Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
Abstract: Modern video generative models based on diffusion models can produce very realistic clips, but they are computationally inefficient, often requiring minutes of GPU time for just a few seconds of video. This inefficiency poses a critical barrier to deploying generative video in applications that require real-time interactions, such as embodied AI and VR/AR. This paper explores a new strategy for camera-conditioned video generation of static scenes: using diffusion-based generative models to generate a sparse set of keyframes, and then synthesizing the full video through 3D reconstruction and rendering. By lifting keyframes into a 3D representation and rendering intermediate views, our approach amortizes the generation cost across hundreds of frames while enforcing geometric consistency. We further introduce a model that predicts the optimal number of keyframes for a given camera trajectory, allowing the system to adaptively allocate computation. Our final method, SRENDER, uses very sparse keyframes for simple trajectories and denser ones for complex camera motion. This results in video generation that is more than 40 times faster than the diffusion-based baseline in generating 20 seconds of video, while maintaining high visual fidelity and temporal stability, offering a practical path toward efficient and controllable video synthesis.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Efficient Camera‑Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering — Explained Simply
1. What is this paper about?
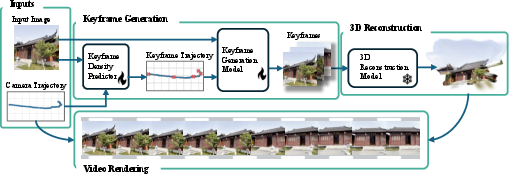
This paper shows a faster way to make realistic videos where only the camera moves and the scene itself stays still (no people or objects moving). Instead of using a heavy AI model to create every single frame, the authors generate just a few important frames (called keyframes), build a 3D model from them, and then “film” that 3D scene from the desired camera path to get the full video. Their system is called SRENDER.
2. What questions are the researchers asking?
They mainly ask:
- Can we make long, high‑quality videos much faster by generating only a small number of keyframes and filling in the rest with 3D rendering?
- How many keyframes do we actually need for a given camera path?
- Will this approach keep the video stable and consistent (no flickering or weird shape changes) while saving a lot of computation?
3. How does their method work?
In simple terms, think of making a flipbook movie. Instead of drawing every page, you carefully draw a few key pages, then use a 3D model to smoothly create the pages in between from the right angles.
Here are the main steps they follow:
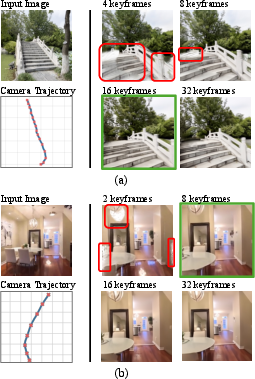
- First, an “assistant” model looks at the planned camera path (where the camera will move) and guesses how many keyframes are needed. Easy paths (slow turns, small moves) need fewer keyframes; tricky paths (big swings, close‑up to far‑away) need more.
- Next, a “diffusion” model creates those keyframes. A diffusion model is an AI that starts with noisy, blurry images and repeatedly cleans them up to produce clear pictures. Here, it uses the starting image and camera poses to create the specific views needed.
- Then, a 3D reconstruction model builds a 3D version of the scene from the keyframes. You can imagine it like placing lots of tiny colored dots in 3D space to recreate the scene (this is called 3D Gaussian Splatting). It’s fast to render and looks realistic.
- Finally, they render the full video by moving a virtual camera through that 3D scene along the requested path. This is much cheaper than generating every frame with a big diffusion model.
Because very long camera paths can slowly “drift” (small mismatches add up), they also split long videos into chunks (for example, 10‑second pieces), build a 3D scene for each piece, and align the pieces where they overlap. This keeps quality high across long videos.
4. What did they find, and why does it matter?
They tested on two public datasets (RE10K and DL3DV) and found:
- Speed: Their method is dramatically faster. On DL3DV, it was about 43× faster than a strong baseline that generates every frame. It could make a 20‑second, 30‑fps video in about 16 seconds on their hardware—near real time.
