- The paper surveys and categorizes LLM reasoning advancements across inference scaling, learning to reason, and agentic systems.
- It details architectures from standalone LLMs to multi-agent systems with unified input/output perspectives for rigorous analysis.
- It discusses evaluation challenges and data constraints, emphasizing the need for scalable, annotation-efficient training pipelines.
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Introduction
The rapid advancement in LLMs has brought about unprecedented capabilities in reasoning, a core cognitive faculty vital for logical inference, decision-making, and problem solving. This survey systematically categorizes and analyzes the evolution of LLM reasoning research along two orthogonal axes: (1) computational regimes—distinguishing between inference scaling (test-time optimization) and learning to reason (training-based capabilities)—and (2) architecture—disentangling standalone LLMs, agentic systems with tool integration, and multi-agent collaborative systems. The paper provides a unified framework integrating input (prompt construction/perception/communication) and output (action/trajectory/coordination) perspectives, and gives a detailed synthesis of learning algorithms and their interplay with reasoning processes.
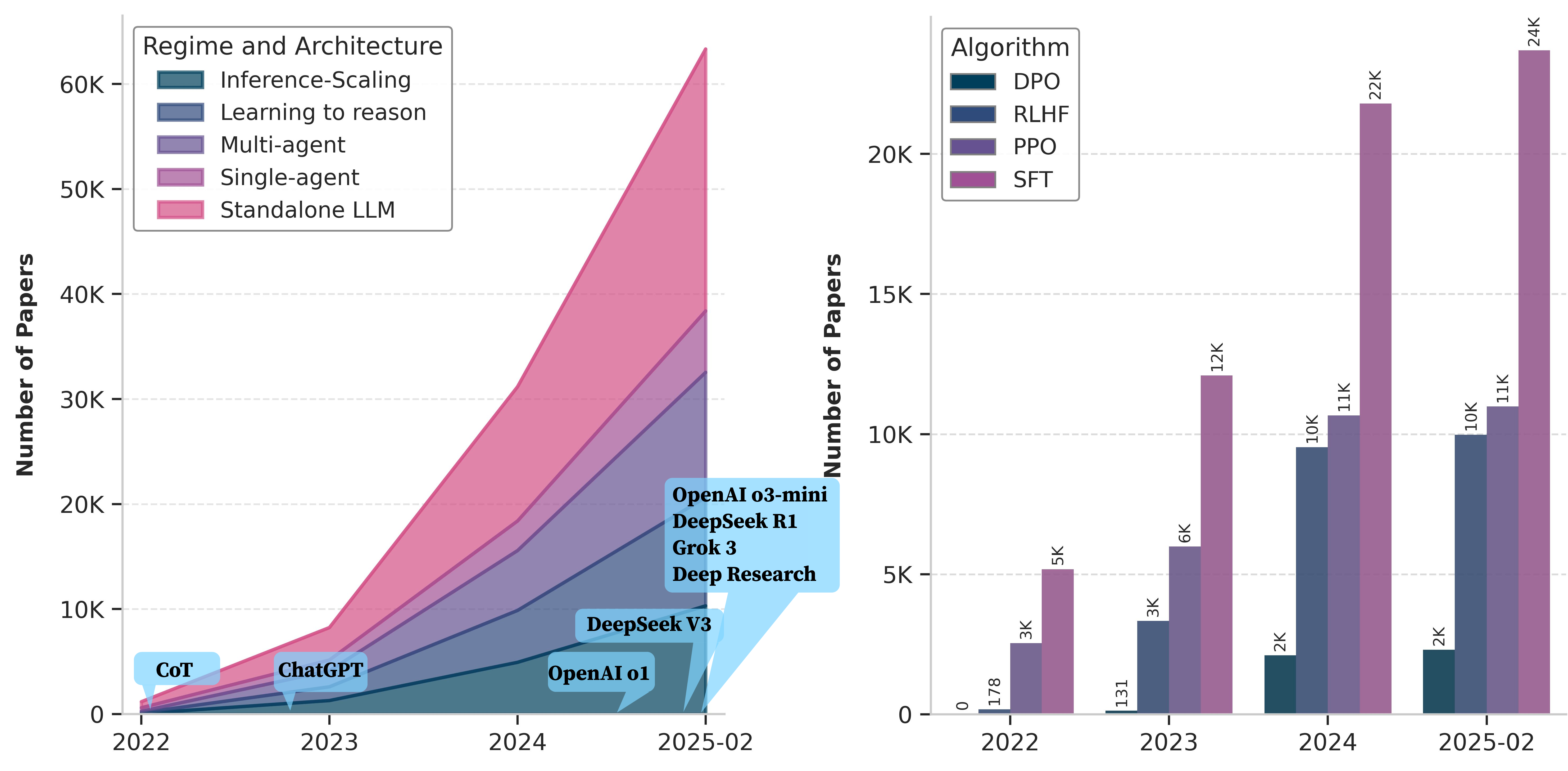
Figure 1: The exponential surge in published research on LLM reasoning post-2022, driven by the introduction of Chain-of-Thought and subsequent agentic methods.
