SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Abstract: We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces SpaceTimePilot, an AI model that can “re-film” a video by controlling two things separately:
- where the camera is (space), and
- when events happen (time).
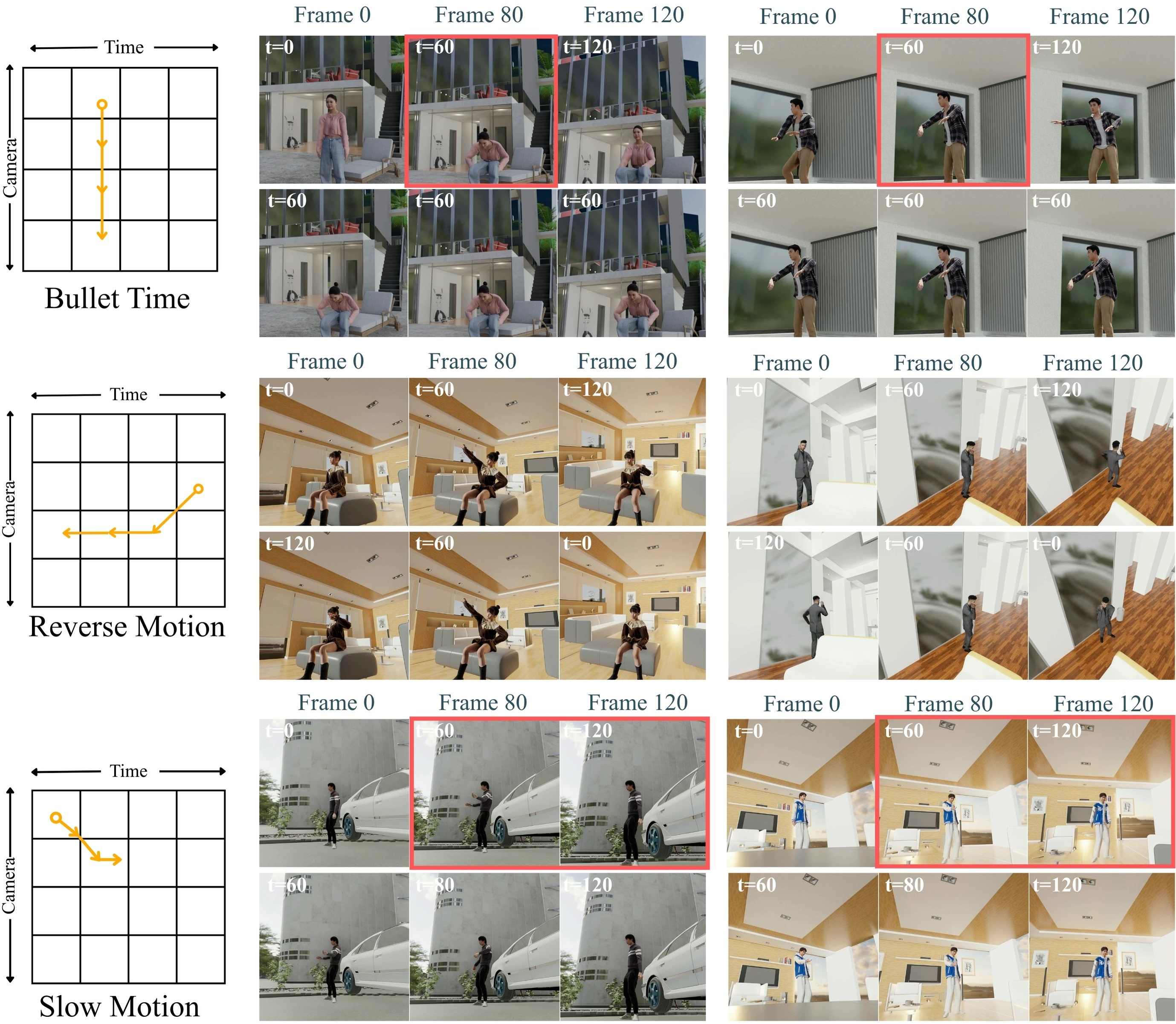
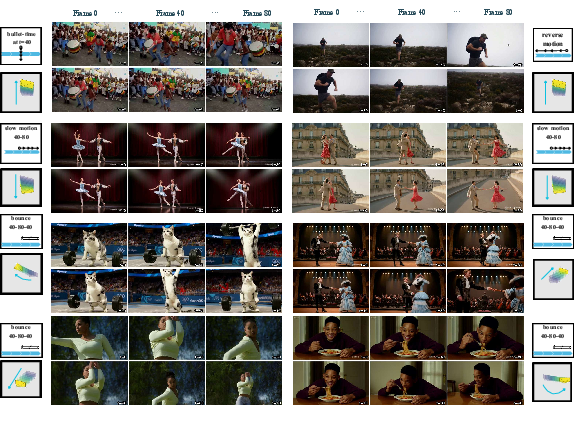
Given just one normal video, SpaceTimePilot can create a new video that shows the same scene from new camera angles and with different timing, like slow motion, reverse, or “bullet time” (the effect from The Matrix where time freezes while the camera moves around the scene).