- Quality: The videos were as good or better than the baseline based on standard scores (FID and FVD; lower scores are better). Their results showed fewer flickery artifacts and more stable shapes across frames.
- Adaptive keyframes: The system learned to pick between roughly 4 and 35 keyframes for a 20‑second video, depending on how complicated the camera motion was. This smart budgeting saves time without losing detail.
- 3D beats 2D interpolation: They compared their 3D method to 2D frame interpolation (which tries to “morph” in‑between frames). The 2D methods struggled with big camera moves, causing warping or morphing. The 3D approach stayed stable and was often faster.
Why it matters: Video diffusion models are usually slow because they repeat many steps for every frame. By generating only a few frames and using 3D rendering for the rest, SRENDER slashes the compute cost while keeping the video consistent and realistic.
5. What could this change in the real world?
- Faster creative tools: Filmmakers, game designers, and artists could preview or create long camera fly‑throughs quickly and interactively.
- Better VR/AR and robotics: Systems that need real‑time or near‑real‑time video generation along specific camera paths (like virtual tours or robot vision simulations) become much more practical.
- Energy savings: Doing less heavy AI computation for every frame can save time, money, and power.
- A foundation for dynamic scenes: Right now, this method focuses on static scenes (only the camera moves). But the same idea—generate sparse keyframes and render the rest in 3D—could be extended as 4D (moving scenes) models improve.
In short, SRENDER shows that using a few smartly chosen AI‑generated views plus fast 3D rendering can make long, camera‑controlled videos much quicker to produce, without sacrificing quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to be concrete and actionable for future work.
- Dynamic scenes are not supported: extend SRENDER to handle object motion, nonrigid deformations, and time-varying geometry (i.e., true 4D reconstruction and rendering).
- Photometric stationarity is assumed: develop mechanisms to handle lighting/exposure changes, view-dependent effects, specularities, and shadows; 3DGS’s static color model limits realism under changing illumination.
- Long-range multi-view consistency remains fragile: replace heuristic temporal chunking with principled drift detection/prevention, loop-closure constraints, or 3D-aware training losses to maintain consistency over very long trajectories.
- Chunk boundaries are fixed and hand-set (≈10 s): learn chunk segmentation automatically based on consistency/coverage criteria; address seam artifacts and color/geometry discontinuities at chunk transitions.
- Keyframe density predictor outputs only a count: learn non-uniform keyframe placement along the path to maximize 3D coverage/parallax and minimize reconstruction error; jointly optimize count and positions.
- Supervision for keyframe density uses a coverage threshold with VGGT: analyze sensitivity to the threshold τ and VGGT errors, and improve robustness to pose/noise; consider uncertainty-aware supervision.
- Reliance on accurate camera trajectories is untested: quantify robustness to trajectory noise and calibration errors; integrate pose refinement or uncertainty into reconstruction/rendering.
- AnySplat reconstructs only visible content: introduce generative 3D components to plausibly hallucinate occluded or unseen regions consistent with multi-view observations.
- Domain shift in reconstruction from generated keyframes is unaddressed: evaluate and mitigate the gap between real-image-trained AnySplat and diffusion-generated keyframes (e.g., fine-tuning, co-training, synthetic augmentations).
- Pose frame alignment via least-squares affine may be inaccurate: measure alignment error and adopt pose-aware reconstruction using known camera poses; consider more expressive alignment (e.g., similarity or SE(3) with scale handling).
- Pipeline is not trained end-to-end: explore differentiable rendering and joint optimization of the keyframe generator and reconstructor to enforce multi-view geometric consistency directly.
- High-frequency detail is reduced in rendered videos: investigate higher-fidelity 3DGS (e.g., per-Gaussian BRDFs, neural textures, super-resolution rendering) and quantify the speed–quality trade-offs.
