- The paper demonstrates that incorporating linear probes into the loss function significantly improves predictive performance in world models.
- The research employs a deep supervision strategy using linear probes to decode true world features from latent states.
- The experimental results reveal enhanced training stability and reduced latent state drift, validated in a Flappy Bird setting.
Improving World Models using Deep Supervision with Linear Probes
This paper investigates a deep supervision strategy, leveraging linear probes to enhance the development of world models in predictive RNNs. The environment used for experimentation is based on the Flappy Bird game, where the agent observes LIDAR signals. The paper evaluates the impact of integrating a linear probe into the loss function, which aids in encoding true world features. This approach results in improved predictive performance and increased stability during training, providing valuable insights into the creation of sophisticated world models in AI.
Introduction to World Models and Methodology
Efficient world models enable AI agents to accurately predict environmental dynamics and adjust actions accordingly. The authors explore whether RNNs can inherently develop implicit world models through end-to-end training methods. The focus is on the inclusion of a linear probe to the network's loss function to encourage decoding of underlying world features. The paper evaluates the impact of this addition within a Flappy Bird environment enhanced with LIDAR input, investigating both the theoretical implications and practical results of this approach.
Experimental Environment and Network Architecture
The environment is structured around Flappy Bird, where the agent must navigate obstacles based on LIDAR input, represented as a 180-dimensional vector (Figure 1).
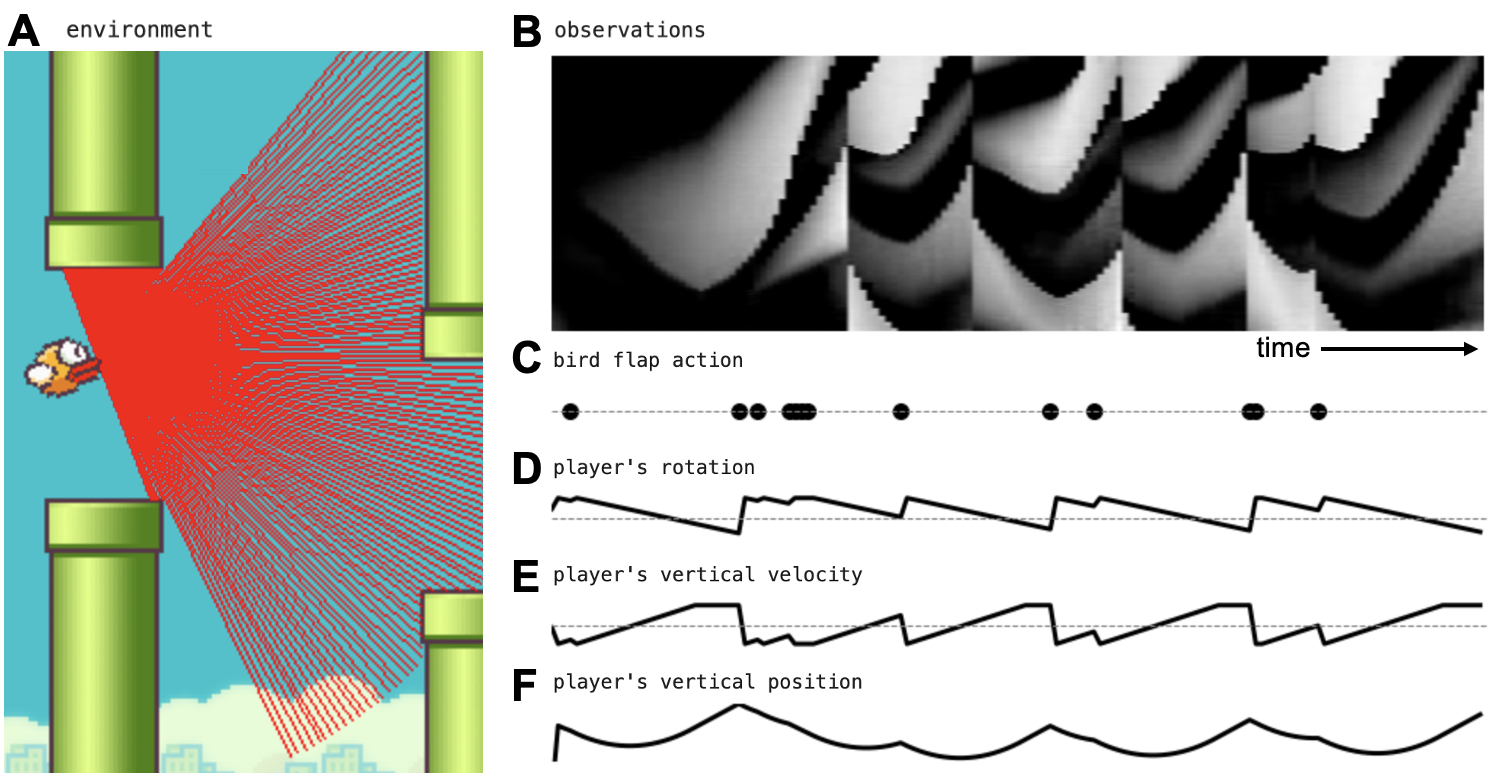
Figure 1: Flappy Bird environment with lidar. (A) The environment. (B) The agent only observes the lidar signal as a function of time. (C) The only available actions are no-op and flap. (D-F) The environment provides true variables of the world, such as the player's rotation angle, vertical velocity, and position.
