- The paper introduces effective multi-view factors (EMFs) to rigorously quantify multi-view cue leakage in monocular video datasets.
- It demonstrates that removing teleportation cues causes a 1–5 dB drop in key metrics, highlighting limitations in current synthesis models.
- The study validates its findings using a novel iPhone dataset that challenges protocols with realistic, smoothly moving single-camera captures.
Monocular Dynamic View Synthesis: A Reality Check
Introduction and Motivation
The paper "Monocular Dynamic View Synthesis: A Reality Check" (2210.13445) systematically investigates the mismatch between the purported goals of dynamic view synthesis (DVS) from monocular videos and the actual experimental protocols dominating current benchmarks. DVS aims to reconstruct and render dynamic 3D scenes (e.g., moving humans or objects) for applications in AR, creative content, and scene understanding using videos captured with a single, casually mobile camera. Despite the impressive performance of state-of-the-art approaches, this work demonstrates that most benchmarks enable performance inflation by relying on protocols that inadvertently leak multi-view signals into the monocular regime, obscuring the true challenge of the problem.
Effective Multi-View Leakage and Dataset Analysis
The central contribution is the introduction of effective multi-view factors (EMFs), a rigorous quantification of the multi-view cues present in input monocular videos. EMFs measure the relative magnitude of camera to scene motion (full EMF Ω) and the camera’s angular velocity (angular EMF ω). As shown in Figure 1, established datasets such as HyperNeRF, Nerfies, and NSFF possess high EMFs—implying that the data often mimic multi-view captures—due to practices like camera “teleportation” or quasi-static scenes.

Figure 1: Existing datasets exhibit high effective multi-view factors (EMFs), potentially reducing the real difficulty of monocular DVS; the new iPhone dataset introduces lower EMFs by capturing with realistic, smoothly moving single cameras.
More precisely, common protocols interpolate frames from different cameras (“teleportation”) to artificially assemble a high-temporal-rate, multi-fronted sequence, or otherwise select scenes with negligible object motion. This renders test-time synthesis a much less ill-posed problem since the model has already seen equivalent multi-view image sets during training. Figure 2 clearly visualizes these biases.

Figure 2: Existing training datasets primarily fall into two categories: (a) teleporting camera motion, or (b) quasi-static scene motion; both circumstances leak multi-view or bypass dynamic challenges.
The authors’ analysis reveals that for reliable advancement and evaluation of truly monocular DVS, EMFs must be reported and protocols eschewing teleportation must be prioritized.
Metrics for Monocular DVS Evaluation
Prior evaluation methodologies—full-frame image similarity metrics (such as PSNR, SSIM, LPIPS)—are also shown to conflate true synthesis with the ability to exploit unseen (but known) viewpoints due to multi-view leakage. The paper introduces two refined evaluation schemes:
- Co-visibility Masked Image Metrics: These restrict evaluation to pixels of test images that were actually observed in training, using an optical flow-based co-visibility mask, computing mPSNR, mSSIM, and mLPIPS only over those regions. Figure 3 illustrates the computation pipeline for generating these masks.
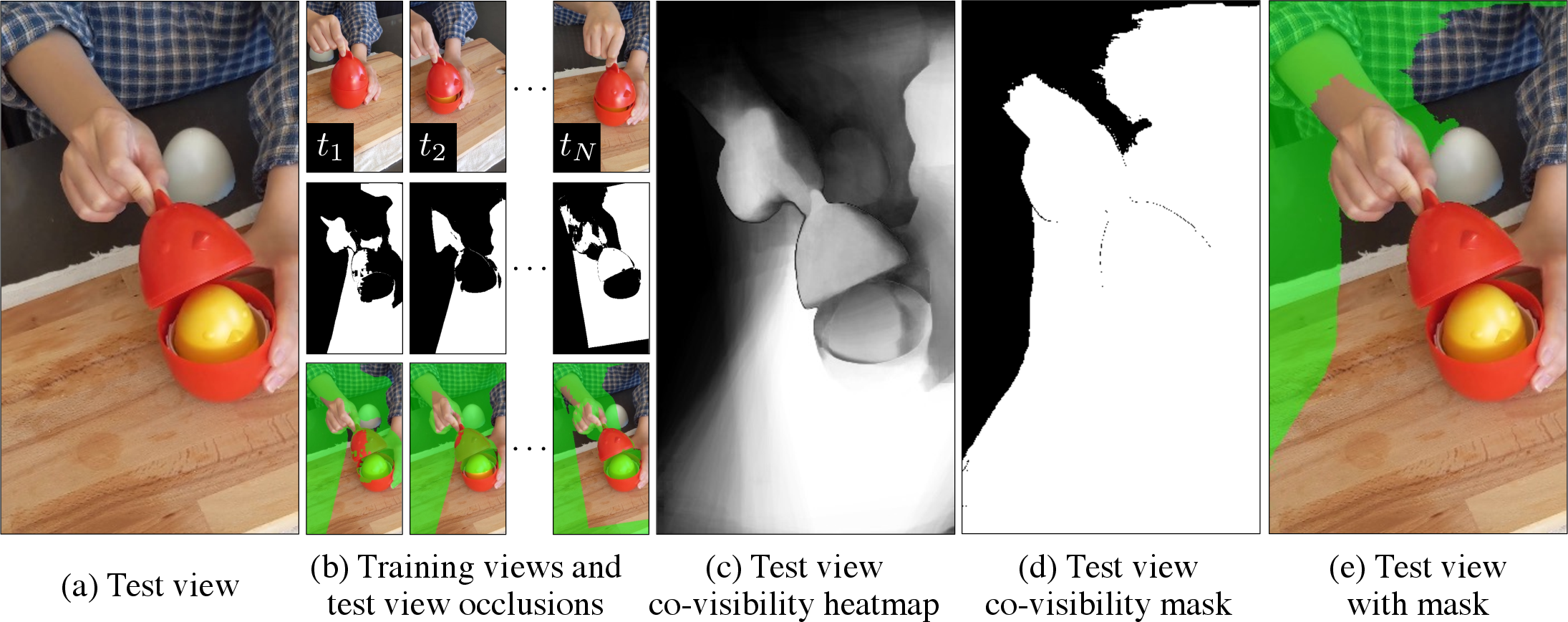
Figure 3: Computation of co-visibility relies on testing view-to-train frame occlusions with optical flow and forward-backward consistency, allowing for robust selection of evaluable pixels.
- Correspondence Accuracy (PCK-T): Since image realism does not guarantee faithful scene correspondences—critical for downstream geometry or animation tasks—the paper proposes measuring the geometric accuracy of transferred keypoints. This is particularly stringent for non-rigid and articulated motion, allowing for a more nuanced, task-meaningful evaluation.
The iPhone Dataset
Addressing the lack of challenging, realistic data, the authors introduce the iPhone dataset—a collection of diverse, complex scenes recorded via a single smoothly moving hand-held camera (training) and cross-baseline static views for evaluation. As shown in Figure 4, this resource is designed to exhibit low EMFs, eschew teleportation, and cover a range of human, animal, and miscellaneous object motions.

