AnyView: Synthesizing Any Novel View in Dynamic Scenes
Abstract: Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
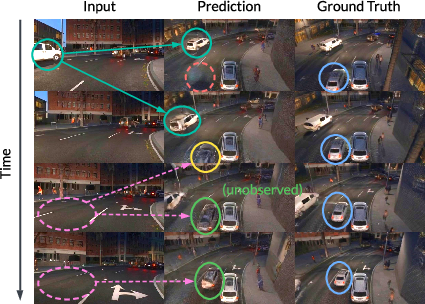
This paper introduces AnyView, a new AI system that can take one video of a moving scene and create a brand-new video from any other camera angle—even angles that are very far away from the original one. It focuses on keeping the scene realistic and consistent over time, even when lots of things are moving and the new viewpoint shows parts of the world the original camera never saw.
What questions did the researchers ask?
- Can we generate a believable video of a dynamic (moving) scene from any chosen viewpoint using only a single input video?
- Can the generated video stay consistent over time (objects don’t flicker or jump) and across big viewpoint changes (the scene still “makes sense” in 3D)?
- Can we do this without costly extra steps during testing (no slow fine-tuning) and without building a full 3D model of the scene first?
- How well does this work compared to existing methods, especially when the target camera view barely overlaps with the input view?
How did they try to solve it?
The team built AnyView using a “diffusion” video model and trained it on many types of data. Here’s the core idea explained in everyday terms:
- Diffusion model: Imagine starting with TV static (pure noise) and slowly “cleaning” it to reveal a video. The model learns how to remove noise step by step until a realistic video appears. This process lets the model “fill in” missing parts in a smart way.
