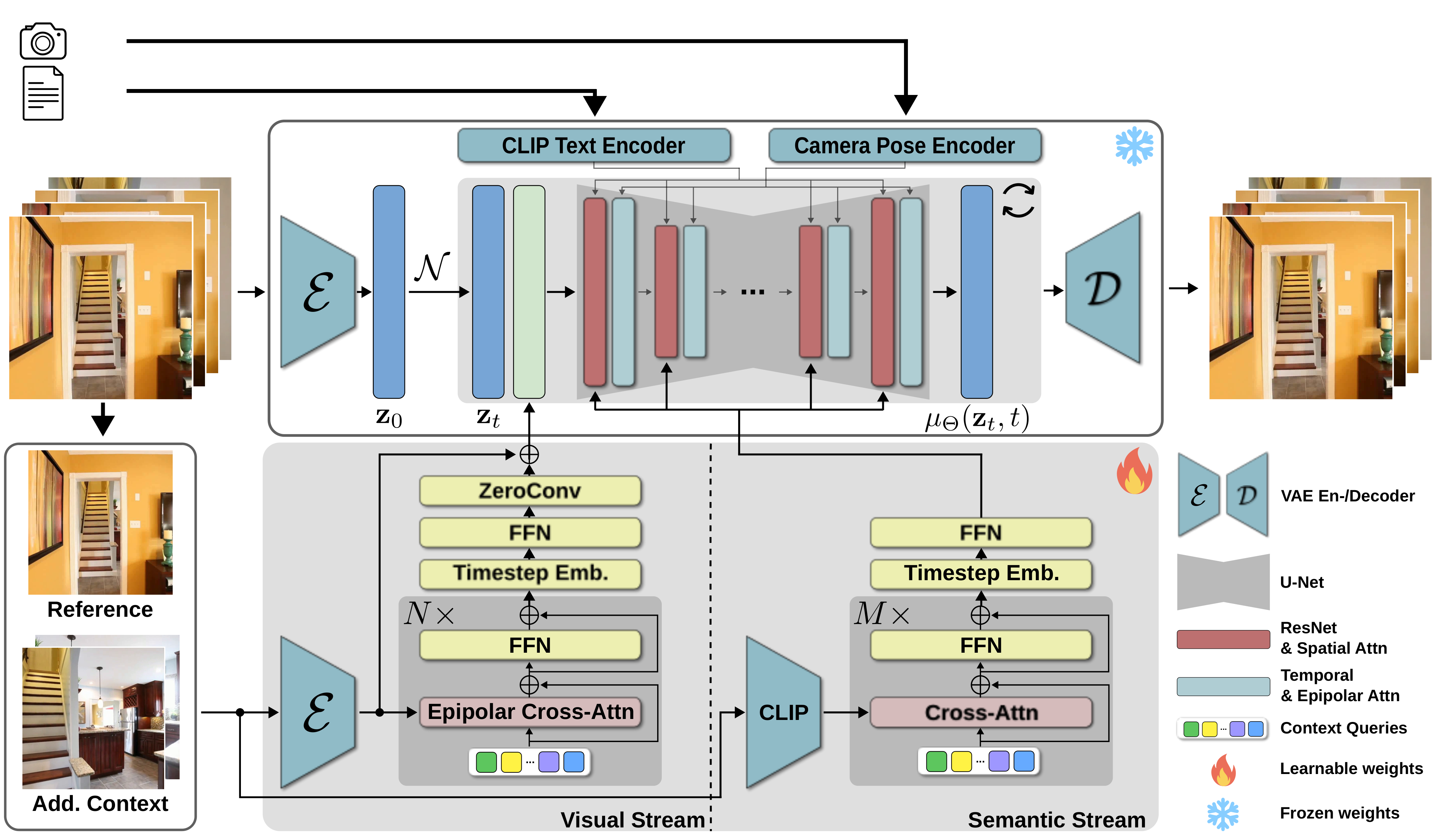
- The paper introduces a multi-view context-aware diffusion model that enhances 3D consistency and temporal stability by leveraging multiple frames and camera pose data.