What questions does it try to answer?
In simple terms, the paper asks:
- Can we make a model that lets you move the camera freely around a video scene while also changing how time flows, without mixing the two up?
- Can we do this using only a single input video (instead of many cameras or heavy 3D reconstruction)?
- How can we train a model to understand time control when there aren’t big public datasets that show the same action at many different speeds and directions?
How it works (in everyday language)
Think of a video as a play happening on a stage:
- “Space” is where you put the camera around the stage.
- “Time” is how the actors move and when events happen.
Most previous methods either:
- focus on moving the camera but keep time normal, or
- rebuild the whole 3D scene (which can be slow and still imperfect), or
- only produce a few still frames instead of smooth videos.
SpaceTimePilot does both camera control and time control together by treating them as separate “dials” you can turn independently. Here’s how:
Teaching the model about “animation time”
The model uses a special “animation time” signal, which is like a separate timeline that tells the model exactly which moment of the original action to show. This separates:
- the camera path (where you look), from
- the action timing (what moment of the action you’re seeing).
Under the hood:
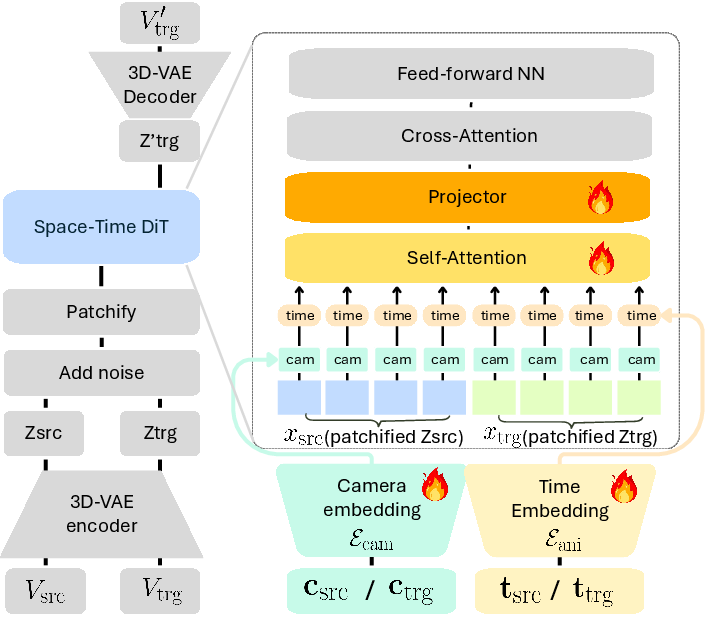
- The model is a video diffusion model (you can think of diffusion as starting with noisy “static” and learning to clean it step by step to form a video).
- It adds two kinds of instructions to the model’s “thinking process”:
- camera instructions (where to place the camera each frame),
- time instructions (which part of the original action to show each frame).
- The time instructions are encoded using smooth waves (sinusoidal signals) and then “compressed” along the timeline using a small 1D convolution network. You can think of this like turning a detailed schedule into a neat, easy-to-follow plan that still keeps all the important timing.