The architecture involves compressing the observation space into an 8-dimensional latent vector via a vision autoencoder, followed by a Mixture Density Network-LSTM model to predict future latent observations and episode continuity (Figure 2).
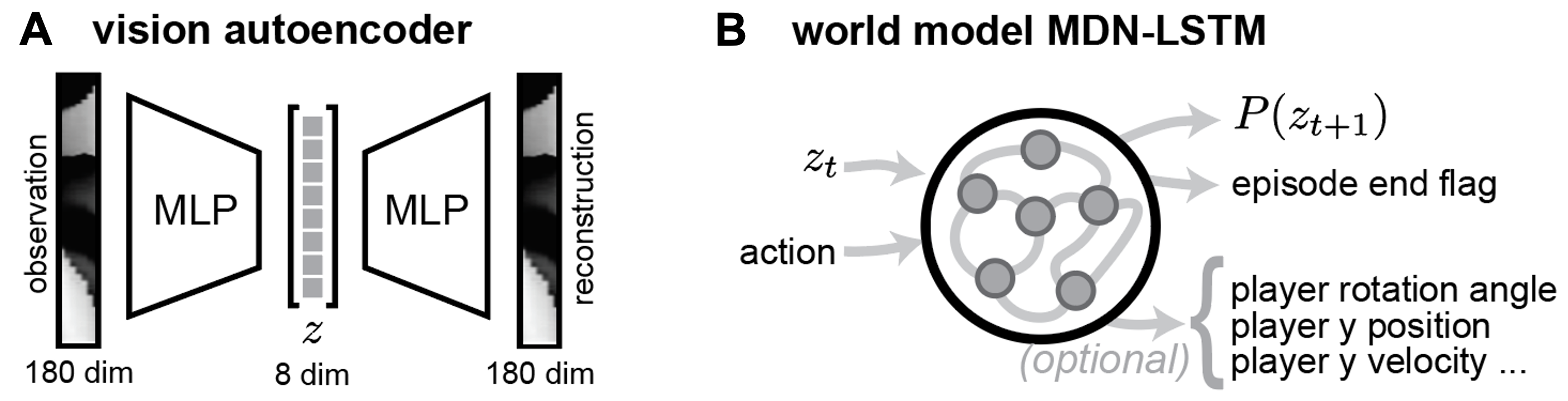
Figure 2: Network architecture and training setup. (A) The vision autoencoder compresses the 180-dimensional raw observations into an 8-dimensional latent space. (B) The world model MDN-LSTM takes the current latent observation vector and action as inputs, and predicts the distribution of the next latent vector and an episode end flag.
Results: Impact of Linear Probes
Predictive Loss Improvements
The inclusion of linear probes aids in reducing predictive loss across both training and test datasets. Notably, increasing the probe weight continued to enhance performance, suggesting a beneficial role without detriments to predictive quality (Figure 3).
