- The paper presents UMAMI, a hybrid method that combines deterministic rendering and masked autoregressive diffusion to generate high-fidelity novel views from sparse multi-view inputs.
- It employs a bidirectional transformer with confidence-based token routing to selectively apply a fast deterministic head or a diffusion process on ambiguous regions.
- Empirical evaluations on RealEstate10K and DL3DV benchmarks demonstrate state-of-the-art performance in PSNR, SSIM, and LPIPS, balancing speed and visual fidelity.
UMAMI: A Hybrid Autoregressive-Diffusion Framework for Photorealistic Novel View Synthesis
Overview and Motivation
The task of novel view synthesis (NVS)—producing photorealistic, 3D-consistent images from arbitrary camera viewpoints given sparse posed images—poses significant challenges due to occlusions and limited observations. Existing NVS paradigms split into deterministic feed-forward architectures, which offer fast and accurate rendering of observed regions but yield blurred artifacts in occluded areas, and fully generative (typically diffusion-based) models that can plausibly hallucinate unseen content at much higher computational cost.
"UMAMI: Unifying Masked Autoregressive Models and Deterministic Rendering for View Synthesis" (2512.20107) introduces an innovative hybrid framework that bridges these paradigms. UMAMI integrates deterministic rendering with a masked, autoregressive diffusion process, allocating computation based on per-patch confidence to synthesize both visible and occluded regions from sparse multi-view inputs with high fidelity and efficiency.
Methodology
UMAMI’s architecture centers on a bidirectional transformer backbone encoding multi-view inputs and target camera tokens, enabling both deterministic and stochastic prediction heads operating in image token space.
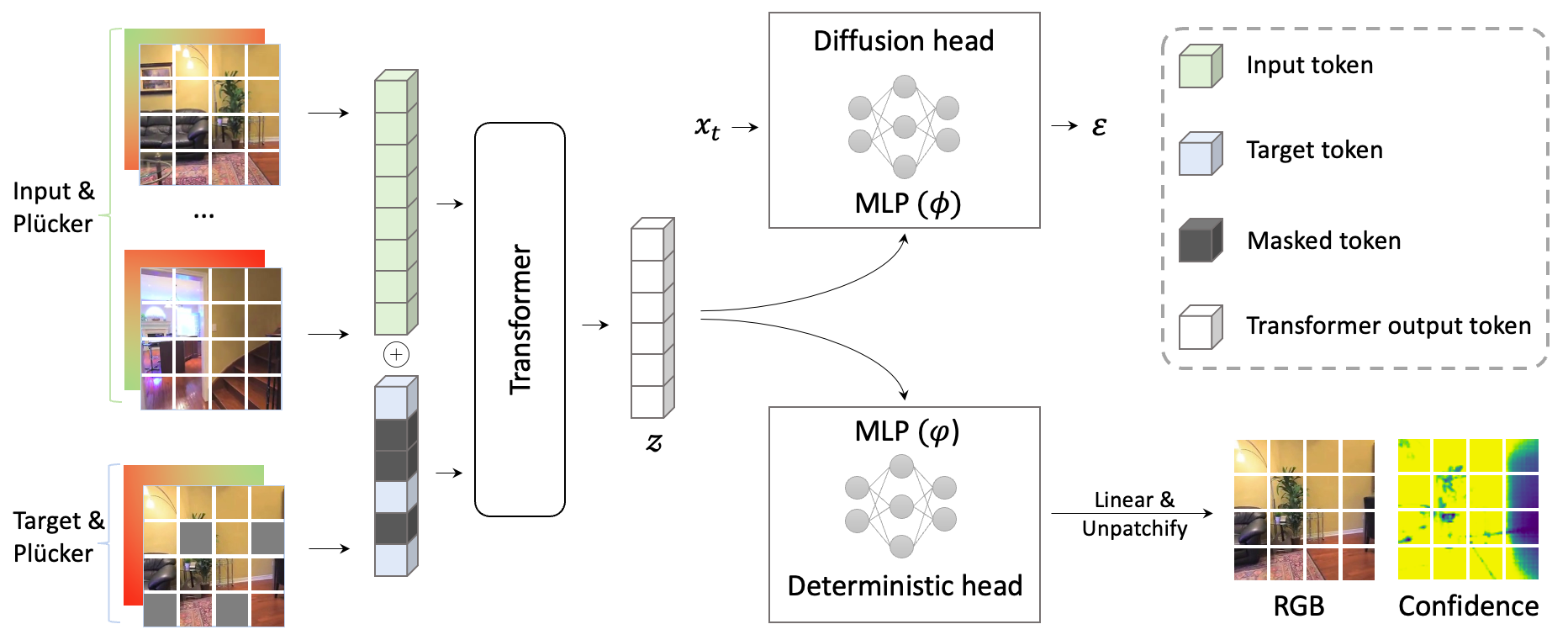
Figure 2: The model architecture: inputs (context and masked target views plus Plücker pose embeddings) are tokenized, processed by a transformer, then split for deterministic and diffusion-based rendering.