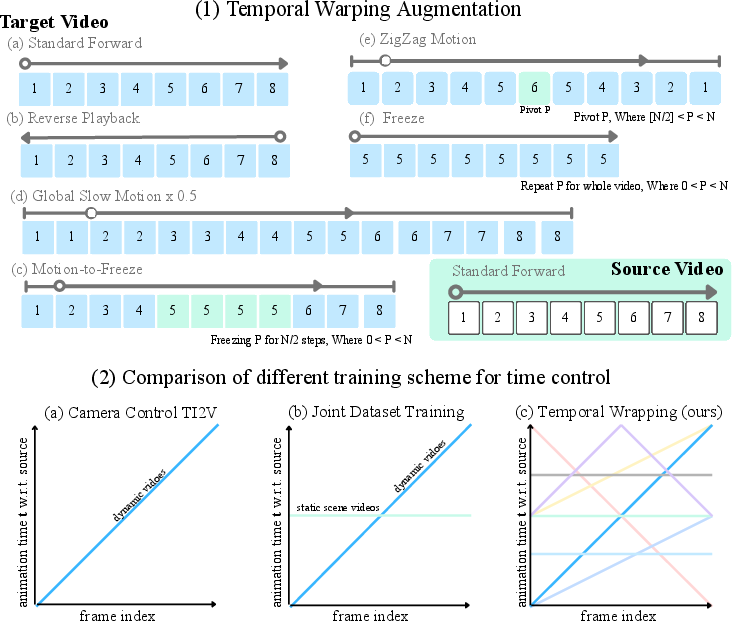
A training trick: time-warped videos
There isn’t a ready-made dataset of the same scene played at many speeds and directions. So the authors created one from existing multi-view video datasets by “time warping” the target video during training:
- reverse playback (backwards),
- slow motion,
- freeze frames,
- speed up,
- zigzag (forward-then-back-then-forward).
This teaches the model what it means to “change time” without needing special paired data filmed in different time styles.
Analogy: It’s like training a dancer to perform the same routine backwards, slower, or with pauses—without needing a separate teacher for each style.
A new synthetic dataset: Cam×Time
To get very precise control, the authors built a big synthetic dataset called Cam×Time. Picture a chessboard:
- one axis is camera viewpoints along a path,
- the other axis is moments in the animation.
They render every square of this grid. That means the model sees the same action from many camera angles and at many time points. This dense “space–time coverage” helps the model truly learn to keep space and time separate.
What’s inside:
- 180,000 videos,
- 100 scenes,
- 500 animations,
- multiple camera paths,
- dense coverage across both camera positions and time.
Better camera control from the first frame
Some earlier models assume the first frame is the same in source and target videos, which limits where the camera can start. SpaceTimePilot fixes this by feeding the model both:
- the source video’s camera path, and
- the desired target camera path.
This gives it context to start the new video from any angle immediately, and then follow the new camera path smoothly.
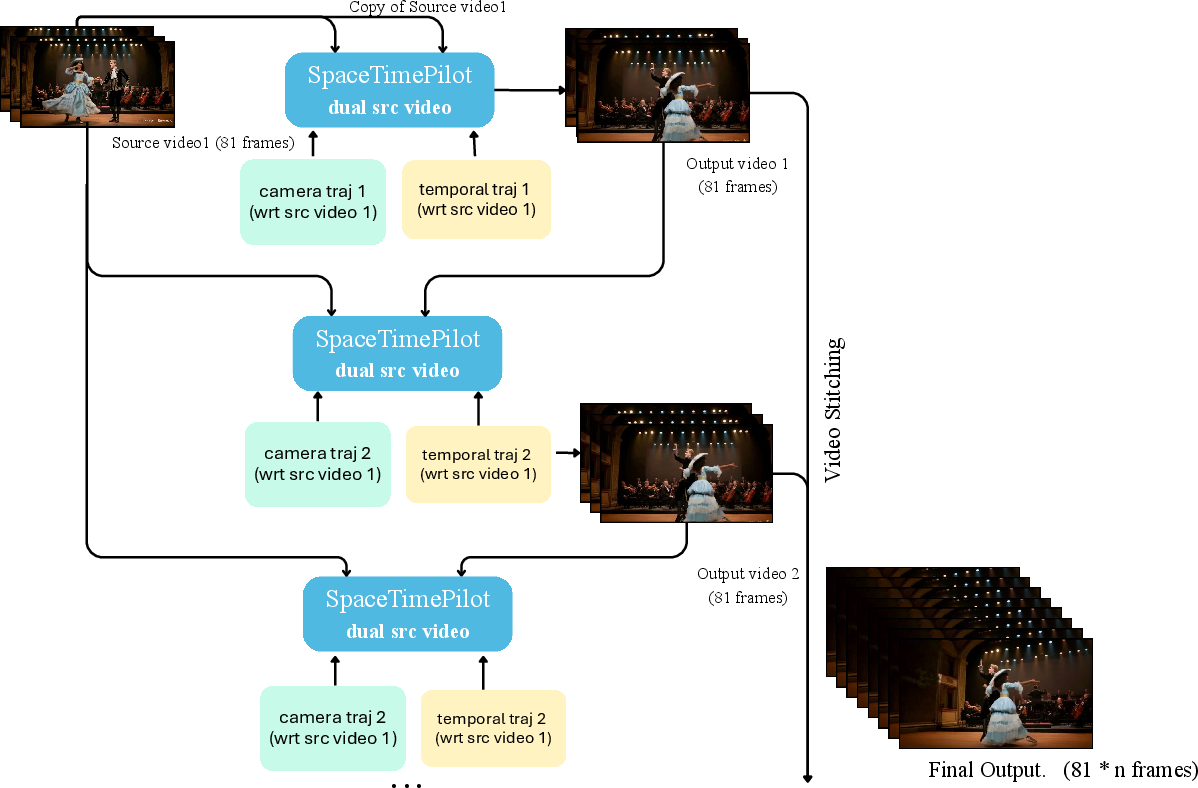
Longer videos through chaining
To make longer videos, the model can generate a segment, then use that result as extra context to keep going. This helps with effects like continuing a long bullet-time shot in multiple parts while staying consistent.