- Implicit 4D understanding (no hard 3D rebuild): Instead of building a precise 3D map (which is hard when things move and parts of the scene are unseen), AnyView learns patterns of shape, motion, and appearance directly from lots of examples. Think of how you can picture the other side of a room you’ve never seen based on experience—that’s the kind of “intuition” the model learns.
- Camera conditioning with rays: To tell the model “where” the camera is looking, they encode camera information as dense “rays” that shoot through every pixel (like millions of tiny flashlights pointing into the scene). This ray-based encoding works for many camera types and gives the model a clear sense of viewpoint without forcing a fragile 3D reconstruction first.
- Input and target pairing: The model takes:
- the input video (what you actually see),
- the target camera path (where you want the new camera to move), and
- the ray information for both cameras,
- and then iteratively removes noise to produce the new video from the target angle.
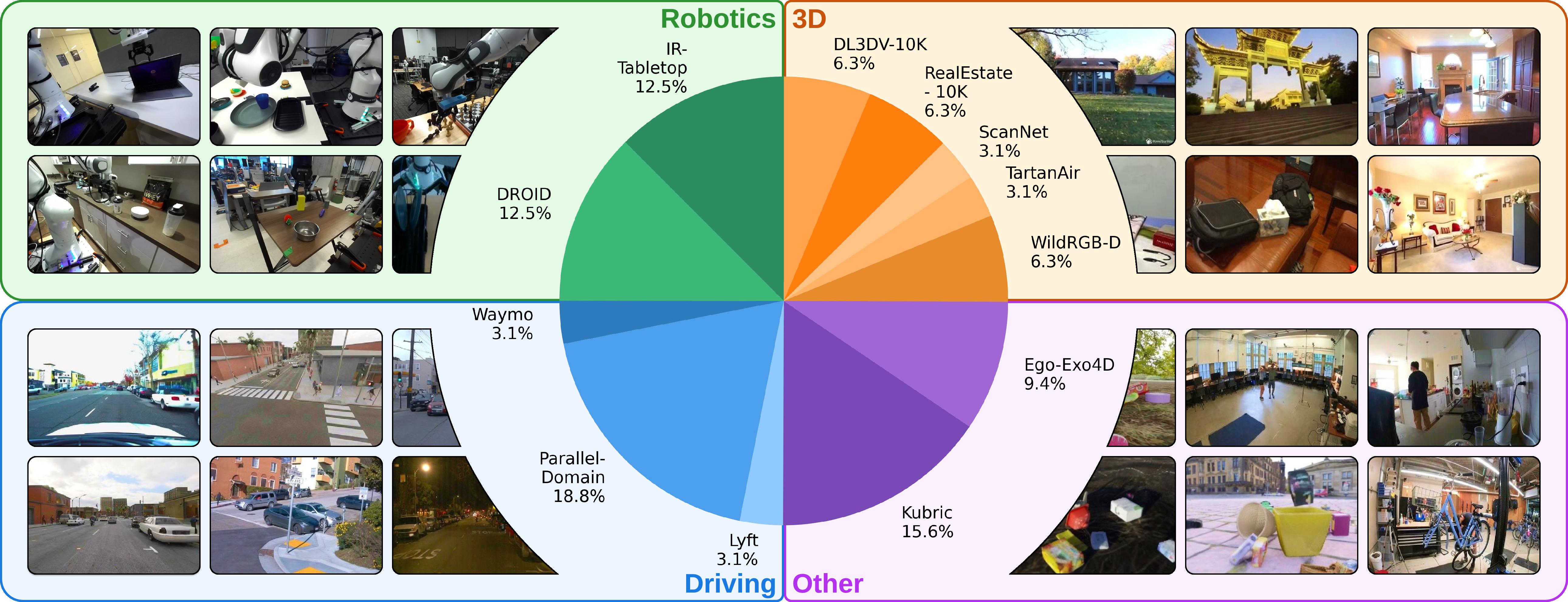
- Training with diverse data: They trained on a mix of datasets:
- 2D videos (for appearance and motion),
- multi-view videos of static scenes (for geometry),
- multi-view videos of dynamic scenes (for motion + geometry together).
- This blend teaches the model to generalize across different situations like driving, robotics, and human activities.
- No test-time optimization: Once trained, AnyView works “as is.” You don’t need to run extra slow steps for each new video.
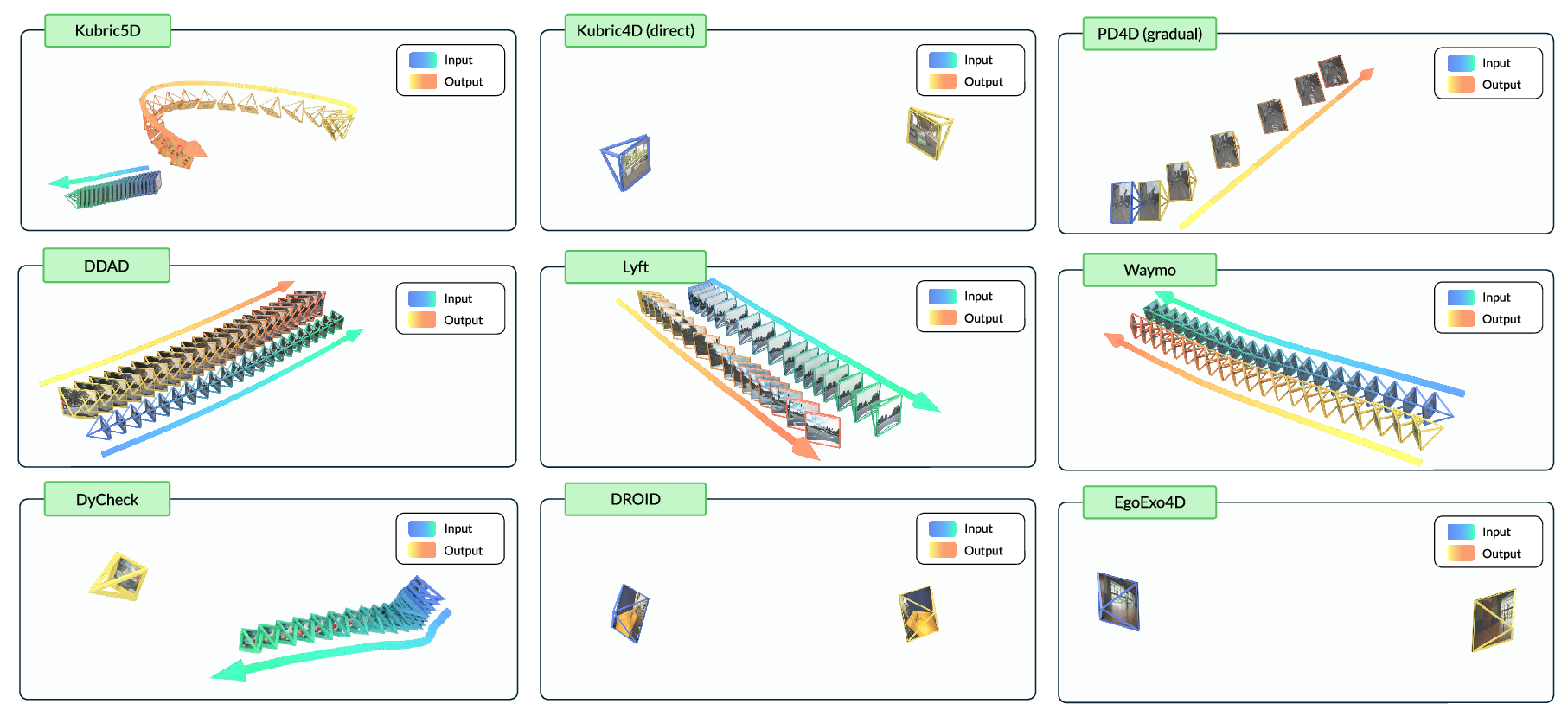
They also created AnyViewBench, a new testing ground designed to be tough. It includes scenarios with:
- Big camera movements,
- Small or no direct overlap between views,
- Real, simulated, and different domains (cars, robots, people), so it’s more like an obstacle course than a simple test.
