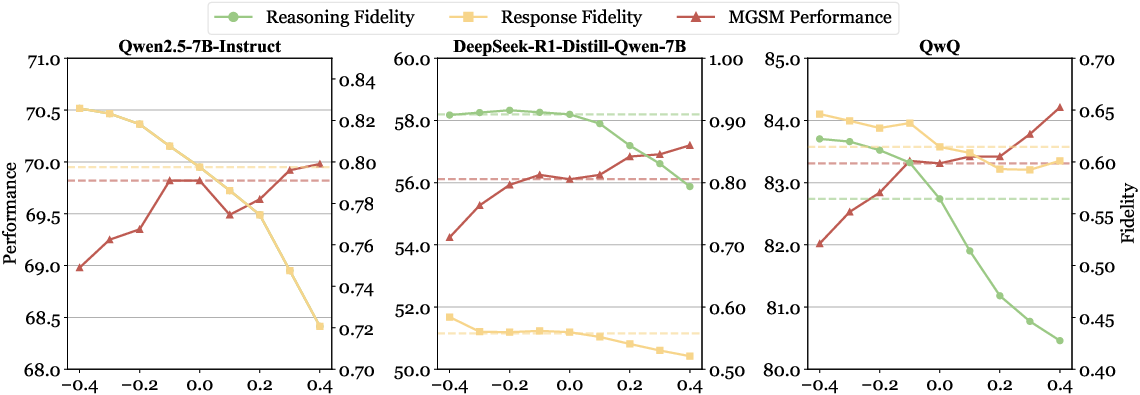
Figure 2: Effects of ablation strength on multilingual reasoning performance and output fidelity, highlighting the correlation between language-specific component removal and reasoning accuracy.
Layer-Wise Impact
The study further explores the layer-wise impact of languageâreasoning decoupling, revealing that middle layers are optimal for intervention as they afford improvements in reasoning performance without significantly compromising language fidelity.
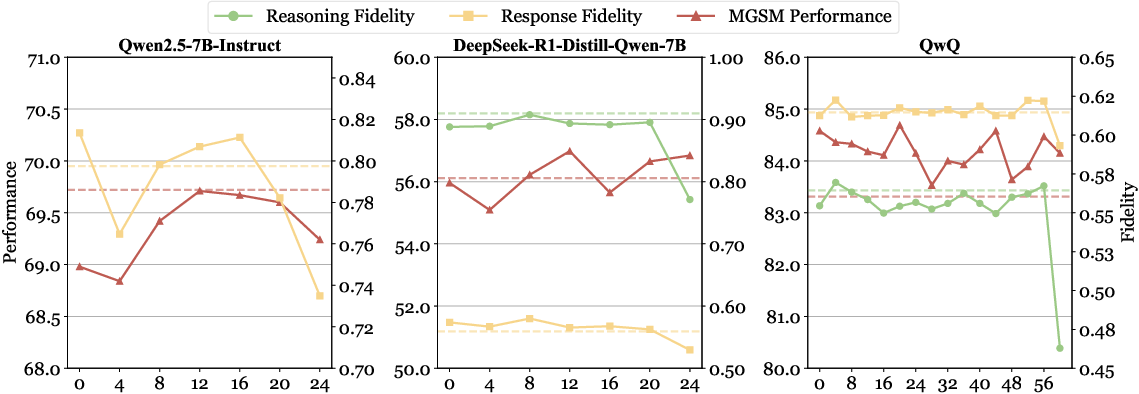
Figure 3: Layer-wise impact of languageâreasoning decoupling on MGSM accuracy and output fidelity, indicating effective decoupling at various model depths.
Discussion
The findings invite a reevaluation of multilingual LLM training and inference strategies, particularly advocating for mechanisms that explicitly separate reasoning from superficial linguistic features. This approach not only demonstrates reduced computational overhead compared to traditional supervised fine-tuning but also improves cross-lingual generalization through simplified, language-agnostic model spaces.
Conclusion
The research solidifies the notion that decoupling reasoning from language in LLMs is a viable strategy for enhancing multilingual performance. By reducing the dependency on language-specific signals, it opens pathways for models to leverage reasoning capabilities more effectively across diverse languages. The implications are substantial, encouraging the development of more equitable LLMs that maintain performance irrespective of the availability of language-specific resources. Future work may further investigate the integration of such disentanglement techniques during the LLM training phase, potentially augmenting the language-agnostic transfer of advanced cognitive functions to broader multilingual contexts.