What did they find, and why is it important?
Here’s what their tests showed:
- Clear separation of space and time: The model can move the camera and retime the action independently without the two getting mixed up.
- Strong time control: It handles reverse playback, slow motion, freeze effects, and bullet-time better than adapted baselines that weren’t designed for time control.
- Precise camera control: It follows requested camera paths more accurately, including starting from an arbitrary angle in the very first frame.
- Good visual quality: The videos look as good as or better than competing methods on standard visual benchmarks.
Why this matters:
- It’s the first time a single diffusion model enables smooth, continuous control over both camera and time from just one input video.
- It unlocks creative tools—like re-framing action shots, making movie-like effects, and re-timing motion—without needing expensive multi-camera setups or full 3D reconstruction.
What could this lead to?
SpaceTimePilot opens up practical and fun possibilities:
- Video editing: Reangle old clips, add slow motion or reverse effects, or create bullet-time shots after filming.
- Sports and education: Replay moments from new angles and speeds to better understand movement.
- Filmmaking and content creation: Prototype cinematic shots quickly without reshoots.
- VR/AR and interactive media: Let users freely explore a scene in both space and time.
- Research: The Cam×Time dataset and the idea of “animation time” embeddings may inspire future 4D (3D + time) generative models with even finer control.
In short, the paper shows how to give users a “space dial” and a “time dial” for any video—making it possible to explore scenes like a virtual director who can both fly the camera and bend time.
Knowledge Gaps
Below is a concrete list of knowledge gaps, limitations, and open questions that remain unresolved and could guide future work:
- Real-world temporal control validation: The paper’s quantitative time-control evaluation relies on synthetic ground-truth from the proposed Cam×Time dataset; there is no quantitative assessment of retiming accuracy on real videos (e.g., proxy metrics, human studies), leaving robustness in unconstrained settings unverified.
- Dependence on synthetic supervision: Disentanglement quality and precise temporal control hinge on the synthetic Cam×Time dataset; it remains unclear how well the learned controls generalize to real, complex scene dynamics, lighting, material properties, motion blur, and rolling-shutter artifacts.
- Dataset coverage and bias: The Cam×Time dataset’s animation types, scenes, and camera paths may not reflect the diversity of real dynamic scenes (e.g., multi-actor interactions, occlusions, topological changes, fluid/cloth); a systematic analysis of coverage and resulting biases is missing.
- Temporal warping realism: The temporal-warping augmentations (reverse, slow, freeze, zigzag) provide supervision but may generate physically implausible motion sequences for many real-world scenes; the impact of such non-physical supervision on downstream generation fidelity is unquantified.
- Formal disentanglement metrics: Beyond qualitative results and task-specific metrics, the work does not quantify space–time disentanglement (e.g., mutual-information estimates, causal intervention tests, or counterfactual consistency scores between camera and time controls).
- Camera intrinsics and lens effects: Conditioning and evaluation focus on extrinsics; the model’s handling of intrinsics (FOV, distortion, rolling shutter) is unspecified, limiting applicability to diverse cameras and wide-angle/fisheye lenses.