- Resolution scaling is untested: assess visual quality and performance at HD/4K; characterize scaling laws for memory, reconstruction time, and rendering speed; optimize for high-res outputs.
- Hardware generality is unclear: report memory and speed on commodity GPUs and mobile hardware; optimize kernels and data layouts for broader deployment.
- Camera-control fidelity is not quantified: add geometry-aware metrics (e.g., reprojection error, PSNR/SSIM vs. ground-truth views under target poses, depth/pose consistency) to evaluate adherence to the input trajectory.
- Dataset coverage is limited (RE10K, DL3DV): test on outdoor scenes, diverse materials (glass/metal), clutter, and highly repetitive textures to probe failure modes and generalization.
- Progressive training schedule for sparse keyframes is underexplored: ablate curriculum choices (subsampling rates, scheduling), and investigate 3D-aware attention (epipolar/camera frustum conditioning) to reduce drift at extreme sparsity.
- Context window limited to 8 frames: research memory-efficient architectures (e.g., stateful transformers, streaming attention) that scale context length without sacrificing speed.
- Uniform sampling of keyframe poses after predicting count may be suboptimal: adopt adaptive spacing driven by predicted parallax/coverage, with guarantees on reconstruction completeness.
- No explicit latency analysis for interactive/streaming use: measure end-to-end latency components (keyframe generation, reconstruction, rendering) and design incremental/online updates for real-time camera path changes.
- Color and tone consistency across chunks is not addressed: implement color calibration/harmonization across independently reconstructed chunks to avoid visible shifts.
- Failure-mode characterization is limited: systematically analyze scenes with repetitive textures, thin structures, large parallax, and textureless regions; add confidence estimates and fallback strategies (e.g., increase keyframe density or invoke test-time optimization).
- Hybrid interpolation strategies are unexplored: evaluate 3D+2D hybrids (optical-flow-guided warping between rendered frames, feature-space interpolation) for improved temporal smoothness without losing camera control.
- Use of AnySplat with unposed images despite available camera poses is inconsistent: modify reconstruction to directly consume known poses and reduce alignment uncertainty and run-time.
- Budget–quality trade-offs are not modeled: learn a quality–cost curve to allocate keyframe budgets under time/compute constraints and quantify how budget affects FID/FVD and geometry metrics.
- Comparative fairness constraints: baselines (e.g., Voyager) are limited to 5 fps; expand comparisons to equal-length/high-fps settings or provide normalized compute budgets to isolate algorithmic efficiency from implementation limits.
Practical Applications
Immediate Applications
Below are near-term, deployable use cases leveraging SRENDER’s sparse keyframe diffusion + 3D Gaussian reconstruction pipeline, adaptive keyframe budgeting, and camera-controlled rendering.
- Real-time camera-path previews for film, games, and AEC (software/entertainment/AEC)
- What: Generate fast flythroughs from concept art or a single reference image along designer-authored camera paths for previs, storyboarding, or client reviews.
- Tools/workflows: Blender/Unreal/Unity add-on (“SRENDER-Bridge”) to import an image + camera spline; one-click “Render Previs” that produces MP4s or scene-locked image sequences.
- Dependencies/assumptions: Static scenes; low–mid resolution acceptable (e.g., 256p–540p initially); GPU required; occluded regions may be incomplete; consistent intrinsics/trajectory; chunking for long paths.
- Property and product showcase videos (real estate/e-commerce/marketing)
- What: Turn a single high-quality interior photo or product shot into controlled pan/dolly/arc videos for listings and PDPs without dense neural frame generation.
- Tools/workflows: Web service/API for MLS or Shopify plugins; “Path Presets” (orbit, dolly-in, parallax sweep); “Keyframe Budgeter API” to auto-tune quality/cost.
- Dependencies/assumptions: Static scenes; more views improve coverage; lighting/view-dependent effects may be smoothed; disclosures on synthetic views for compliance.