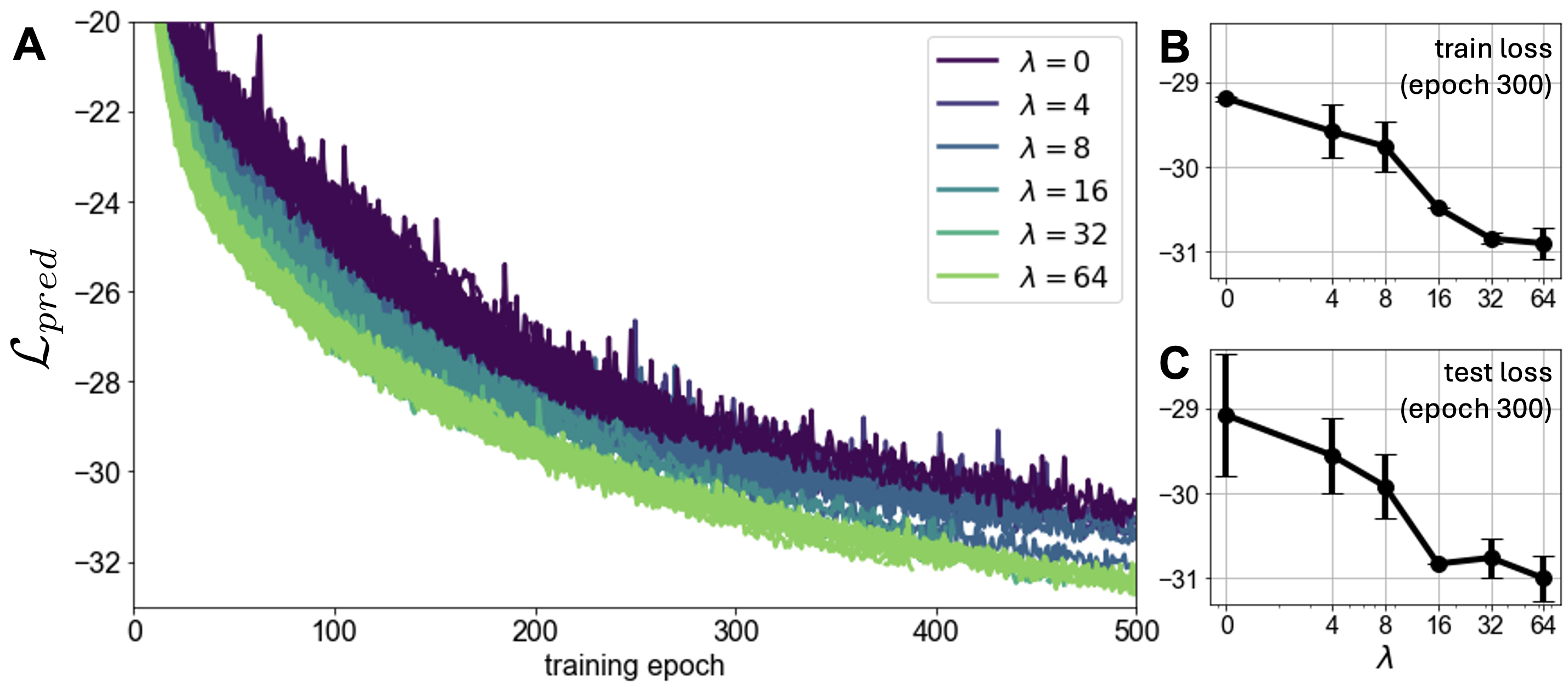
Figure 3: The effect of increasing the linear probe weight lambda on the original (next latent state prediction) loss. Both training (A, B) and test (C) predictive losses decrease as lambda increases.
Enhanced Decodability
Probes significantly improved the ability to decode world features from the network’s hidden states, even for features not directly included in the loss function. This underscores the comprehensive representation benefits stimulated by the probe addition (Figure 4).