What did they find and why is it important?
Main findings:
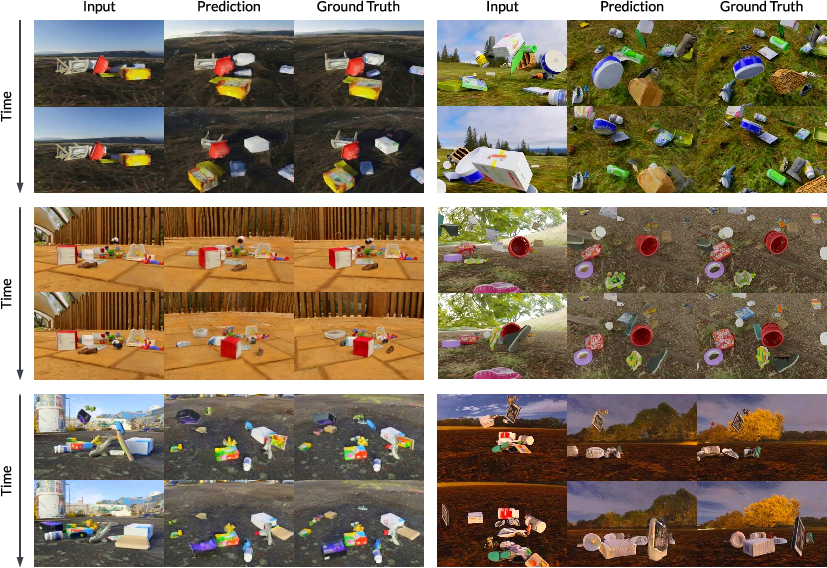
- Works from almost any viewpoint: AnyView can generate realistic, stable videos even when the target camera angle is extremely different from the input view and sees lots of unseen areas.
- Better consistency over time: Objects keep their shape and appearance as they move; the video doesn’t flicker or fall apart when the camera viewpoint shifts a lot.
- Beats many baselines in hard settings: In the “extreme” scenarios with little overlap between views, methods that rely on building 3D depth maps and inpainting often fail or become unstable. AnyView stays plausible and coherent.
- Zero-shot generalization: It performs well on new datasets and domains it wasn’t trained on, showing strong generalization.
- Fast and simple at test time: Unlike methods that need extra optimization or fine-tuning per video, AnyView runs end-to-end without those costly steps.
Why this matters:
- Real-world scenes are messy: In driving, robotics, sports, and everyday videos, cameras move, objects move, and not everything is visible. AnyView handles that uncertainty better than methods that expect lots of overlap or perfect depth.
- Robustness: Systems like robot controllers or self-driving car “world models” need consistent videos even if camera angles change. AnyView’s consistency can reduce brittleness when viewpoints shift.
What is the potential impact?
This research pushes video generation closer to how humans “imagine” unseen parts of the world. If it keeps improving, it could help:
- Robotics: Give robots reliable multi-view video of their surroundings from one camera feed, improving decision-making.