- Embodied AI and robotics data augmentation (robotics/AI/automation)
- What: Rapidly synthesize long-viewpoint sequences from a single observation to stress-test policies and improve robustness to viewpoint changes.
- Tools/workflows: Gym/ROS wrappers to generate on-the-fly renderings along planned trajectories; curriculum that increases parallax while holding appearance fixed.
- Dependencies/assumptions: Static environments; accuracy of pose alignment; chunking to avoid long-range drift; domain gap vs. real sensors.
- AR/VR planning and interactive previews (AR/VR/software)
- What: Previsualize VR tours and AR camera paths for onboarding, kiosk, and museum experiences with real-time scrubbing along trajectories.
- Tools/workflows: Unity/Unreal XR integration; path editor widget; seed-locking for versioned revisions.
- Dependencies/assumptions: Static exhibits/rooms; headset GPU budget; scene alignment between AnySplat and runtime coordinates.
- Social media “3D photo” with controllable paths (consumer apps)
- What: Create cinematic parallax videos (beyond Ken Burns) from a single photo on mobile or cloud.
- Tools/workflows: Mobile app/SDK; path templates; auto keyframe density for smoothness vs. cost.
- Dependencies/assumptions: On-device may require model distillation/quantization; static subjects; battery/network constraints.
- Cost- and latency-aware rendering at scale (cloud MLOps/finops)
- What: Use the adaptive keyframe predictor to dynamically set compute budgets per trajectory in production (e.g., promos with varied motion complexity).
- Tools/workflows: “Keyframe Budgeter API” with SLAs; autoscaling policy using predicted keyframe count and chunking; carbon dashboards.
- Dependencies/assumptions: Predictors trained for target content domain; monitoring to catch drift/holes on out-of-distribution scenes.
- Video compression–like delivery for static scenes (media delivery/CDN)
- What: Ship sparse keyframes + 3D Gaussian scene to clients and render locally, cutting bandwidth for static-site tours and catalogs.
- Tools/workflows: “Gaussian Scene Packager” that bundles keyframes, 3DGS, and camera path; WebGL/WebGPU 3DGS viewer.
- Dependencies/assumptions: Receiver must support 3DGS rendering; standardization absent; static content only.
- Education and research demos (education/academia)
- What: Teach photogrammetry, 3DGS, and video diffusion with live notebooks showing speed/quality trade-offs and 3D vs. 2D interpolation comparisons.
- Tools/workflows: Ready-to-run Colab/VSCode notebooks; assignment kits comparing FID/FVD vs. render time; curriculum on camera geometry.
- Dependencies/assumptions: Modest GPU; dataset licensing compliance.
- Green AI reporting and optimization (energy/sustainability/enterprise)
- What: Replace dense diffusion video generation with SRENDER to reduce compute and emissions for static-scene content.
- Tools/workflows: Per-video carbon estimator; policy to auto-switch to SRENDER when camera path and content qualify as static.
- Dependencies/assumptions: Emission factors vary by hardware/region; static-scene detection gate must be accurate.
- Responsible AI safeguards for accelerated video synthesis (policy/trust & safety)
- What: Add provenance, watermarking, and disclosures when deploying faster synthetic pipelines.
- Tools/workflows: Watermark insertion during 3DGS render; C2PA manifest embedding; reviewer tooling to visualize camera/coverage maps.
- Dependencies/assumptions: Organizational policy alignment; watermark robustness; user consent and labeling norms.
Long-Term Applications
These applications may require further research, feature development (e.g., dynamics), scaling, standardization, or hardware support.
- Dynamic/4D scene generation with explicit motion (entertainment/sports/telepresence)
- What: Extend sparse keyframes + 3D reconstruction to handle deformable objects and multi-actor motion for sports replays and VFX.
- Tools/workflows: “SRENDER-4D” with motion fields; chunk-aware motion stitching; physics consistency constraints.
- Dependencies/assumptions: Robust generative 4D reconstruction; long-range consistency and loop-closure; motion capture/priors.