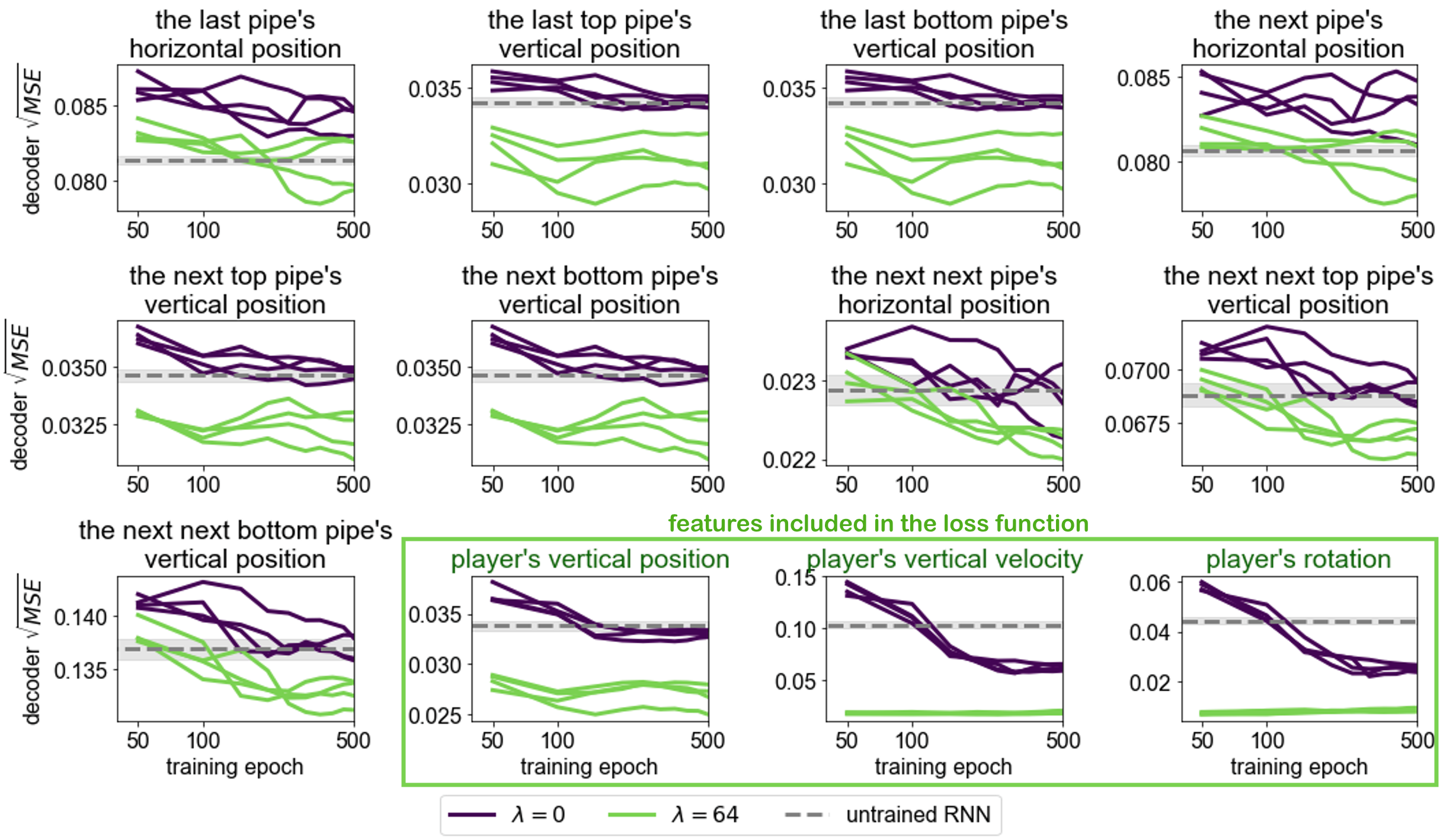
Figure 4: Decodability of world features from the network's hidden state for lambda=0 and lambda=64.
Reduced Distribution Drift
Training with probes reduced temporal drift in predicted latent states, crucially during high-variability phases such as navigating between pipes, showcasing stability gains facilitated by the probes (Figure 5).