- Self-driving: Create consistent side or rear views from a front camera, useful for simulation, training, and safety checks.
- VR/AR and telepresence: Re-render scenes from new angles so people can “move” through a captured moment.
- World models and simulation: Build richer, more coherent training data for AI that learns how the world works.
- Research standards: AnyViewBench sets a tougher, more realistic benchmark, encouraging future methods to handle extreme viewpoint changes, not just easy cases.
In short, AnyView shows that we can learn to generate believable videos from almost any viewpoint without building an exact 3D scene first. That’s a big step toward flexible, reliable visual AI in the real world.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions the paper leaves unresolved.
- Robustness to camera pose errors: The method assumes accurate input/target poses and intrinsics; its sensitivity to pose noise, rolling-shutter effects, desynchronization, and calibration drift is not quantified or addressed.
- Non-pinhole camera validation: While Plücker conditioning claims to naturally support non-pinhole models, there is no empirical evaluation on fisheye/panoramic/omnidirectional datasets to validate controllability and consistency in these regimes.
- Minimum-overlap requirements: The method presumes some spatial overlap (potentially asynchronous) between input and target views; the minimum overlap needed for reliable synthesis is neither measured nor modeled.
- Uncertainty representation and calibration: The model produces single-point predictions; uncertainty over unobserved regions (e.g., confidence maps, calibrated probabilities, sample diversity) is not quantified or provided to downstream users.
- Physical and semantic consistency guarantees: There is no mechanism or audit to enforce or verify physics (e.g., collision avoidance, occlusion reasonableness, object permanence) or semantic plausibility beyond pixel metrics and anecdotal examples.
- Hallucination analysis in safety-critical settings: Systematic measurement of incorrect hallucinations (e.g., phantom vehicles/pedestrians) and their impact on autonomy/robotics is missing, especially under extreme viewpoint changes and low overlap.
- Metrics beyond PSNR/SSIM/LPIPS: The evaluation lacks multi-view/4D consistency measures (e.g., epipolar/cycle consistency, cross-view flow/depth consistency), physics-based plausibility metrics, and human perceptual studies tailored to dynamic multi-view settings.
- Long-horizon and high-resolution scalability: Performance and stability over longer sequences (minutes) and higher resolutions are not studied; drift, memory, and temporal accumulation of errors under extended horizons remain unknown.
- Streaming/online generation: The method is not evaluated for streaming inputs, causal generation, or continual updating as new frames arrive (important for real-time applications).
- Multi-view output consistency: Generating multiple target views simultaneously and enforcing mutual cross-view consistency is not explored.
- Domain coverage gaps: Training/evaluation excludes several challenging domains (e.g., night/adverse weather, strong specular/translucent materials, indoor scenes with complex lighting, fluids); generalization in these regimes is unknown.
- Pose-free inputs: A practical pipeline for unknown input poses (e.g., handheld phone videos) is not provided; integration with pose/structure estimation (e.g., ViPE, SfM) and robustness under estimation errors is untested.
- Camera intrinsics variation over time: While claimed support exists, the method’s behavior under rapidly changing intrinsics (zoom, focus, aperture, distortion changes) is not quantified.
- Scale normalization and absolute scale: Per-dataset translation normalization to [-1,1] may mask absolute scale differences; the impact on cross-dataset generalization and scale accuracy is not ablated.
- Architectural ablations: No ablation on camera encoding choices (Plücker vs other embeddings), token concatenation vs specialized cross-view attention, or injection points for camera conditioning to understand trade-offs.
- Hybrid explicit–implicit approaches: The benefits of augmenting AnyView with coarse geometry (e.g., sparse depth/points) or learned geometric priors are not explored; when and how explicit hints improve extreme view synthesis remains open.
- Data scaling laws and mixture composition: The impact of dataset diversity, domain weighting, curriculum schedule, and the contribution of each of the 12 datasets to generalization is not analyzed.
- Failure mode taxonomy: A systematic characterization of failure cases (e.g., texture bleeding, geometry distortions, temporal flicker, impossible motion) and their dependence on camera motion, dynamics, and scene content is missing.
- Robustness to sensor artifacts: Sensitivity to motion blur, noise, auto-exposure/white balance changes, compression artifacts, and HDR/low-light conditions is not evaluated.