- Telepresence and conferencing with synthetic multi-view (communications)
- What: Transmit sparse frames + evolving 3D scene, render personalized viewpoints client-side (eye-contact correction, head motion parallax).
- Tools/workflows: WebRTC extension for 3DGS payloads; gaze-conditioned camera paths; privacy-preserving scene updates.
- Dependencies/assumptions: Latency budgets; dynamic person/scene modeling; privacy and consent; standards adoption.
- On-device AR navigation previews and route scouting (mobile/AR)
- What: Generate explorable previews from a snapshot and planned camera route to enhance wayfinding and indoor mapping.
- Tools/workflows: ARKit/ARCore integrations; on-device 3DGS rasterization; path-authoring UI.
- Dependencies/assumptions: Model compression; robust pose alignment; scene static-enough; battery/thermal limits.
- Autonomy simulation and planning (robotics/autonomous driving/drones)
- What: Use few views to synthesize long, diverse camera trajectories for planning and perception stress tests.
- Tools/workflows: CARLA/Flightmare plugin; domain randomization on lighting/textures; coverage-aware keyframe budgets.
- Dependencies/assumptions: Outdoor, large-scale generalization; dynamic agents and weather; map priors.
- Production-grade VFX/advertising at HD–4K (media/entertainment)
- What: Replace certain static or semi-static camera shots with SRENDER-backed pipelines at high resolution and photoreal detail.
- Tools/workflows: High-res 3DGS; texture/detail refinement passes; integration with Nuke/Houdini; QC tools for coverage/holes.
- Dependencies/assumptions: Reconstruction fidelity at high frequencies; scalable memory/compute; version control of seeds/paths.
- New video codec class: Gaussian Video Codec (media standards/CDN)
- What: Standardize “keyframes + 3D Gaussian scene” as a content-aware codec for static scenes.
- Tools/workflows: Bitstream spec; encoder/decoder SDKs; browser and player support; objective metrics beyond PSNR/SSIM (e.g., FVD).
- Dependencies/assumptions: Industry standardization; hardware acceleration; fallbacks for dynamic content.
- Insurance and claims triage from sparse captures (finance/insurtech)
- What: Generate explorable walkthroughs of mostly static spaces (e.g., property interiors) to aid remote assessment.
- Tools/workflows: Adjuster portal; trajectory templates targeting key vantage points; automatic uncertainty/coverage maps for risk flags.
- Dependencies/assumptions: Scene mostly static; liability and disclosure; calibration of confidence indicators.
- Healthcare and training environments (healthcare/education)
- What: Build explorable, static procedure rooms and labs from few photos for training modules and protocol rehearsal.
- Tools/workflows: LMS integration; standardized camera paths aligned with curricula; compliance logging and content provenance.
- Dependencies/assumptions: Fidelity and accuracy requirements; protected-health information handling; static-room assumption.
- Policy and standards for provenance and sustainability (public policy/standards)
- What: Establish guidelines for labeling camera-conditioned synthetic videos and reporting energy savings for Green AI initiatives.
- Tools/workflows: C2PA profiles for 3D-rendered generative media; energy-efficiency labeling akin to “Energy Star for AI.”
- Dependencies/assumptions: Cross-industry consensus; regulator engagement; interoperability with existing provenance systems.
- Research infrastructure and benchmarks for long-trajectory consistency (academia)
- What: Community benchmarks that test multi-minute, large-baseline camera control with 3D-aware metrics and cost reporting.
- Tools/workflows: Open datasets with trajectories; reference SRENDER baselines; metrics for coverage, drift, and geometry consistency.
- Dependencies/assumptions: Dataset licensing; standardized evaluation harness; compute sponsorship.
Notes on Feasibility and Common Dependencies
- Core method assumptions: static scenes, provided or authorable camera trajectories, and adequate scene coverage via adaptive keyframes; 3D reconstruction aligns with trajectory (affine alignment).