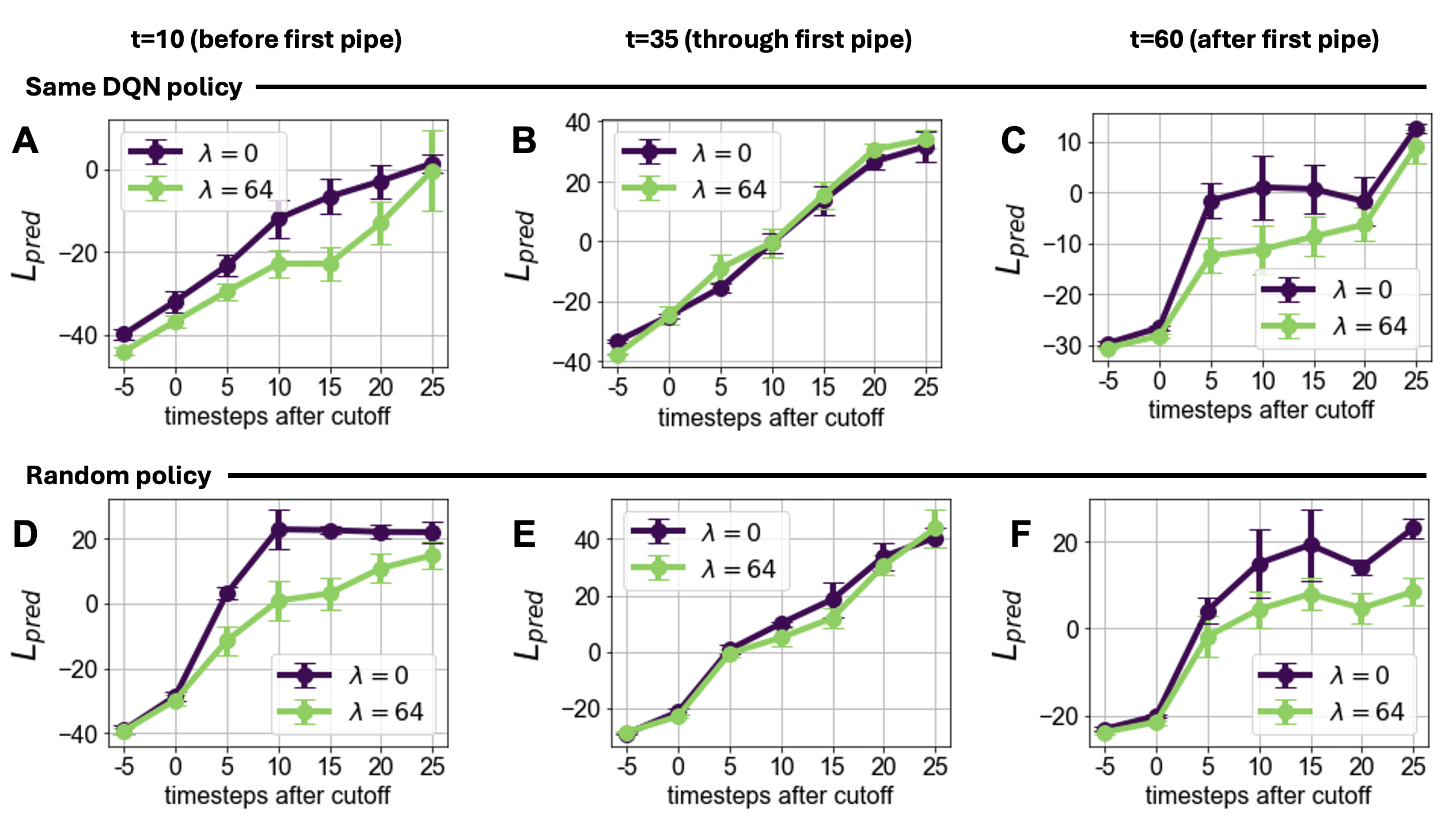
Figure 5: Distribution drift comparison. Networks with the linear probe (lambda = 64) exhibit reduced distribution drift.
Scaling and Stability
Training Curve Analysis
The predictive loss adheres to scaling laws, but the incorporation of probes smoothens and enhances these curves, indicating sustained performance benefits across network scales (Figures 6, 7).