- The paper integrates dual-stream encoding—combining semantic and 3D-aware visual features—with 3D epipolar cross-attention to enforce geometric consistency and reduce artifacts.
- The paper demonstrates superior performance with a 24.09% FVD improvement and increased SSIM, outperforming single-frame and NeRF-based approaches on benchmark datasets.
CamC2V: Context-aware Controllable Video Generation
Introduction
CamC2V introduces a multi-view context-aware diffusion model for camera-controllable video generation conditioned on multiple frames and camera trajectories. While prior image-to-video (I2V) and text-to-video (T2V) diffusion models yield high-quality generations, their reliance on a single reference frame limits visual fidelity and 3D consistency under complex or long-range camera motions. CamC2V directly addresses this deficiency by leveraging additional context frames and camera pose information, enabling more faithful and temporally stable synthesis for intricate scenarios.
Methodology
Context-Aware Conditioning Framework
CamC2V extends the DynamiCrafter architecture by incorporating a context-aware encoder that injects multiple context frames into the diffusion process. The context-aware encoder computes joint conditioning from a set of input views, their respective extrinsic camera parameters, and an optional global text prompt. This allows the model to reason over a richer scene representation instead of only extrapolating from a single frame.
The context-aware encoder integrates two complementary streams:
3D Epipolar Cross-Attention
A critical technical innovation in CamC2V is the incorporation of 3D epipolar geometry within the cross-attention operator. For each denoising timestep and spatial location, attention from context features is explicitly masked to only aggregate information from spatially consistent regions in the posed context frames, computed via epipolar line equations. This enforces physical consistency and suppresses artifacts when context frames cover different scene regions.
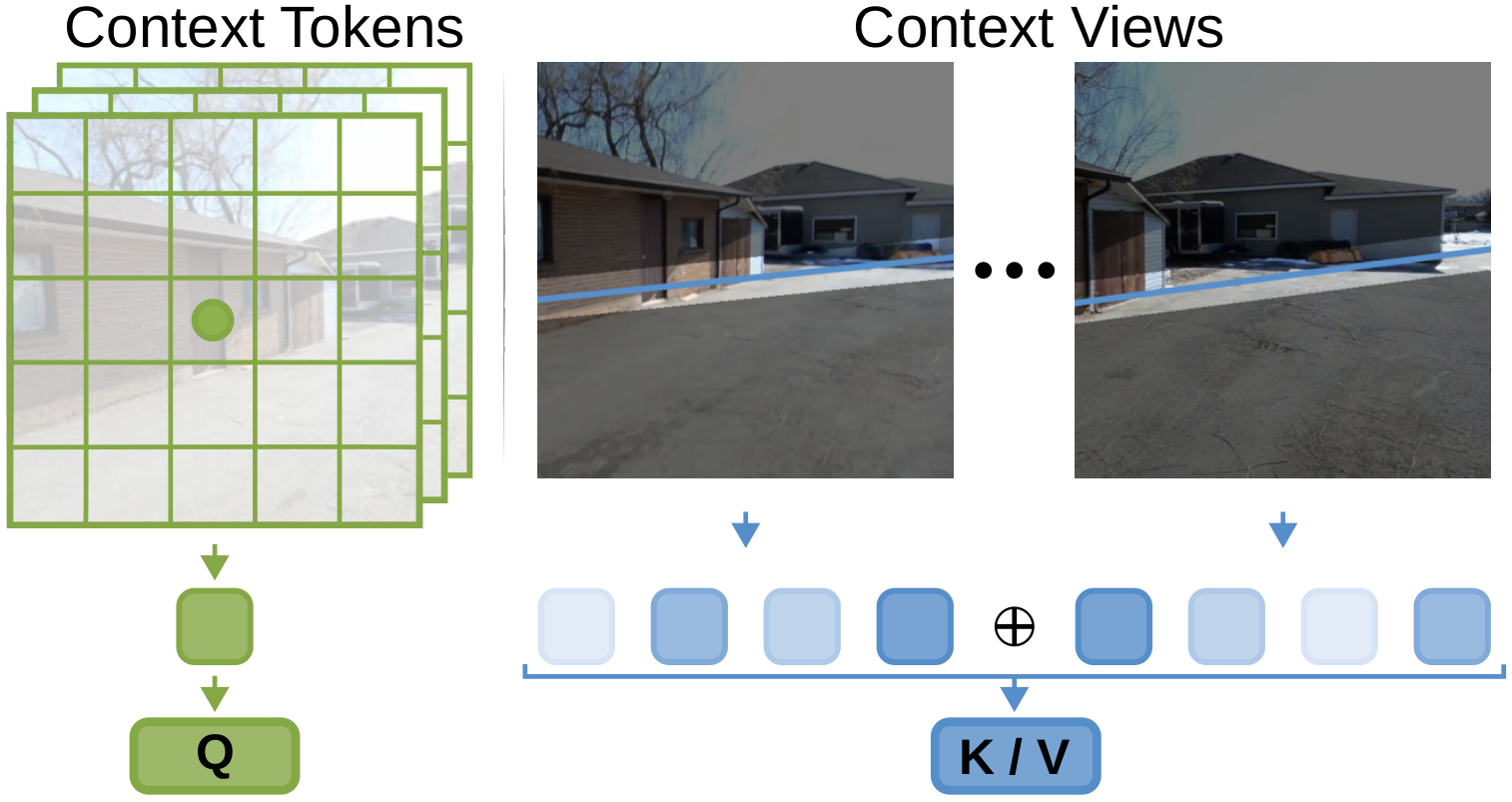
Figure 2: Epipolar cross-attention restricts query-key mappings to regions consistent with 3D geometry.