Data Representation
Each context view and target pose is represented via its image patch and a corresponding Plücker ray embedding, tokenized into 8×8 grid symbols. This explicit camera encoding enables flexible conditioning for arbitrary-view synthesis without direct 3D-geometry priors.
Hybrid Inference: Deterministic and Generative Heads
- Transformative Encoding: Both input context and the partially masked target are processed by a bidirectional transformer. This produces a shared latent vector z encapsulating global and spatial context.
- Deterministic Head: For image patches where geometry (visibility and correspondence to context) is well established, a lightweight MLP predicts RGB/alpha and a per-pixel confidence map in a single forward pass.
- Diffusion Head: For the remaining, ambiguous regions, masked tokens are iteratively denoised using a gated masked autoregressive diffusion process inspired by [li2024autoregressive], conditioned on z. The network samples plausible completions for occluded or novel content, avoiding full image autoregression in observed regions.
Confidence-Based Token Routing
The model predicts a pixel-wise confidence map and automatically partitions target tokens: those above a threshold τ are classified as deterministic, while those below invoke the generative head. This confidence-aware mechanism enables adaptive allocation of computation and allows trade-offs between speed and diversity.
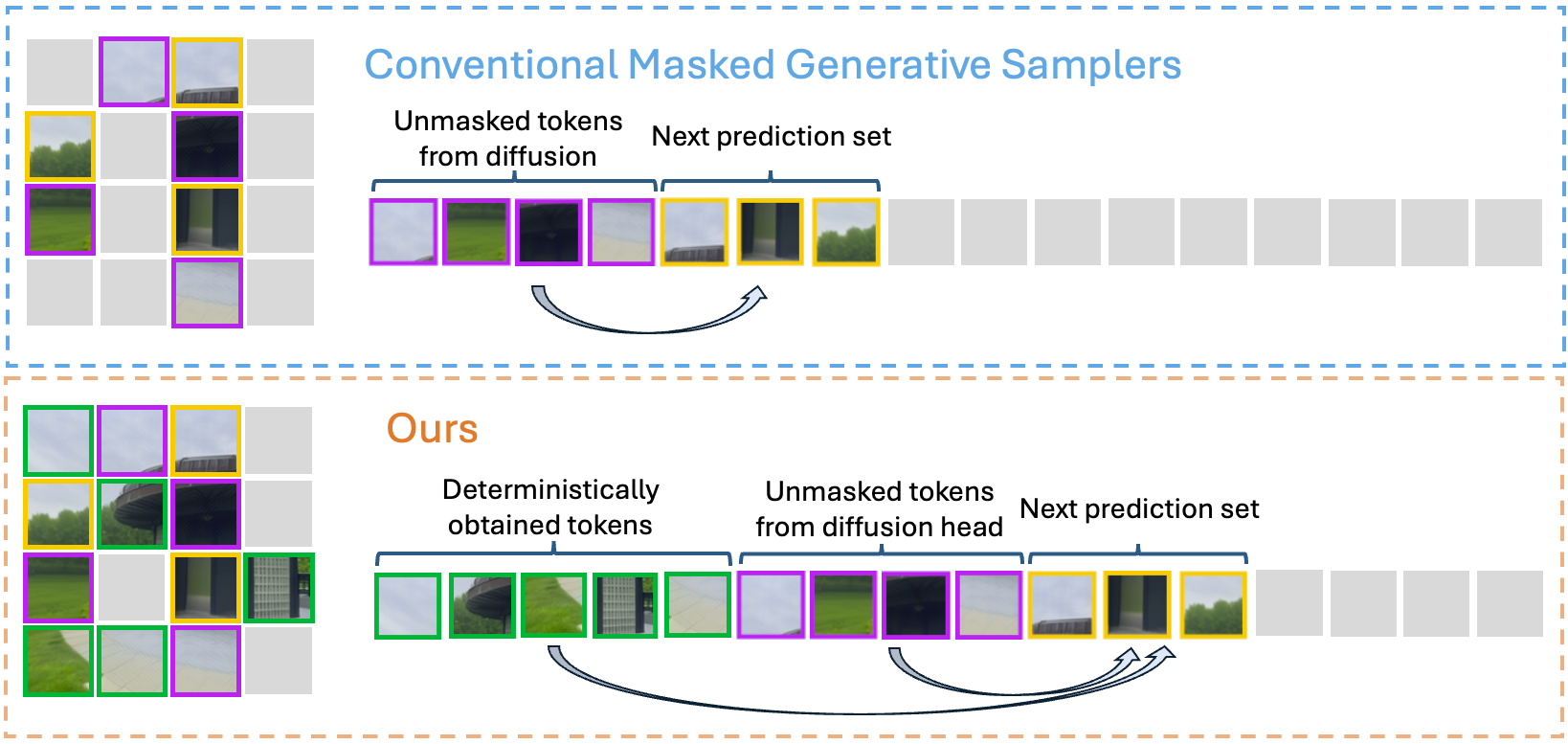
Figure 1: Hybrid masked autoregressive sampling: high-confidence regions use a deterministic pass, while uncertain patches are stochastically generated, minimizing redundant diffusion calls.