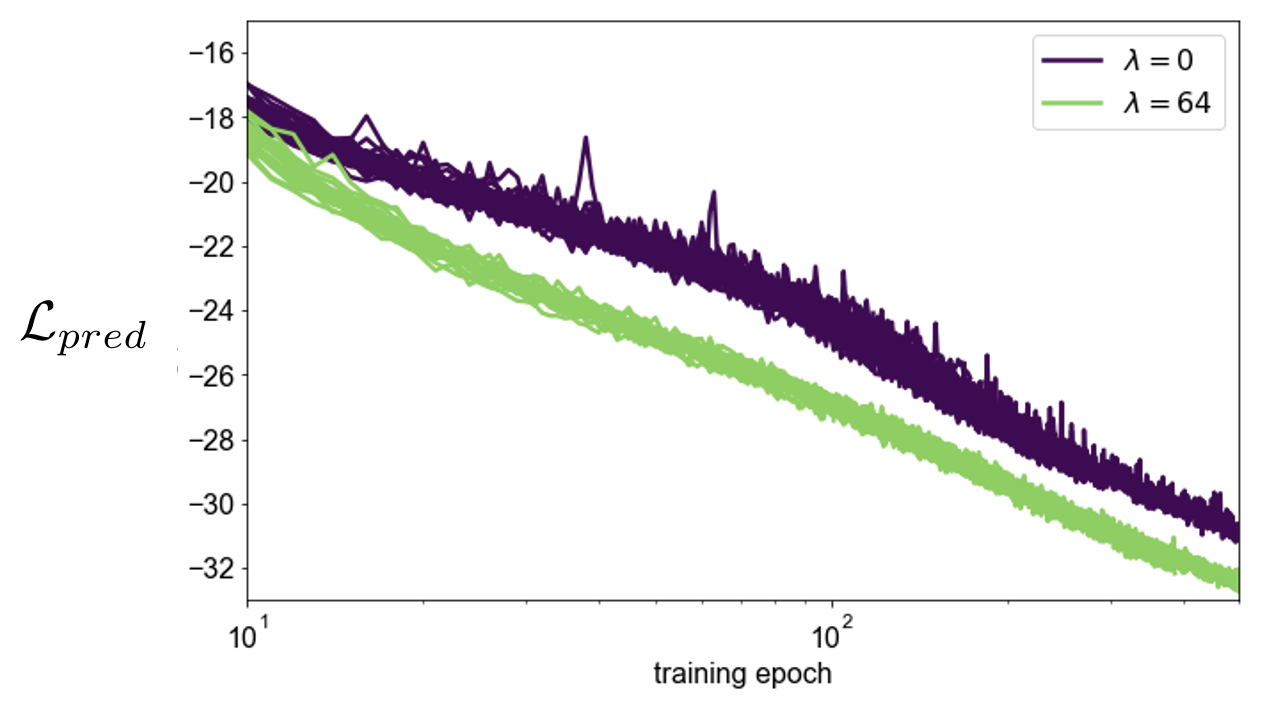
Figure 6: Scaling law of predictive loss with respect to training time.
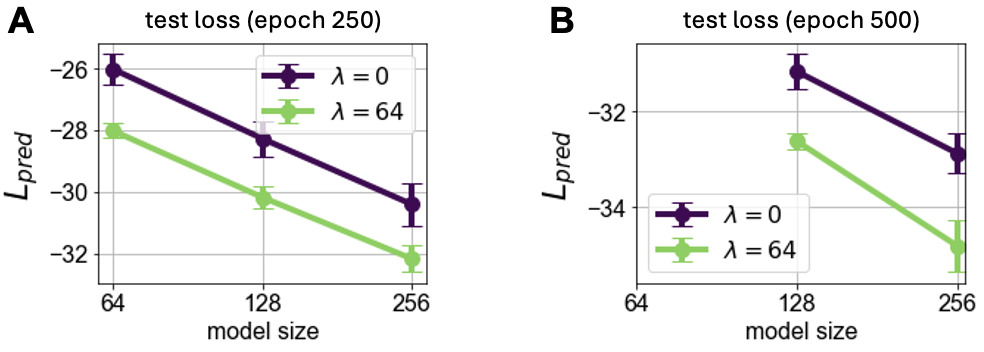
Figure 7: Scaling laws for model size, demonstrating better performance with the addition of probes.
Stability Improvements
The probe integration enhances training stability, reducing training divergence occurrence and managing exploding gradients more effectively, reinforcing the method's robustness (Figure 8).