- Scale ambiguity and metric consistency: Camera-control evaluation explicitly notes scale ambiguity; the method does not enforce metric consistency (absolute scale/depth), leaving open how to achieve metrically accurate 4D reconstructions in generative rendering.
- Robustness to inaccurate source camera estimates: The approach relies on pretrained pose estimators for c_src; there is no analysis of sensitivity to pose-estimation errors and how such errors propagate to camera/time control during generation.
- Handling multi-entity asynchronous motion: The time signal is global per frame; in scenes with multiple objects moving at different rates, there is no mechanism for object-specific time control or per-entity retiming.
- Motion synthesis beyond retiming: The method re-renders the source dynamics under new camera/time schedules; it is unclear whether it can synthesize truly novel temporal behaviors (e.g., physically plausible slow motion with motion interpolation, future forecasting) beyond re-indexing/re-mapping observed motion.
- Occlusion and unseen-surface reliability: Bullet-time and large-baseline camera moves require inferring unseen surfaces; the work lacks quantitative evaluation of multi-view geometric consistency (e.g., cross-view reprojection error or multi-view perceptual consistency) under aggressive viewpoint changes.
- Long-horizon stability and error accumulation: Autoregressive segment chaining is proposed for longer sequences, but drift, temporal coherence, and cumulative error across segments are not measured or bounded.
- Temporal granularity and variable frame rates: The time embedding compresses F=81 frames to F′=21 latent frames via convolutions; the effect of different latent lengths, variable frame rates, or dynamic-duration control (e.g., minute-long videos) is not explored.
- Computational efficiency and scalability: Training and inference costs, memory use for dual conditioning, and runtime under long trajectories are not reported; feasibility for interactive or real-time applications remains unknown.
- Integration with geometry cues: The method is geometry-free; whether combining light-weight geometry (depth/flow/point clouds) could improve occlusion handling, consistency, or extrapolation is left unexplored.
- Failure mode characterization: The paper lacks a systematic analysis of failure cases (e.g., fast motion, heavy occlusions, specular/transparent materials, extreme lighting changes, handheld camera shake), limiting actionable guidance for improving robustness.
- Camera-control precision at the first frame: While improved first-frame control is reported, the conditions under which initial-pose errors persist (e.g., large initial view changes, poor source pose recovery) are not characterized.
- Multi-modal control coupling: The approach does not consider audio or text conditioning; open questions include synchronizing time control to audio (e.g., musical beats) or jointly controlling camera/time with semantic prompts.
- Content editing under time control: The method preserves the source dynamics; there is no pathway to edit motion semantics (e.g., change gait speed or choreography) while preserving identity and appearance, nor constraints to maintain physical plausibility.
- Generalization across cameras and datasets: Evaluation on real videos uses OpenVideoHD and SpatialTracker-v2; assessing generalization across diverse datasets and camera capture rigs (mobile, action cams, drones) remains incomplete.
- Reliability of evaluation pipelines: Camera-control accuracy depends on third-party trackers (SpatialTracker-v2, DUSt3R); the impact of tracker failures or bias on reported metrics is not quantified, raising questions about evaluation reliability.
- Training objectives and theory: The choice of sinusoidal time embedding plus 1D conv is empirically justified; theoretical grounding (e.g., continuous-time conditioning, ODE-based temporal priors, disentanglement regularizers) and alternative formulations are not examined.
- User control interfaces and constraints: There is no discussion of how users specify feasible camera/time trajectories, nor mechanisms to reject or adapt physically implausible controls (e.g., sudden jumps, impossible accelerations).
- Benchmarking standards: Although part of Cam×Time is reserved for testing, a public, standardized benchmark and protocol for camera–time controllable generation (including real-world components) is missing; reproducibility (code, models, dataset release timelines) is unspecified.