Taxonomy of LLM Reasoning: Regimes, Architectures, Perspectives
The survey proposes a comprehensive categorization covering both computational regime and system architecture, visualized in the following schematic:
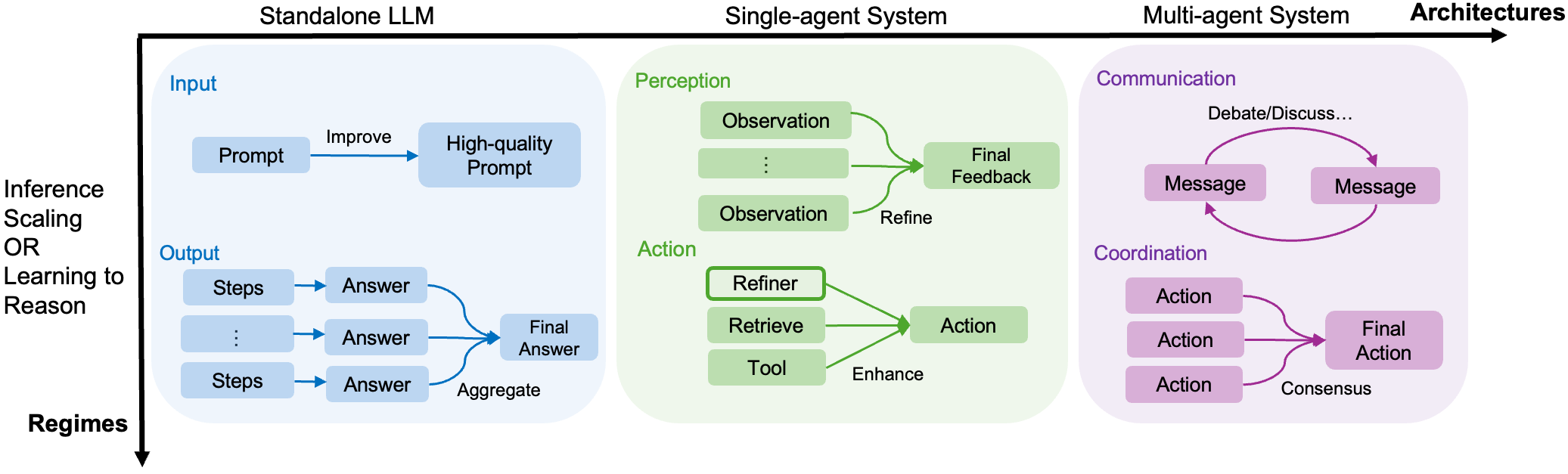
Figure 2: The paper’s categorization over reasoning regimes (inference scaling vs. learning to reason), architectures (standalone, single-agent, multi-agent), and unified perspectives (input/output or perception/action/coordination, depending on the architecture).
Regimes:
- Inference Scaling: Enhances reasoning during inference with additional compute, multi-step sampling, prompt engineering, or search, without model-parameter updates.
- Learning to Reason: Trains models explicitly for reasoning, e.g., via supervised fine-tuning, preference learning (DPO, RLHF), or RL-based credit assignment, with the aim of reducing inference-time computation.