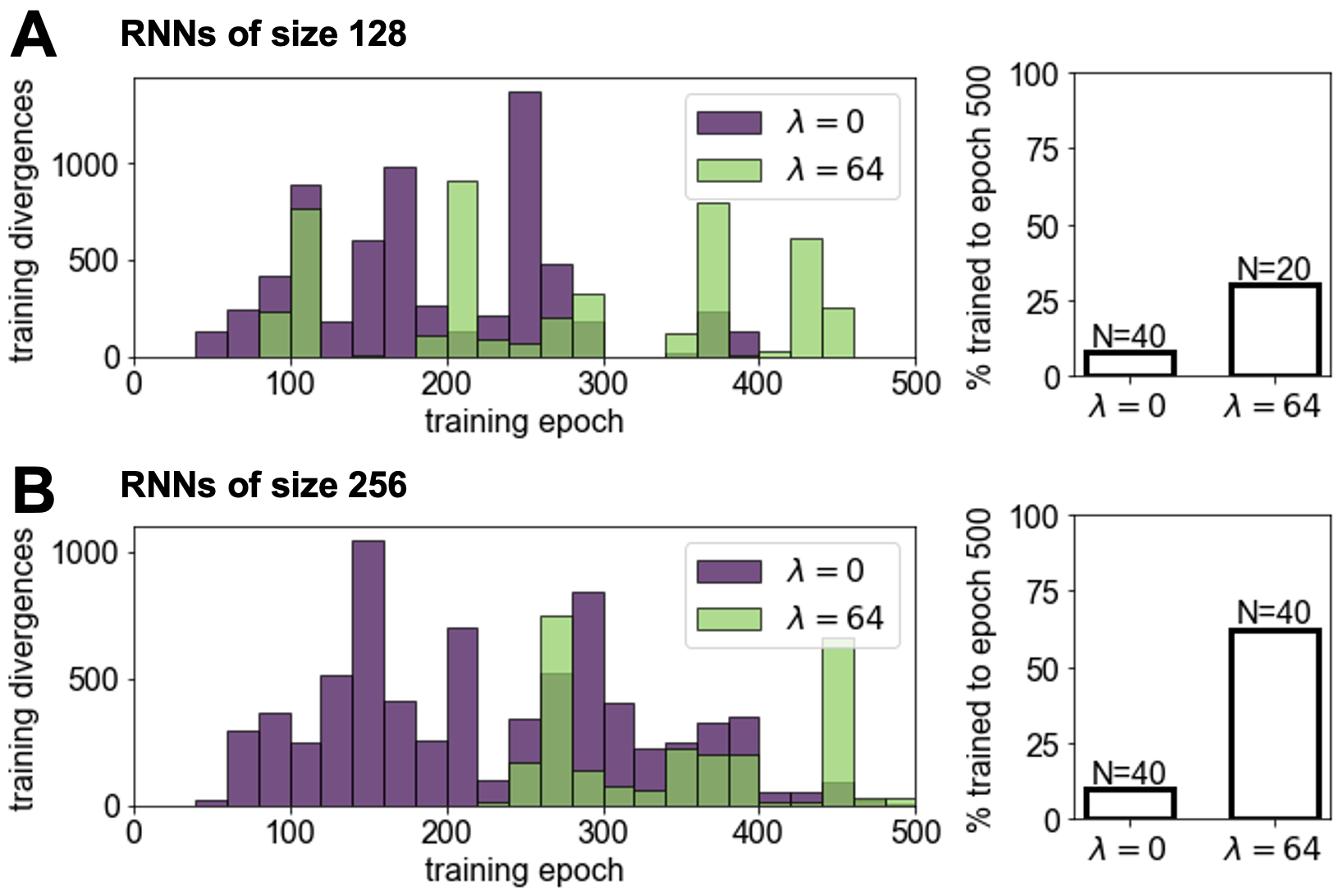
Figure 8: Training stability with and without the linear probe. Networks with probes are less likely to diverge.
Conclusion
This paper demonstrates that incorporating linear probe components to the training loss function enhances the development of world models in RNNs, improving both predictive accuracy and training robustness. The advantages of this approach are clear in compute-limited settings, facilitating better performance without necessitating larger models. This insight into the application of deep supervision techniques promises further advancements in efficient AI model training and deployment. The findings could significantly influence strategies for training AI in complex, partially observable environments, with implications reaching into robotics and beyond.