Training Objective
UMAMI is trained end-to-end with:
- Photometric loss for deterministic predictions (MSE and perceptual terms).
- Patchwise confidence loss to regularize the confidence map and discourage overconfidence.
- Diffusion loss (Denoising Score Matching) over masked/uncertain tokens, weighted to focus generative power on ambiguous regions.
This approach jointly optimizes both the speed and uncertainty-handling capabilities of the model, learning a fast but generative NVS function from data alone.
RealEstate10K and DL3DV Benchmarks
On the RealEstate10K and DL3DV datasets, UMAMI delivers state-of-the-art accuracy on both interpolation and challenging extrapolation settings:
- RealEstate10K-2View-Extra: UMAMI achieves top PSNR (28.95) and SSIM (0.897), outperforming diffusion-only and deterministic architectures in both seen and unseen content.
- DL3DV-3View: UMAMI attains highest PSNR, with second-best LPIPS and competitive SSIM, demonstrating strong generalization to wide-baseline and real-world scenarios.

Figure 3: UMAMI generates photorealistic novel views from sparse inputs, simultaneously excelling at single-view synthesis, multi-view extrapolation, and full-scene reconstruction, with sharpness and geometric consistency.
Qualitative Analysis
UMAMI outperforms deterministic baselines (such as LVSM and MVSplat) in unseen or extrapolated regions, eliminating “black” or blurred holes, and matches or surpasses diffusion models with substantially less compute.

Figure 4: On the Re10K-2View-Extra extrapolation set, UMAMI renders high-fidelity details in both visible and hallucinated areas, contrasting with baseline artifacts and blur.
Diffusion Threshold and View Conditioning
Ablation studies show that increasing the confidence threshold τ raises visual sharpness (better LPIPS) at modest runtime cost; more context views reduce the need for stochastic sampling, further accelerating inference with improved visual fidelity.

Figure 6: Effect of the diffusion threshold parameter τ; higher τ increases the reliance on the diffusion head, yielding sharper outputs but with longer inference.
Failure Cases and Limitations
UMAMI’s primary limitations manifest when the target view is at a large distance or has very low overlap with input views; in such cases, artifacts may appear, potentially mitigated by scaling model size and training data.

Figure 7: Failure cases occur if target poses are too distant; artifacts in hallucinated regions can result from bandwidth or data limitations.
Operating in pixel token space leads to elevated memory/compute load compared to latent-space methods, and the model does not leverage large pretrained text/image priors, thus generative flexibility might be further improved with foundation model integration.
Theoretical and Practical Implications
UMAMI’s hybrid paradigm demonstrates that confidence-driven selective generative modeling can substantially reduce the computational cost of high-fidelity view synthesis, removing the trade-off between fast deterministic rendering and plausible generative completion. By fully data-driven token conditioning without architectural 3D priors, UMAMI offers a scalable foundation for future geometry-free, generalizable NVS.
The results imply:
- Practical deployment of scalable NVS in interactive, real-time applications (AR/VR, robotic perception, virtual cinematography) at moderate computational cost.
- Flexible trade-offs via confidence thresholding (τ), enabling targeted use in latency-critical vs. quality-critical scenarios.
- Strong prospects for further improvement through VAE-based latent tokenization, foundation diffusion backbone integration, or extension to full video and temporal consistency tasks.
Conclusion
UMAMI achieves state-of-the-art combined speed, accuracy, and generative capacity for novel view synthesis from sparse inputs, via a compositional architectural framework uniting deterministic rendering and masked autoregressive diffusion. Its scalable, inductive-bias-light design, validated across multiple challenging NVS settings, establishes a promising basis for high-quality, practical, and generalizable view synthesis systems.