- Controllability of content: With language conditioning disabled, the system lacks tools to constrain or edit scene content (e.g., “do not add cars,” preserve object identities); controllability trade-offs are not studied.
- Downstream task impact: How improved extreme view synthesis affects robot policies, world models, and planning (e.g., robustness to camera perturbations) is not experimentally validated.
- Compute efficiency and accessibility: Training requires 64 H200 GPUs; pathways for smaller models, distillation, inference-time speedups, edge deployment, and energy/compute cost analyses are not provided.
- Reproducibility and benchmark standardization: AnyViewBench release details, protocols for camera conventions, synchronization, and standardized metrics are not finalized; statistical significance and confidence intervals for reported results are absent.
- Ethics and safety considerations: Policies for preventing harmful or misleading hallucinations, user warnings in safety-critical contexts, and dataset privacy/licensing implications are not discussed.
- Extracting usable 3D/4D structure: The method does not provide explicit scene geometry; how to recover consistent 3D assets or physics-ready representations from the implicit model remains an open problem.
Practical Applications
Below is an overview of practical, real-world applications derived from the paper’s findings, methods, and innovations. Each item specifies sector alignment, plausible tools/products/workflows, and key assumptions or dependencies that may impact feasibility.
Immediate Applications
The following use cases can be deployed now with current capabilities, subject to standard engineering integration, calibration, and governance.
- Video editing and post-production (Entertainment/Media)
- Application: Camera retargeting and free-viewpoint reframing from a single take; create alternate shots or dolly effects without re-shooting.
- Tools/Products/Workflows: “AnyView Studio” plugin for NLEs (e.g., Premiere, Resolve) with camera-trajectory authoring; batch export for different perspectives.
- Assumptions/Dependencies: Requires known or estimated camera intrinsics/extrinsics for input video; outputs are plausible rather than ground-truth—use watermarks and provenance metadata to avoid forensic misuse.
- Sports broadcasting and replays (Media/Entertainment)
- Application: Free-viewpoint replays from a limited set of cameras (or even one); enhance fan engagement by synthesizing novel angles for pivotal plays.
- Tools/Products/Workflows: “AnyView Replay” service integrated with live production pipelines; operators specify target camera trajectories per highlight.
- Assumptions/Dependencies: Partial content overlap over time helps quality; latency acceptable for near-live replay rather than real-time; clearly marked as generative.
- Telepresence and video conferencing (Software/Communication)
- Application: Eye-contact correction and view-stabilized framing by synthesizing frontal views from off-axis webcams; improved remote meeting experience.
- Tools/Products/Workflows: SDK that ingests camera parameters (or estimates them) and applies AnyView re-rendering; deploy in conferencing apps as a toggle.
- Assumptions/Dependencies: Low-latency inference is necessary; camera calibration or robust pose estimation is required; clear user disclosure that view is synthesized.
- Robotics training and evaluation (Robotics)
- Application: View-consistent data augmentation for visuomotor policies to reduce brittleness to camera pose changes; generate overhead or side views from a single capture.
- Tools/Products/Workflows: “View-Independence Augmentation” module integrated in policy training pipelines; batch synthesis of alternate viewpoints per episode.
- Assumptions/Dependencies: Pose accuracy matters; outputs are plausible—use for training augmentation, not runtime decision-making; domain match to training mixture improves realism.
- Autonomous driving dataset augmentation (Automotive/Software)
- Application: Generate synchronized multi-view clips from single-view runs to train perception models (e.g., left-front-right views); amplify rare scenario coverage.
- Tools/Products/Workflows: Data ops pipeline using AnyView to produce consistent alternate camera sequences; evaluation via AnyViewBench metrics to monitor fidelity.
- Assumptions/Dependencies: Not suitable for operational runtime perception; requires fleet camera models and pose metadata; clearly flagged as synthetic for downstream training systems.
- Surveillance operations planning and coverage assessment (Security)
- Application: Blind-spot visualization by synthesizing alternate views from existing cameras for planning better placements or evaluating coverage gaps.
- Tools/Products/Workflows: “Coverage Simulator” that reprojects scenes from different virtual vantage points during site surveys.
- Assumptions/Dependencies: Use for planning and visualization only; not for evidentiary purposes; camera parameters must be known; potential bias/hallucinations in unobserved regions.