Glossary
- 3D Variational Auto-Encoder (VAE): A neural network that compresses and reconstructs videos in a 3D latent space for efficient generative modeling. "consisting of a 3D Variational Auto-Encoder (VAE) for latent compression"
- 4D reconstruction: Building a time-varying 3D scene (3D geometry plus time) from 2D video observations. "perform 4D reconstruction"
- Autoregressive video generation: Generating videos in segments where each segment conditions on previous outputs to extend sequences. "we adopt a simple autoregressive video generation strategy"
- Bullet-time: A visual effect that freezes or greatly slows motion while the camera moves around the subject. "supporting bullet-time, slow-motion, reverse playback, and mixed spaceâtime trajectories"
- Camera conditioning: Injecting camera parameters into a generative model to control viewpoint during video synthesis. "an improved camera-conditioning mechanism"
- Camera extrinsic parameters: The rotation and translation that define a camera’s position and orientation relative to a world or reference frame. "represents the camera extrinsic parameters (rotation and translation) at frame f"
- Camera re-posing: Changing the camera viewpoint during generation without relying on per-frame depth reprojection. "enable camera re-posing with more lightweight point cloud representations"
- ControlNet: A neural network module used to provide structured conditioning (e.g., control signals) to diffusion models. "improves efficiency via a lightweight ControlNet framework"
- DiT (Denoising Transformer): A Transformer-based denoising network used in diffusion models to iteratively refine latent representations. "a Transformer-based denoising model (DiT) operating over multi-modal tokens"
- Diffusion model: A generative model that learns to synthesize data by iteratively denoising from noise according to learned distributions. "a video diffusion model that disentangles space and time"
- Dynamic Gaussian Splatting: A scene representation that uses time-varying Gaussian primitives to render dynamic 3D content. "Dynamic Gaussian Splatting \cite{kerbl20233d,wu20244d}"
- Gaussian-splatting optimization: Refining rendered views by optimizing Gaussian primitive parameters for better quality. "refines them via Gaussian-splatting optimization"
- Latent frame: A compressed representation of a video frame within the model’s latent space used for efficient generation. "produces =21 latent frames"
- LPIPS: A perceptual image similarity metric that correlates with human judgments, used to evaluate generative quality. "We report PSNR, SSIM, and LPIPS."
- Masked FiLM: A conditioning mechanism where Feature-wise Linear Modulation is selectively applied to integrate control signals while preserving identity. "introduces a Masked FiLM mechanism"
- Monocular video: A single-camera video without multi-view or stereo information. "Given a monocular video"
- Multi-view video diffusion: Generating or conditioning on multiple views with diffusion models to handle spatial consistency across viewpoints. "uses multi-view video diffusion to generate sparse, time-conditioned views"
- NeRFs: Neural Radiance Fields, a neural scene representation for synthesizing novel views from 2D images. "representations such as NeRFs"
- Optical flow: Pixel-level motion estimation between frames used as a cue for dynamic scene modeling. "optical flow \cite{li2023dynibar,li2021nsff}"
- Patchifying module: A component that converts video frames into token patches for Transformer processing. "x is the output of the patchifying module"
- PSNR: Peak Signal-to-Noise Ratio, a fidelity metric for comparing generated frames to ground truth. "We report PSNR, SSIM, and LPIPS."
- RoPE (Rotary Position Embedding): A positional encoding technique that applies rotation in embedding space to represent sequence positions. "such as RoPE()."
- RTA@15: Rotation Threshold Accuracy at 15 degrees, measuring how often estimated rotation is within 15° of the target. "report RotErr, RTA@15 and RTA@30"
- RTA@30: Rotation Threshold Accuracy at 30 degrees, measuring how often estimated rotation is within 30° of the target. "report RotErr, RTA@15 and RTA@30"
- RotErr: Rotation error metric quantifying deviation between generated and target camera rotations. "Trajectory accuracy is quantified using and "
- Sinusoidal time embeddings: Continuous periodic encodings used to represent temporal positions for controllable retiming. "we adopt sinusoidal time embeddings applied at the latent frame level"
- Space–time disentanglement: Separating spatial (camera) control from temporal (motion) control in generative modeling. "spaceâtime disentanglement"
- SSIM: Structural Similarity Index Measure, a perceptual metric for image quality based on structural information. "We report PSNR, SSIM, and LPIPS."
- Temporal warping: Non-linear remapping of timestamps to create diverse temporal behaviors for training controllable retiming. "temporal-warping training scheme"
- Trajectory accuracy: Quantitative assessment of how well generated camera trajectories match specified targets. "Trajectory accuracy is quantified using and "
- TransErr: Translation error metric quantifying deviation between generated and target camera translations. "Trajectory accuracy is quantified using and "
- VBench: A benchmark suite for evaluating visual quality and consistency of generative videos across multiple dimensions. "using VBench"
- Video tokens: Discrete representations (tokens) derived from video frames used by Transformer-based diffusion backbones. "video tokens embeddings"
Practical Applications
Immediate Applications
The following items can be deployed now or prototyped with current tooling, given adequate compute and video quality.