Temporal Awareness
Unlike pixel-wise conditioning in previous methods, CamC2V encodes the intended target frame index as a sinusoidal embedding, concatenated to both semantic and visual streams. This temporal embedding improves alignment between context views and the generated frame at each timestep.
Loss Rebalancing
To prioritize high-quality synthesis at later timesteps—where single-frame conditioning is typically insufficient—CamC2V employs log-weighted L2 denoising loss along the temporal axis, focusing the model’s capacity on challenging frames as the sequence progresses.
Experimental Results
On RealEstate10K, CamC2V achieves 24.09% FVD and MSE improvements over established camera-controllable baselines such as MotionCtrl, CameraCtrl, and CamI2V. CamC2V consistently yields lower per-frame error rates and higher SSIM at later timesteps, confirming greater temporal stability and context-aware fidelity.
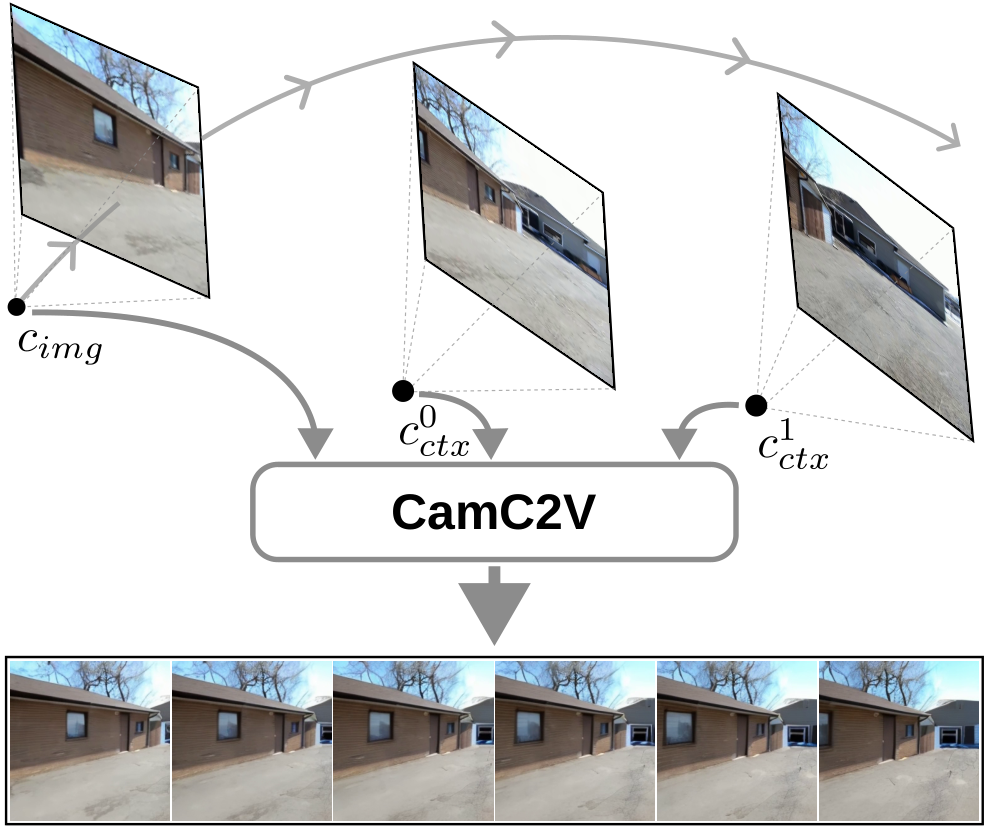
Figure 3: CamC2V leverages multiple views to resolve visual ambiguities that degrade quality in single-frame models.








Figure 4: Qualitative comparison showing the superior preservation of layout, geometry, and object details in CamC2V over benchmarks.
Framewise analyses illustrate that degradation in visual quality over time is greatly reduced with CamC2V; the gap between ground truth and generated sequences narrows, especially in frames extrapolated far from the initial reference.


Figure 5: Sampling strategy affects context usage; the model selectively aggregates from informative context while rejecting unrelated regions.
Camera Trajectory Consistency
Using GLOMAP for pose estimation, CamC2V exhibits notably lower rotational, translational, and composite camera motion errors compared to the baselines. These results indicate that the richer context and explicit 3D reasoning enhance not only image quality but motion accuracy, a strong indicator of 3D consistency.
Ablation Studies
- Dual-Stream Encoder: Isolated semantic or visual contexts yield suboptimal performance; their combination is necessary for robust scene and detail encoding.