- E-commerce product showcases (Retail/Software)
- Application: Spin-from-video for dynamic demos—produce multiple viewing angles of a product-in-use from one short video.
- Tools/Products/Workflows: Web SDK to author target camera paths; pipeline to produce multi-angle clips for product pages.
- Assumptions/Dependencies: Controlled backgrounds and consistent lighting improve results; realistic but not guaranteed accurate geometry.
- Education and training content (Education)
- Application: Interactive multi-view replays of lab experiments, sports techniques, or demonstrations; viewpoint-aware pedagogy.
- Tools/Products/Workflows: Classroom apps that allow students to scrub time and change viewpoints; instructor-defined camera trajectories for learning goals.
- Assumptions/Dependencies: Scenes should resemble training domains (driving, human activity, robotics) for best results; label as synthesized.
- Research benchmarking and evaluation (Academia)
- Application: Standardized evaluation of dynamic view synthesis under extreme trajectories with AnyViewBench; reproducible comparisons and progress tracking.
- Tools/Products/Workflows: Public leaderboards, validation subsets, consistent metrics (PSNR/SSIM/LPIPS) and qualitative protocols for spatiotemporal plausibility.
- Assumptions/Dependencies: Community adoption; consistent camera conventions; explicit disclosure of calibration and dataset splits.
Long-Term Applications
These use cases require further research, scaling, reliability improvements, or real-time deployment capabilities before broad adoption.
- Real-time AR/VR free-viewpoint streaming (Media/AR/VR)
- Application: Live events with headset-based arbitrary viewpoints from sparse camera setups; interactive concert or sports experiences.
- Tools/Products/Workflows: Streaming AnyView variants with low-latency inference, temporal caching, and hardware acceleration; headset SDKs for camera path authoring.
- Assumptions/Dependencies: Significant latency and throughput reductions; robust multi-camera synchronization; strong domain-generalization and guardrails for hallucinations.
- Autonomous driving virtual camera fusion (Automotive)
- Application: “Virtual sensors” to complement limited camera arrays for planning and scene understanding; fill geometric coverage gaps.
- Tools/Products/Workflows: Planning stacks that consume synthesized views for redundancy analysis, not direct control; offline validation and uncertainty quantification.
- Assumptions/Dependencies: Strict safety and reliability requirements; formal uncertainty bounds; audited domain coverage; regulatory acceptance; synthesized views used for training/simulation, not live decision-making until proven safe.
- Teleoperation for surgical and industrial robots (Healthcare/Robotics)
- Application: Real-time viewpoint synthesis (e.g., synthetic endoscope angles) to improve operator situational awareness in constrained spaces.
- Tools/Products/Workflows: Integrations with robot control UIs; latency-optimized hardware; on-device inference; per-device camera models.
- Assumptions/Dependencies: Clinical-grade reliability and validation; stringent safety protocols; domain-specific retraining; regulatory approvals.
- Digital twins and world-modeling at scale (Software/Simulation/Urban Planning)
- Application: Implicit 4D generative environments that maintain spatiotemporal consistency for simulation, planning, and forecasting.
- Tools/Products/Workflows: “Generative Twin Builder” for cities/factories; integration with trajectory-aware attention and camera-conditioned diffusion; coupling with physics/agent models.
- Assumptions/Dependencies: Domain coverage expansion; consistency constraints across long sequences; compositional control; alignment to real-world maps and sensors.
- Accident reconstruction and forensics (Public Safety/Policy)
- Application: Assisted reconstruction from limited dashcam or CCTV footage to explore plausible viewpoints and narrative sequences.
- Tools/Products/Workflows: Analyst tools to generate candidate views and annotate uncertainty; policy frameworks for disclosure and provenance; legal guidelines for use.
- Assumptions/Dependencies: Outputs are plausible, not ground-truth; must include uncertainty metadata and watermarks; strong governance to prevent misuse; standards for admissibility.
- Consumer mobile apps with on-device synthesis (Software/Consumer)
- Application: Personal videos re-framed to “best angle” automatically; selfie or action-cam viewpoint correction.
- Tools/Products/Workflows: Lightweight AnyView variants for mobile NPUs; app UX for camera path selection; privacy-preserving on-device inference.