Figure 4: Sampled iPhone dataset sequences; training is strictly with single-camera captures, validation leverages multi-camera still shots for robust generalization checks.
The iPhone dataset is augmented with lidar-based depth (for some scenes), as well as comprehensive keypoint annotation to support both masked image and correspondence metric evaluation.
Empirical Results and Analysis
Impact on SOTA Models
Re-evaluating SOTA DVS models under protocols with no multi-view leakage (i.e., non-teleporting camera, low EMF), and with the above metrics on both the rectified Nerfies-HyperNeRF datasets and the iPhone set, yields several strong and confronting findings:
- Performance Drop: Removal of teleportation cues leads to a measured $1$–$2$ dB drop in masked PSNR (Figure 5, top panel) on established benchmarks and a further $4$–$5$ dB drop on iPhone data with complex motion. Correspondence accuracy (PCK-T) decreases by up to 30% even when image metrics appear competitive, highlighting failures in learning realistic deformations.
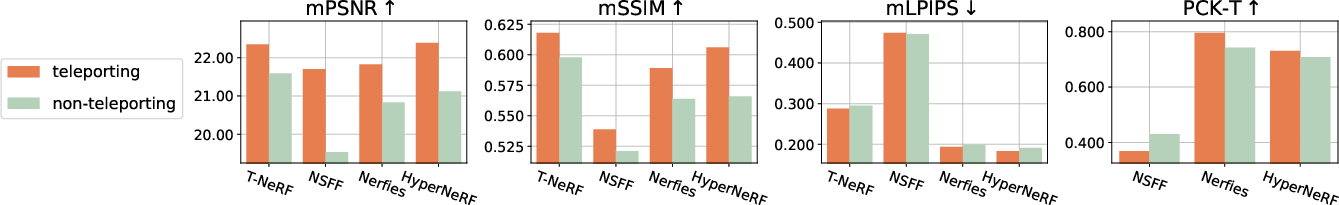
Figure 5: Transitioning from camera teleportation to realistic single-camera motion decreases synthesis quality and exposes weaknesses in learned correspondences, reinforcing the need for rigid protocols.
- Qualitative Degradation: Visual assessment shows that models, when trained truly monocularly, often generate ghosting artifacts or entirely fail to reconstruct plausible shape for challenging articulated objects and dynamic regions.
- Ablative Improvements: Adding depth supervision, background compositing, and surface regularization marginally improves results (Figure 6), but large performance gaps relative to multi-view flavored benchmarks remain.

Figure 6: Incrementally adding regularizations (+B: background, +D: depth, +S: surface sparsity) yields progressive improvements, yet does not close the gap to multi-view regimes on the iPhone dataset.
Implications and Recommendations
The empirical evidence makes it clear that—contrary to prior reports—the challenge of DVS from genuinely monocular videos is unresolved: current methods do not generalize robustly, especially in the absence of artificial multi-view cues. Reported “photo-realistic” results on legacy benchmarks are not indicative of models’ ability to recover dynamic scene geometry or motion without view leakage.
The authors thus recommend:
- All future datasets and methods should report EMFs and avoid teleportation protocols.
- Metrics must be masked using co-visibility and include correspondence accuracy.
- Further research is needed into robust regularization and generalized modeling capable of extrapolating 3D motion and structure under strictly monocular, dynamic settings.
Theoretical and Practical Implications
This work exposes the fragility of neural field-based dynamic view synthesis models to protocol artifacts and highlights the scarcity of benchmarks reflecting “in-the-wild” capture conditions. The newly introduced EMFs provide a formal axis to analyze and compare capture regimes. The co-visibility and correspondence metrics will enable the field to track meaningful progress toward systems robust to occlusion, partial views, and physically-plausible modeling. Practically, the findings caution against premature application of current SOTA DVS methods to scenarios like casual user video capture in AR or motion capture pipelines, as real-world quality and consistency is substantially lower than suggested by multi-view-aided protocols.
Conclusion
The authors of "Monocular Dynamic View Synthesis: A Reality Check" provide a rigorous diagnostic of the DVS research landscape, establishing that true monocular DVS remains unsolved once multi-view cue contamination is controlled. Their EMF taxonomy, improved evaluation metrics, and challenging iPhone dataset set the foundation for measurable, reliable progress by the community. These resources and recommendations will drive more trustworthy advances toward robust neural scene representations, ultimately necessary for casual 3D content authoring and real-world AR/VR deployment.