Architectures:
- Standalone LLMs: Reasoning confined to a single model, typically via prompt and generation.
- Agentic (Single-Agent) Systems: LLMs interact with tools (retrievers, calculators, verifiers) or environments for enhanced perception and externalized reasoning steps.
- Multi-Agent Systems: Multiple agents (LLMs) communicate and coordinate to solve problems, requiring protocols for message-passing and consensus formation.
Input/Output Unified Perspectives: Any reasoning system is analyzed in terms of how input/perception/communication is presented, and how outputs/actions/coordination are executed or aggregated.
Core Components in Reasoning Systems
LLM reasoning systems are decomposed into three principal components:
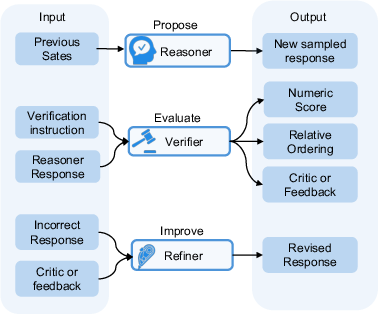
Figure 3: Reasoner proposes responses with rationales; Verifier judges the quality of response(s) with critiques or scores; Refiner revises incorrect responses, optionally using verifier feedback.
- Reasoner (Policy Model): Generates multi-step solutions or reasoning chains. Modeled as a stochastic policy π in a Markov Decision Process (MDP) abstraction.
- Verifier (Reward Model): Provides scalar (reward/classification) or generative (natural language) evaluation of solution steps, crucial for reward assignment in RL and candidate ranking at inference time.
- Refiner: Iteratively improves reasoning chains based on feedback, supporting functionalities such as self-correction, reflection, or external critique incorporation.
System Architectures for Reasoning
Design choices in architecture fundamentally impact the structure and trajectory of reasoning:
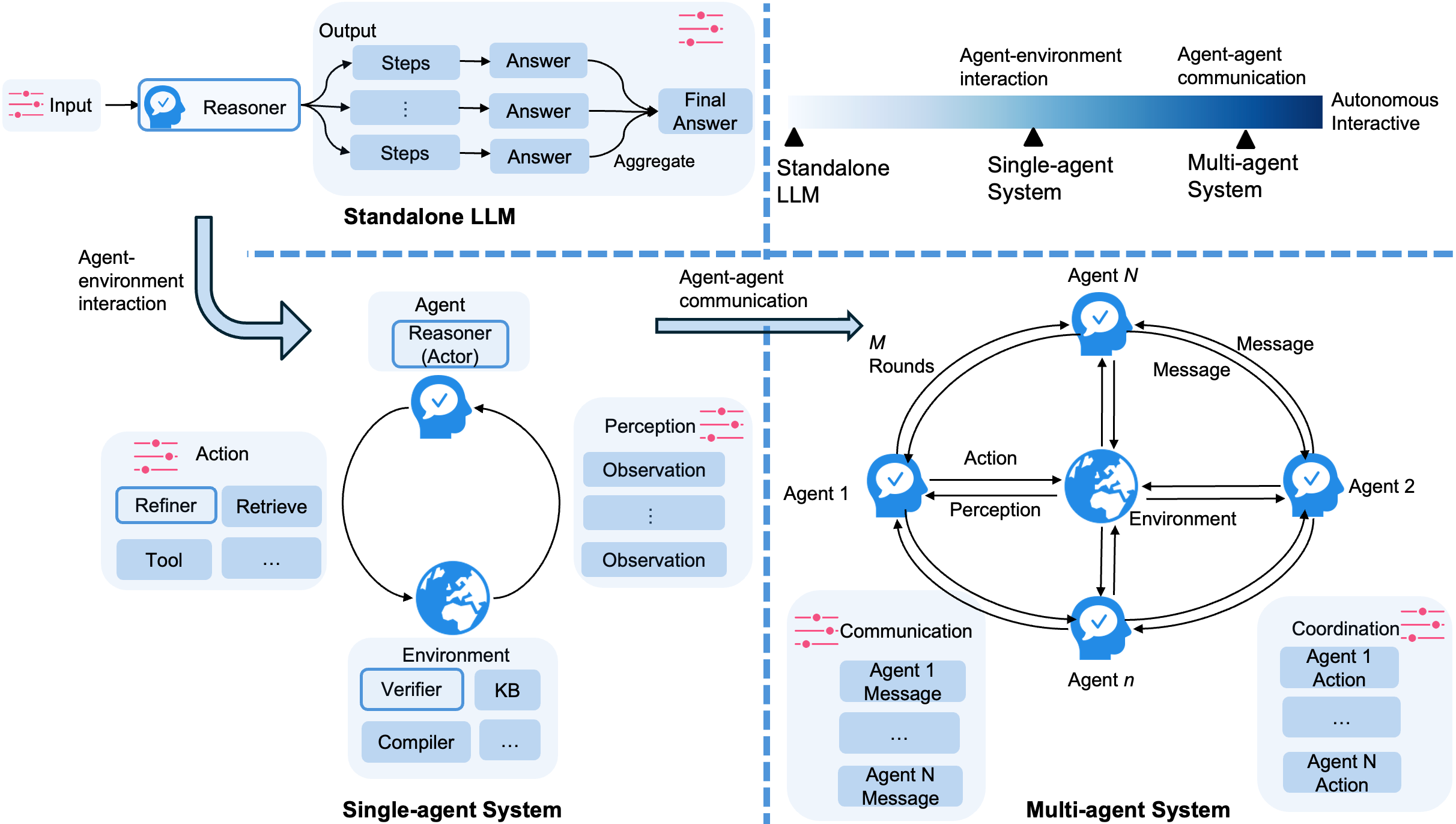
Figure 4: Standalone LLM (top), Single-Agent system (bottom left, highlighting tool/environment interaction), and Multi-Agent system (bottom right, emphasizing agent-agent message exchange and coordination logic).
- Standalone LLMs: Isolation, no external actions, self-contained reasoning. Effective for tasks amenable to prompt engineering or output ensembling.