- Assumptions/Dependencies: Model compression and acceleration; battery and thermal constraints; simplified camera calibration flows; user consent and disclosure.
- Domain-specific expansions (Healthcare, Industrial Inspection, Mapping)
- Application: Specialized models for endoscopy, aerial inspections, or LiDAR-camera fusion with non-pinhole optics.
- Tools/Products/Workflows: Plücker-conditioned pipelines adapted to fisheye/omnidirectional lenses; hybrid sensor conditioning (e.g., sparse depth or IMU) for additional constraints.
- Assumptions/Dependencies: Extensive domain tuning; combined sensor calibration; safety and validation protocols; licensing and data availability.
- Governance, standards, and provenance (Policy/Standards)
- Application: Frameworks for labeling, watermarking, and tracking generative view synthesis in media and public records; minimum disclosure standards.
- Tools/Products/Workflows: Open metadata format for synthesized views; best-practice guidelines for evidence handling and consumer-facing disclaimers; benchmarks (AnyViewBench) used in certification.
- Assumptions/Dependencies: Multi-stakeholder agreement; regulatory alignment; standardized APIs for provenance.
Notes on feasibility and dependencies across applications:
- Camera parameters: AnyView expects known or estimated intrinsics/extrinsics. If unavailable, integrate with pose estimation tools (e.g., COLMAP, MoSca, ViPE) to create reliable Plücker ray/moment maps.
- Overlap and scene dynamics: Some spatiotemporal overlap (even if asynchronous) improves conditioning relevance. Fully unseen content remains uncertain and will be plausibly hallucinated.
- Domain generalization: Best performance in domains similar to the training mixture (driving, robotics, human activity, multi-object simulation). Specialized domains require finetuning or additional datasets.
- Runtime and hardware: Current inference is well-suited to offline and near-real-time use cases; true real-time streaming will require optimization and dedicated accelerators.
- Safety and ethics: Generated views are not ground-truth. Use for augmentation, visualization, and exploratory analysis; avoid direct use in safety-critical control or forensics without robust uncertainty quantification, provenance, and governance.
Glossary
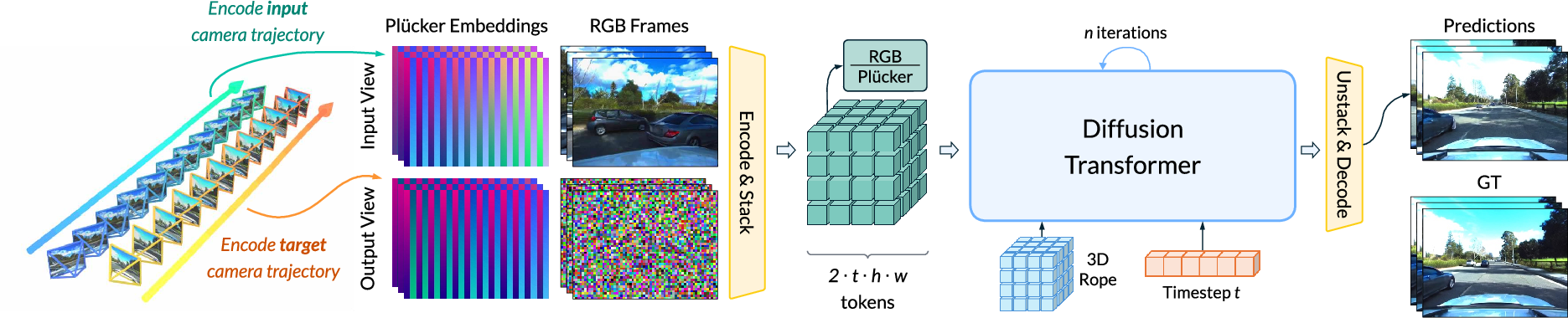
- 6-DoF: Six degrees of freedom describing a rigid body's position and orientation (3 translations + 3 rotations). "The camera parameters c_x,i_x,c_y,i_y represent two sequences of fully specified 6-DoF SE(3) camera poses"
- Camera extrinsics: External camera parameters that define the camera’s position and orientation in a world coordinate system. "assuming the camera-to-world extrinsics convention."