- Quality trade-offs: 3DGS renders are extremely fast but may smooth high-frequency details; chunking mitigates long-range drift.
- Compute: demonstrated real-time at 256×256 on GH200-class hardware; higher resolutions require optimization or distillation.
- Content risk and compliance: faster synthesis can raise deepfake concerns; watermarking and provenance recommended in production.
- Interoperability: packaging of keyframes + Gaussian scenes benefits from emerging standards and broad 3DGS runtime support (WebGPU/mobile).
Glossary
- 3D Gaussian Splatting (3DGS): A real-time 3D scene representation using anisotropic Gaussian primitives rendered via screen-space rasterization to achieve photorealistic views efficiently. "3DGS offers real-time rendering performance while maintaining high visual fidelity."
- 3D reconstruction: The process of recovering 3D scene geometry from images to enable consistent rendering from new camera views. "and then synthesizing the full video through 3D reconstruction and rendering."
- 3D UNet: A convolutional encoder–decoder with skip connections operating on spatiotemporal (3D) volumes, used in early video diffusion models’ latent spaces. "early video models trained 3D UNets in the latent space of 3D VAEs~\cite{blattmann2023stablevideodiffusionscaling}."
- 3D VAE: A variational autoencoder defined over 3D spatiotemporal latent representations, providing a compact space for video generation. "latent space of 3D VAEs~\cite{blattmann2023stablevideodiffusionscaling}."
- AnySplat: A feed-forward neural model that predicts 3DGS directly from multiple unposed images and estimated camera poses. "We use the pretrained AnySplat model~\cite{jiang2025anysplatfeedforward3dgaussian}, which predicts a 3D Gaussian Splatting (3DGS) representation directly from a small set of unposed images."
- Anisotropic Gaussian primitives: Direction-dependent Gaussian elements used in 3DGS to model surfaces with parameters like mean, covariance, color, and opacity. "3DGS~\cite{kerbl20233dgaussiansplattingrealtime} represents a scene using anisotropic Gaussian primitives parameterized by their mean, covariance, color, and opacity."
- Autoregressive decoding: Generating long sequences frame-by-frame conditioned on prior outputs, enabled by assigning different noise levels across frames. "including autoregressive decoding for long-range video generation with variable-length condition frames, as well as video interpolation between keyframes."
- Camera-conditioned video generation: Video synthesis controlled by explicit camera poses or trajectories to produce targeted viewpoints. "This paper explores a new strategy for camera-conditioned video generation of static scenes:"
- Classifier-free guidance: A conditioning technique for diffusion models that blends conditional and unconditional predictions without an external classifier to improve consistency. "History-Guided Video Diffusion~\cite{song2025historyguidedvideodiffusion} applies classifier-free guidance~\cite{ho2022classifier} on subsets of frames (e.g., previously denoised frames) to encourage long-range consistency."
- Context window: The number of frames jointly considered by the model to maintain coherence during generation. "The history-guided diffusion model uses a context window of 8 frames."
- Denoising diffusion model: A generative framework that learns to reverse a progressive noising process to sample data from noise. "In a standard denoising diffusion model~\cite{ho2020denoising}, a data sample is gradually perturbed through a forward noising process..."
- Differentiable rasterization: A rendering approach whose gradients can be computed, supporting learning and optimization of 3D representations. "Rendering is performed via differentiable rasterization in screen space."
- DINOv2: A self-supervised vision transformer used to extract global image features that inform scene appearance. "Scene appearance is incorporated by extracting the global feature token with a DINOv2~\cite{oquab2024dinov2learningrobustvisual} image encoder and appending it as an additional token."
- Diffusion Forcing: A video diffusion strategy assigning independent noise levels per frame to enable mixed conditioning and long-range coherence. "Diffusion Forcing~\cite{chen2024diffusion} assigns an independent noise level to each frame, allowing the model to denoise frames with different noise levels together, thus possible to mix clean history frames with partially noised to-be-generated ones at arbitrary frame positions."