- Pro-grade video retiming and camera re-posing in NLEs
- Sector: media/entertainment, VFX, advertising
- Application: A plugin for editors like Adobe Premiere Pro/After Effects or DaVinci Resolve that adds bullet time, slow motion, reverse motion, and precise camera moves (pan/tilt/dolly/zoom) from a single input video.
- Workflow: Ingest a clip; estimate source camera poses; author a camera path and an “animation time” curve; render continuous output; optionally extend with the autoregressive segmenting strategy for long sequences.
- Dependencies/assumptions: GPU inference; accurate camera pose estimation for source/target; quality degrades under severe occlusion or extreme viewpoint changes; licensing for the underlying T2V backbone; content provenance/watermarking recommended.
- Social-media reframing and aspect ratio conversion
- Sector: social platforms, marketing
- Application: Auto-reangle and retime to convert 16:9 → 9:16 (or vice versa) while preserving subject identity and scene dynamics; add short bullet-time moments for engagement.
- Workflow: One-click “reframe + time effect” tool that takes a creator’s single video and outputs platform-optimized edits.
- Dependencies/assumptions: Sufficient source resolution and motion clarity; GPU acceleration; safeguards against identity/scene distortion.
- Single-camera sports highlights with multi-angle effects
- Sector: sports production, broadcast post
- Application: Create “Single-Cam Multi-Angle” replays (bullet time, reverse, variable-speed segments) from broadcast footage without multi-camera rigs.
- Workflow: Operators specify desired camera trajectory and time curve per highlight; render coherent multi-angle replay segments; integrate with broadcast replay servers.
- Dependencies/assumptions: Robustness to fast action, motion blur, and large parallax; consistency checks to avoid misleading geometry; content labeling to distinguish generative replays from original capture.
- E-commerce product video enhancement
- Sector: retail, product marketing
- Application: Orbit around a product while locking animation time to showcase a feature; retime interactions; fill missing angles for catalog videos.
- Workflow: Ingest a single product clip; define camera path (orbit/tilt/zoom) and animation-time freeze; output polished product demonstrations.
- Dependencies/assumptions: Controlled lighting/background improves results; artifacts possible with reflective/translucent materials; disclosure of generative augmentation.
- Cinematography previsualization from rehearsal footage
- Sector: film/TV production
- Application: Explore alternate camera moves and timing from rehearsal clips to plan shoots (e.g., test dolly vs. pan with slow-motion beats).
- Workflow: Upload rehearsal video; experiment with combined space–time trajectories; export shot plans or temp edits for directors.
- Dependencies/assumptions: Previs only—final capture still needed; camera-path realism must be reviewed by DoP; compute budget on set or in studio.
- Post-production stabilization and motion editing
- Sector: post-production, documentary
- Application: Stabilize camera motion while preserving or retiming scene dynamics; or lock time (bullet-time) while executing a smooth camera path to emphasize a moment.
- Workflow: Derive stabilization path; optionally apply animation time lock; render stable, viewer-friendly sequences.
- Dependencies/assumptions: May hallucinate unseen regions; QA pass required; provenance markers recommended.
- Interactive education content (physics, biomechanics)
- Sector: education
- Application: Retime and reangle classroom lab videos to visualize trajectories, collisions, or gait cycles from different viewpoints.
- Workflow: Educators annotate desired camera paths and time remaps; generate comparative views for instruction.
- Dependencies/assumptions: Best on relatively simple scenes; not a scientific measurement tool; communicate generative nature to students.
- Academic benchmarking and dataset use
- Sector: academia (vision, graphics)
- Application: Use the Cam×Time synthetic dataset for benchmarking controllable video generation and disentanglement; adopt the temporal-warping augmentation to repurpose existing multi-view data for time control.
- Workflow: Train and evaluate models on dense camera–time grids; compare ablations (1D Conv time embeddings, joint data training).
- Dependencies/assumptions: Dataset release/availability; license compatibility; reproducibility across backbones.
- Model fine-tuning for camera-controlled diffusion
- Sector: software, AI research
- Application: Fine-tune existing camera-conditioned video diffusion models with the proposed source-aware camera conditioning and time embedding to gain robust dual control.
- Workflow: Integrate the E(c_src), E(c_trg), and E(t) modules; adopt temporal-warping recipes; evaluate via PSNR/SSIM/LPIPS and camera trajectory metrics.