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) that define how 3D points project onto the image sensor. "with intrinsics i_x ∈ ℝ{T × 3 × 3}"
- Cosine schedule: A learning rate schedule that decays following a cosine function. "and drops smoothly to 1 ⋅ 10{-5} according to a cosine schedule."
- Cross-attention: An attention mechanism where a query attends to a different set of key-value pairs (e.g., between modalities or sequences). "After completing all self-attention and cross-attention blocks"
- Curriculum learning: Training strategy that gradually increases task difficulty or input complexity. "We apply curriculum learning with increasing resolution:"
- Dense ray-space conditioning: Conditioning a generative model using per-pixel ray information representing camera parameters in a dense map. "camera parameters are provided via dense ray-space conditioning"
- Depth reprojection: Projecting estimated depth from one view into another view to synthesize images at new camera poses. "rely on explicit 3D reconstructions (i.e., depth reprojection + image inpainting)"
- Diffusion transformer: A transformer-based model used within a diffusion process to iteratively denoise latent representations. "are fed into the diffusion transformer to iteratively denoise the target video."
- Ego(centric): Outward-facing viewpoints from cameras close to the subject of interest (e.g., a vehicle). "whereas ego(centric) refers to outward-facing viewpoints close to the subject of interest (e.g., a vehicle)."
- Ego vehicle: The vehicle equipped with sensors/cameras whose perspective defines the main observed viewpoint. "if the ego vehicle is moving"
- End-to-end: A training or inference approach where the model learns the entire task directly without separate hand-engineered stages. "Our model operates end-to-end, without explicit scene reconstruction or expensive test-time optimization techniques."
- Exo(centric): Inward-facing viewpoints from cameras outside the scene. "Exo(centric) refers to inward-facing viewpoints from cameras outside the scene"
- Implicit representation: A learned function or latent structure that encodes scene properties without explicit geometric reconstruction. "a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos"
- Inpainting: Filling in missing or occluded image regions using learned priors. "the heavy lifting of inpainting large occlusions is mostly avoided"
- Latent diffusion transformer: A diffusion model operating in a compressed latent space using a transformer backbone. "Cosmos, a latent diffusion transformer, as our underlying base representation"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual distance metric between images. "we report DVS results in terms of PSNR (dB), SSIM, and LPIPS (VGG)"
- Moment vector: In Plücker line representation, the vector m = r × o combining ray direction r and origin o to define a 3D line. "moment vectors m = r × o"
- Non-pinhole camera model: Camera models that deviate from the ideal pinhole assumption (e.g., fisheye, catadioptric). "natural handling of non-pinhole camera models"
- Outpainting: Generating plausible content beyond the boundaries or outside the observed field of view. "accurately outpaint much larger unobserved portions of the scene"
- Plücker representation: A line representation in 3D using a direction (ray) and moment vectors, useful for camera ray encoding. "encode all camera parameters c_x,i_x,c_y,i_y into a unified Pl\"{ucker representation"
- Plücker vectors: The pair of vectors (ray and moment) encoding a 3D line in Plücker space. "camera information (Plücker vectors)"
- PSNR: Peak Signal-to-Noise Ratio; a numeric measure of reconstruction fidelity (higher is better). "we report DVS results in terms of PSNR (dB), SSIM, and LPIPS (VGG)"
- Rotary positional embeddings: A positional encoding method that injects position information via rotations in embedding space. "All tokens are tagged with rotary positional embeddings"
- SE(3): Special Euclidean group in 3D, representing rigid body transformations (rotation + translation). "6-DoF SE(3) camera poses"
- Self-attention: An attention mechanism where elements in a sequence attend to each other within the same sequence. "After completing all self-attention and cross-attention blocks"
- SSIM: Structural Similarity Index Measure; a metric assessing image similarity based on structure, luminance, and contrast. "we report DVS results in terms of PSNR (dB), SSIM, and LPIPS (VGG)"
- Test-time optimization: Additional optimization performed on a per-instance basis at inference to improve results. "without explicit scene reconstruction or expensive test-time optimization techniques."
- Video tokenizer: A component that compresses raw video frames into lower-dimensional latent tokens. "First, the given video V_x is compressed into a latent space by a video tokenizer"
- Zero-shot: Performing a task on new data or domains without any task-specific training on that data. "capable of producing zero-shot novel videos"
Collections
Sign up for free to add this paper to one or more collections.