- DUST3R: A geometric learning approach that inspires architectures for efficient 3D reconstruction from unposed image sets. "leveraging architectures inspired by DUST3R~\cite{wang2024dust3rgeometric3dvision}, enabling efficient 3D reconstruction even from unposed image sets~\cite{jiang2025anysplatfeedforward3dgaussian,liu2025worldmirror}."
- Flow matching: A generative modeling technique that learns continuous flows to transform noise into data as an alternative to diffusion. "current advances use diffusion-based~\cite{ho2020denoising} or flow-matching-based~\cite{lipman2022flow} techniques to generate every frame"
- Fréchet Inception Distance (FID): An image quality metric comparing feature distributions of generated and real frames. "We evaluate per-frame image quality using the Fréchet Inception Distance (FID) \cite{heusel2018ganstrainedtimescaleupdate}, which measures the distributional similarity between generated frames and ground-truth frames."
- Fréchet Video Distance (FVD): A video quality metric that evaluates both appearance and motion consistency across video distributions. "we use the Fréchet Video Distance (FVD) \cite{unterthiner2019accurategenerativemodelsvideo}, which measures both appearance and motion consistency by comparing distributions of video clips extracted from the generated and ground-truth sequences."
- History-Guided Video Diffusion (HG): A diffusion framework that conditions on previously denoised frames to enhance long-range video consistency. "Our primary baseline is the History-Guided Video Diffusion model (HG)~\cite{song2025historyguidedvideodiffusion}."
- Inverse rendering: Estimating scene parameters by matching rendered outputs to observations; contrasted with feed-forward prediction. "Instead of iterative inverse rendering, it maps multi-view features to a 3D Gaussian field, enabling fast and reliable sparse-view reconstruction."
- Keyframe density predictor: A learned module that estimates how many keyframes to generate based on camera motion and scene appearance. "We begin by using a keyframe density predictor that analyzes the camera trajectory and determines the optimal sparsity of keyframes."
- Least-squares affine transformation: A linear transformation (including translation) fitted via least-squares to align coordinate frames. "we align them by estimating a least-squares affine transformation."
- Loop-closure: Maintaining global consistency when revisiting areas in long trajectories, a challenge for generative video models. "which struggle with long-range loop-closure and maintaining multi-view consistency across large-baseline changes."
- Multi-view consistency: Geometric and photometric agreement across views from different camera poses. "have not yet achieved the visual quality, stability, or multi-view consistency seen in state-of-the-art video diffusion models."
- Novel-view controllability: The ability to generate coherent images from camera viewpoints not seen during training, controlled by explicit inputs. "Recent work has demonstrated that incorporating 3D priors into video generation improves temporal consistency and novel-view controllability"
- Parallax: Apparent displacement between viewpoints due to camera motion; higher parallax requires more keyframes for accurate reconstruction. "Simple trajectories with smooth motion or limited parallax can be reconstructed accurately from very few keyframes"
- Point cloud: A set of 3D points representing scene geometry derived from images or sensors. "we reconstruct a point cloud using VGGT~\cite{wang2025vggt}."
- Progressive training strategy: A curriculum approach that gradually increases keyframe sparsity to improve stability for large viewpoint changes. "To address this, we adopt a progressive training strategy."
- Physically-based rendering: Rendering based on physical models of light transport to produce realistic images efficiently. "using standard physically-based rendering techniques."
- Temporal chunking: Splitting long sequences into shorter overlapping segments to mitigate drift and improve reconstruction quality. "we divide the keyframes into fixed-length temporal chunks."
- Transformer: An attention-based neural architecture for sequence modeling, applied here to predict keyframe density. "We train a transformer-based keyframe density predictor."
- VGGT: Visual Geometry Grounded Transformer used to estimate camera poses and supervise 3D reconstruction from images. "we reconstruct a point cloud using VGGT~\cite{wang2025vggt}."
Collections
Sign up for free to add this paper to one or more collections.