- Dependencies/assumptions: Access to base T2V models; training compute; adherence to model licensing and data use policies.
- Creator tools for “space–time curves”
- Sector: creative tooling
- Application: Authoring UI for camera trajectories and animation-time curves (freeze, zigzag, variable speed) with preview; export as generative effects.
- Workflow: Timeline editor with dual tracks (camera, time); discreet bullet-time markers; render with SpaceTimePilot-like backend.
- Dependencies/assumptions: Usability design; session caching; clear indicators for AI-modified content.
Long-Term Applications
These items will benefit from further research, scaling, or real-time constraints, and require reliability, safety, and policy frameworks.
- Real-time multi-angle live broadcasts from a single camera
- Sector: live sports, concerts
- Application: Viewers switch angles and time effects during live events; operators orchestrate generative camera feeds.
- Needed advances: Low-latency inference, edge compute, reliability under extreme motion/lighting, continuous camera-pose estimation; strict labeling to prevent confusion with actual camera feeds; broadcast standards for AI-generated views.
- Interactive telepresence and VR scene exploration
- Sector: AR/VR, communication
- Application: Participants freely navigate both camera and time within live or recorded scenes for immersive telepresence.
- Needed advances: Real-time rendering, spatial audio alignment, comfort tuning (motion sickness mitigation), persistent 4D memory; rigorous privacy and consent policies; provenance and access controls.
- Volumetric capture-lite for production
- Sector: media/entertainment, gaming
- Application: Replace multi-camera volumetric rigs with single-camera generative 4D pipelines for previs, rehearsals, and selective final shots.
- Needed advances: Artifact reduction to production-grade fidelity; material/lighting realism; safety and ethics guidelines to prevent deceptive use; standardized QC workflows.
- Autonomous systems simulation and perception training
- Sector: robotics, automotive
- Application: Generate diverse viewpoint/time scenarios from real-world recordings (e.g., dashcams) for data augmentation and rare-edge case rehearsal.
- Needed advances: Domain fidelity, physics- and geometry-consistent generation, validation frameworks to avoid learning spurious cues; risk management for safety-critical training.
- Surgical and medical training replays
- Sector: healthcare education
- Application: Freeze and orbit around critical moments in procedure videos; retime complex instrument motions for teaching and review.
- Needed advances: Clinical-grade reliability, privacy-preserving pipelines, strict disclaimers (not for diagnosis); regulatory clearance; controlled deployment in accredited training programs.
- Historical footage enhancement and re-examination
- Sector: archives, museums
- Application: Explore alternative viewpoints/time remaps for educational exhibits.
- Needed advances: Ethical guidelines to avoid misrepresentation; provenance and audit trails; expert curation; robust handling of degraded footage.
- AI “director” for automated cinematography
- Sector: creative AI
- Application: Systems that autonomously propose and render camera/time manipulations aligned with narrative beats.
- Needed advances: Story understanding, audience comfort considerations, consistent character/scene identity; human-in-the-loop oversight; explainable decision traces.
- Standards and policy for generative camera–time edits
- Sector: policy, compliance
- Application: Watermarking, content authenticity labels, audit tools that record camera/time manipulations; guardrails for evidence handling.
- Needed advances: Industry-wide standards (e.g., C2PA extensions for camera/time trajectories), platform enforcement, legal frameworks regulating use in journalism and forensics.
- Consumer-grade real-time mobile apps
- Sector: consumer software
- Application: On-device apps offering instant bullet time and reangles from phone videos.
- Needed advances: Efficient model distillation/quantization, hardware acceleration, battery-friendly pipelines; UX safeguards to prevent misleading outputs.
Cross-cutting assumptions and dependencies
- Model performance depends on accurate camera pose estimation and high-quality source videos; extreme viewpoint changes, heavy occlusions, fast motion blur, and complex materials (highly reflective/translucent) are challenging.
- Compute requirements are non-trivial; real-time use cases demand significant optimization, edge inference, or hardware acceleration.
- Content authenticity, watermarking, and clear user disclosure are essential to avoid misuse and confusion (especially in broadcast, journalism, forensics).
- Licensing and data governance: ensure compliance with backbone model licenses and dataset terms; respect privacy and consent when processing personal or sensitive videos.
- Safety-critical domains (autonomy, healthcare) require rigorous validation, domain-specific constraints, and regulatory approvals before deployment.
Collections
Sign up for free to add this paper to one or more collections.