- Epipolar Masking: Removing geometric constraints degrades quality and causes erroneous context aggregation.
- Temporal Embedding: Omission leads to errors in timestep-specific context retrieval.
- Sampling Strategy: The network robustly rejects context from irrelevant frames (furthest sampling), while close contextual frames boost quality marginally—demonstrating the model’s ability to balance context relevance.
Comparison to Novel View Synthesis
Compared to FrugalNeRF, a state-of-the-art sparse view NeRF-based model, CamC2V achieves higher SSIM and PSNR with considerably reduced computational cost and applicability outside the narrow success regimes of SfM-driven NeRF pipelines.








Figure 6: Generated and reconstructed frames for novel view synthesis—CamC2V yields sharper, artifact-free renderings.
Practical and Theoretical Implications
This work establishes that multi-frame, context-aware conditioning with explicit camera control and 3D geometry injection yields substantial advances for controllable video diffusion. CamC2V’s generalization to arbitrary context sets and camera trajectories broadens the applicability for virtual content creation, scene animation, and data-driven 3D reconstructions.
Further, the design paradigm of explicit geometric attention and temporal embeddings is extensible, providing valuable guidance for scaling conditional generative models to more complex conditional structures (e.g., non-rigid or multi-object scenarios). The robust performance without test-time optimization, as required by NeRF, highlights diffusion as a viable backbone for practical, interactive scene synthesis.
Conclusion
CamC2V demonstrates that high-fidelity, camera-controllable video generation can be achieved via multi-frame context-aware conditioning with 3D geometric reasoning. The approach outperforms single-view and non-geometry-aware baselines, setting a state-of-the-art benchmark for future research in controllable, 3D-consistent video synthesis. Future directions include scaling context to more unconstrained dynamic scenarios, integrating learned camera priors, and generalizing temporal and geometric conditioning for interactive scene editing (2504.06022).