- Single-Agent Systems: Integration with tools (retrieval, calculators, verifiers) and complex action feedback loops. Patterns include generator-evaluator, generator-critic-refiner, exemplified in recent agentic workflows (e.g., OpenAI Deep Research, Chameleon, ReAct).
- Multi-Agent Systems: Multi-stage communication (debate, consensus, voting, reconciliation) and action-aggregation mechanisms. Coordination strategies encompass both decentralized and centralized protocols—a focal point for tackling tasks requiring distributed expertise or adversarial robustness.
Reasoning Regimes: Inference Scaling vs. Learning to Reason
A key distinction in reasoning approaches lies in when and how additional computation and adaptation are applied:
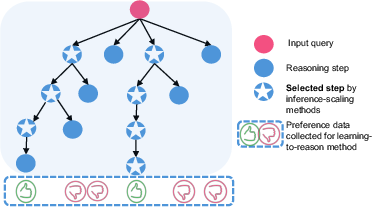
Figure 5: Illustration contrasting inference-scaling: deep candidate sampling and search for best solutions at inference, and learning-to-reason: training from both optimal and sub-optimal trajectory data, minimizing inference compute.
- Inference Scaling: Methods such as Chain-of-Thought (CoT), self-consistency, tree/graph-of-thoughts, and prompt evolution enable advanced reasoning without model updates, but entail significant inference-time compute. Notable: Test-time search/planning can yield stronger generalization than parameter scaling alone.
- Learning to Reason: SFT, DPO, PPO/GRPO, and Bandit RL approaches optimize models for reasoning during training. Self-improving models (e.g., DeepSeek-R1) have matched or outperformed inference-scaling baselines by emergently learning behaviors (reflection, trial-and-error) solely via RL or preference feedback, at a fraction of inference-cost.
Reasoning Techniques by System Design
Inference Scaling in Standalone LLMs
- Input-side: Prompt engineering (instruction/demonstration crafting, rephrasing, analogical and retrieval-based selection), automated prompt optimization (Genetic algorithms, adversarial optimization/OPRO), and many-shot in-context learning (ICL).
- Output-side: Decomposition (CoT, least-to-most, iterative and self-discovery strategies), search/planning (tree-of-thoughts, graph-of-thoughts, self-consistency sampling), and ensemble/voting or verifier-aided candidate selection.
Agentic Enhancements
- Single-Agent: Augmentation with knowledge retrieval (RAG frameworks, knowledge graphs), tool-use (code execution, calculators, web access), and advanced verifiers (PRMs for process-based evaluation, LLM-judges for critique). Notably, agentic approaches can address hallucination and facilitate dynamic reasoning beyond model parametric knowledge.
- Multi-Agent: Multi-agent communication (debate, collaborative reconciliation, group discussion), action coordination (dynamic orchestration, mixture-of-agents, meta-reasoning selection), and hybrid protocols (central node vs. distributed messaging) are employed for tasks requiring specialized skills or adversarial robustness.
Learning Algorithms and Optimization for Reasoning
- Imitation Learning: SFT on high-quality or diverse reasoning trajectories, possibly curated via distillation from stronger models or enriched with reflection/self-correction steps.
- Preference Learning: DPO and variants directly align models to human or model-derived preferences with simple classification objectives, alleviating RL instability/bias.
- Reinforcement Learning: PPO, GRPO, RLOO, Expert Iteration, and process/outcome RL architectures, with action granularity (token, step, response) reflecting MDP abstraction.
- Verifier Learning: Outcome/process reward models, generative verifiers, and discriminative-generative hybrids trained by SFT, DPO, or RL for annotation-efficient and generalizable trajectory assessment.
Emergent Trends and Domain-Specific Reasoners
- The community has shifted from inference scaling (prompt-level reasoning) to learning-to-reason (training general-purpose and domain-specialized reasoners), concurrently transitioning from standalone to agentic and multi-agent architectures for complex compositional tasks.
- Domain-specific reasoning, particularly in mathematics (MetaMath, DeepSeek-Math, AlphaProof), code generation/repair (DeepSeek-R1, o3, AlphaCode), tabular reasoning, and tool-augmented scientific reasoning, leverage specialized data, RL signals, and external toolchains for superior performance and reliability.
- The survey emphasizes the limitation of data as a bottleneck: the scarcity of high-quality, problem-diverse questions and outcome/process annotations constrains further progress, particularly in RL scaling and process-based credit assignment.
- Theoretical advances in understanding reasoning (ICL, CoT expressiveness), empirical benchmarking, and advances in evaluation accuracy and faithfulness remain open areas of active research, as LLMs often generate unfaithful or non-generalizable reasoning chains even with high final solution accuracy.
Assessment and Open Challenges
- Evaluation: Outcome-based metrics are insufficient for validating reasoning fidelity. Faithful process-level evaluation, automatic critique generation, and scalable annotation-efficient reward modeling remain largely unsolved.
- Understanding Mechanisms: Empirical and formal analyses (neurosymbolic, metacognitive, and process-level diagnostics) are needed to understand implicit vs. explicit reasoning, recurrent errors in reflection/self-correct, and transferability of learned reasoning procedures.
- Data Scale and Diversity: New strategies for scalable trajectory collection, automated process supervision, and simulation-rich training pipelines are needed for advancing domain-agnostic and domain-specific reasoning.
- Automated Workflow/Agent Design: Progress in zero-supervision multi-agent design and meta-level planning architectures is anticipated as reasoning systems continue to grow in complexity and autonomy.
Conclusion
This survey delivers an authoritative synthesis of the current landscape and open questions in LLM-based reasoning, sharply distinguishing between inference scaling and learning-to-reason paradigms, and providing a systematized analysis over architectures, algorithms, and unified perspectives. The field is transitioning to cost-aware, dynamically adaptive, and agent-driven reasoning paradigms, with significant implications for the development of robust, generalizable, and practically deployable AI systems. Critical advances will depend on addressing evaluation robustness, process fidelity, and scalable, annotation-efficient supervision to underpin the next generation of LLM reasoners.